w查看系统负载
[root@localhost ~]# w
21:00:26 up 3 days, 10:09, 2 users, load average: 0.24, 0.07, 0.06 #当前时间,启动3 days, 2 个用户登录
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
root tty1 六21 3days 0.10s 0.10s -bash
root pts/0 192.168.224.1 21:00 2.00s 1.39s 0.98s w
[root@localhost ~]# date
2018年 08月 22日 星期三 21:01:39 CST
[root@localhost ~]# uptime
21:10:01 up 3 days, 10:18, 2 users, load average: 0.00, 0.01, 0.05
USER (用户) TTY (登录的终端) FROM(从哪里登录来) LOGIN@ IDLE JCPU PCPU WHAT
root pts/0 (网络远程登录就是pts/0,pts/1,终端登录则是tty1...) 192.168.1.101 20:38 7.00s 0.08s 0.01s w
load average: 0.24, 0.07, 0.06 (重点看系统负载) 1min 5min 15min 的进程数 1min的进程数与逻辑cpu数量相当最好
[root@localhost ~]# cat /proc/cpuinfo
processor : 0 #这个数字是0,代表有1颗cpu,如果是1那就有2颗,以此类推
vendor_id : GenuineIntel
cpu family : 6
model : 37
model name : Intel(R) Core(TM) i3 CPU M 350 @ 2.27GHz
...
vmstat:查看cpu,内存,虚拟磁盘,io磁盘,system系统进程等瓶颈。
[root@localhost ~]# vmstat 1 5(1代表每一秒钟显示1次,显示5秒钟后结束) #ctrl c 终止
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
#run(等待cpu进程)swpd(内存变化)si so(swap in out内存)bi bo(磁盘in out内存)us(资源占用cup)wa(等待cpu)
2 0 0 737072 2076 141924 0 0 19 3 54 58 0 0 100 0 0
0 0 0 737056 2076 141924 0 0 0 0 49 46 0 0 100 0 0
0 0 0 737056 2076 141924 0 0 0 0 52 50 0 0 100 0 0
0 0 0 737056 2076 141924 0 0 0 0 46 38 0 0 100 0 0
0 0 0 737056 2076 141924 0 0 0 0 50 44 0 0 100 0 0
关注r、b,swpd、si、so、bi、bo、us、wa
r:run。表示运行或者等待cpu时间片的进程。我们不要以为这些等待的进程没有运行,某一时刻1个cpu只能有一个进程占用,其他进程只能排队,而此时这些排队的进程仍然处于运行状态,如果这个数值长期大于服务器cpu的个数,则说明cpu资源不够用。
b:block。有多少个进程在等待。
swpd:如果数字不变,没有关系。如果数字持续变化,则说明交换分区和内存在频繁的交换数据,这说明我们的内存不够了。
si,so:它与swpd有关,si,i表示in,它表示有多少kb的数据从swap进入到内存中。。so表示out。它表示有多少kb的数据从内存进入到swap中。这里面我们有参照物,这就是内存,in表示进去的,out表示出来的。
bi、bo:bi表示从磁盘中出来,进入到内存中,也是读的数据量是多少。bo,写的数据量。这两个数据如果很大,这说明磁盘正在频繁读写,磁盘相对于内存和cpu会慢很多,如果很多的数据需要读写,这样对造成b列增加,会有更多的进程在等待磁盘。
us:表示用户级别的资源占用cup的百分比。这个数字不会超过100。如果这个长时间数字大于50,这说明系统的资源不够。
wa:等待cpu的百分比。如果这一列很大,则表示cpu不够用。
top:查看进程使用资源情况
[root@localhost ~]# top
top - 21:41:10 up 3 days, 10:49, 2 users, load average: 0.06, 0.03, 0.05
Tasks: 98 total, 1 running, 97 sleeping, 0 stopped, 0 zombie
# total(任务总和),2 running(运行),82 sleeping(休眠),0 stopped(停止),0 zombie(僵尸进程,主进程意外停止,子进程还在)
%Cpu(s): 0.0 us, 0.3 sy, 0.0 ni, 99.5 id, 0.0 wa, 0.0 hi, 0.2 si, 0.0 st
KiB Mem : 997980 total, 695104 free, 137912 used, 164964 buff/cache
KiB Swap: 2097148 total, 2097148 free, 0 used. 683388 avail MemPID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
3771 root 20 0 158800 5568 4224 S 0.7 0.6 0:02.11 sshd
499 root 20 0 298928 6280 4932 S 0.3 0.6 10:44.25 vmtoolsd
3819 root 20 0 161840 2176 1548 R 0.3 0.2 0:00.49 top
1 root 20 0 193460 6436 4084 S 0.0 0.6 0:22.85 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:00.67 kthreadd
...
%Cpu(s): 0.0 us(在60%以上,需注意。会使电脑寿命大幅减小), 0.3 sy, 0.0 ni, 99.0 id, 0.0 wa, 0.0 hi, 0.3 si, 0.0 st(被偷走的cpu百分比,如果服务器做了虚拟化,他会有一些子机,这样可能会偷走一部分cpu)
KiB Mem(物理内存) : 1012376 total(内存总和), 750428 free(内存剩余), 130844 used(使用多少), 131104 buff/cache(我们一般关注物理分区)
KiB Swap(交换分区): 2097148 total, 2097148 free, 0 used. 727448 avail Mem
*我们的系统负载值可以很高,但是我们的us很低,这是可以的。但是大部分情况下,我们的us很高,我们的系统负载也一定会很高,因为我们某一些进程,它占用cpu很高,他势必会造成CPU很忙,cpu很忙,那其他的进程就会排队,一排队,那系统负载肯定会增高*
%MEN是内存。
RES是物理内存大小,单位是kb
如果我们想按照内存占用大小来排序,就按M(大写),如果想切回cpu排序,就按P(大写)。
我们还可以按数字1,查看指定cpu。默认是看cpu的平均值,按1可以来回切换。
按字母-c可以查看具体的进程命令全局的路径,按-bn1可以静态显示所有进程信息,这个可以在我们写脚本的时候用,按字母q退出。
我们也可以关注一下pid,如果我们想结束某一个进程,只要输入kill+pid 号,就可以结束它。
sar:全面分析系统状态的命令。
被称为linux系统中的瑞士军刀,它的功能非常复杂,如果系统中没有这个命令,我们就需要用
安装完成后,我们运行这条命令
yum install -y sysstat
[root@localhost ~]# sar
无法打开 /var/log/sa/sa06: 没有那个文件或目录
发现它无法运行,这是因为如果sar命令不加具体的选项或者参数,他默认会去调用系统里边保留的一个历史文件。
[root@localhost ~]# ls /var/log/sa
sa06
这个目录就是sar生成的历史文件所在的目录,sar有一个特性,它每十分钟就会把系统状态过滤一遍,保存在文件里,而这个文件就存在在这个目录中。如果想用sar这条命令,则要加参数。
1.比如我们要看网卡流量
[root@localhost ~]# sar -n DEV 1 3(它的用法和vmstat类似,1代表每隔1秒显示1次,3代表显示三次。)
Linux 3.10.0-693.el7.x86_64 (localhost.localdomain) 2018年03月06日 _x8664 (1 CPU)
22时52分25秒 IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s
22时52分26秒 lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00
22时52分26秒 ens33 0.99 0.99 0.06 0.18 0.00 0.00 0.00
22时52分26秒 IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s
22时52分27秒 lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00
22时52分27秒 ens33 1.01 1.01 0.06 0.39 0.00 0.00 0.00
22时52分27秒 IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s
22时52分28秒 lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00
22时52分28秒 ens33 2.02 1.01 1.25 0.39 0.00 0.00 0.00
平均时间: IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s
平均时间: lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00
平均时间: ens33 1.34 1.00 0.45 0.32 0.00 0.00 0.00
它的输出有两个网卡,一个是lo,另一个是ens33,因为我的系统有两个网卡。第一列是时间。第二列是网卡的名字,rxpck/s是每秒接收到的数据包,txpck/s是每秒发送出去的数据包。rxKB/s是接收到的数据量,txKB/s是发送的数据量,单位都是KB。我们着重看这几个就可以了。
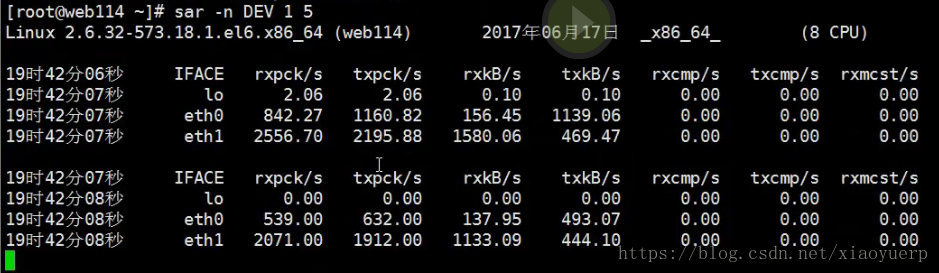
rxpck/s:如果有一些你不想要的东西向你的网卡发送很多的数据包,他发送很多数据包我们就要接受很多的数据包,数据包量很大的情况下我们的网卡承担不了,最终导致网络堵塞,网站不能打开。如果数据包是几千个,是正常的,如果是上万的,我们就要注意我们的网卡是否被***了。
如果我们要查看相关历史,加一个选项-f指定一个文件,/var/log/sa/saxx(xx表示文件日期的两位数字),这个文件就是在这个目录下的一个文件,因为我们刚刚装上这个工具,所以只生成了当天的文件,这个文件名字是有规律的是哪一天,他就以那一天的数字作为结尾,这样我们就可以查看历史数据,这个目录下的文件我们可以保留一个月。
我们也可以查看系统负载
[root@localhost ~]# sar -q 1 3
Linux 3.10.0-693.el7.x86_64 (localhost.localdomain) 2018年03月06日 _x8664 (1 CPU)
23时20分26秒 runq-sz plist-sz ldavg-1 ldavg-5 ldavg-15 blocked
23时20分27秒 1 101 0.00 0.01 0.05 0
23时20分28秒 1 101 0.00 0.01 0.05 0
23时20分29秒 1 101 0.00 0.01 0.05 0
平均时间: 1 101 0.00 0.01 0.05 0
查看系统负载我们经常是查看历史数据
[root@localhost ~]# sar -q -f /var/log/sa/saxx
查看磁盘
[root@localhost ~]# sar -b 1 3
Linux 3.10.0-693.el7.x86_64 (localhost.localdomain) 2018年03月06日 _x8664 (1 CPU)
23时34分40秒 tps rtps wtps bread/s bwrtn/s
23时34分41秒 0.00 0.00 0.00 0.00 0.00
23时34分42秒 0.00 0.00 0.00 0.00 0.00
23时34分43秒 0.00 0.00 0.00 0.00 0.00
平均时间: 0.00 0.00 0.00 0.00 0.00
查看磁盘的历史数据
[root@localhost ~]# sar -b -f /var/log/sa/saxx
有关sar的所有的历史文件,我们都可以通过-f /var/log/sa/saxx来查看,只要在sar后面加上具体的参数,文件后面的具体日期就可以。
在/var/log/sa/这个目录下不仅有saxx,还有一个sarxx,这个目录不会当天生成,而是会在第二天生成,他们的区别在于sa是一个二进制文件,不能用cat查看,只能用sar -f去加载查看它,而sarxx是可以用cat查看的。
监控网卡流量的命令还有一个nload,但是系统中没有这个命令,所以我们要安装这个包,但是安装前我们要先安装epel-releaes这个包。
安装完后我们直接运行这个命令,运行后就会出现一个动态的显示网卡实时速度的页面。
Device ens33 [192.168.1.105] (1/2):当前的网卡命和IP,按方向键可以切换出第二个网卡。
Incoming:
Curr: 2.09 kBit/s(当前值)
Avg: 4.87 kBit/s(平均值)
Min: 944.00 Bit/s(最小值)
Max: 49.74 kBit/s(最大值)
Ttl: 8.06 MByteOutgoing:
Curr: 9.77 kBit/s(当前值)
Avg: 9.16 kBit/s(平均值)
Min: 3.52 kBit/s最小值)
Max: 10.48 kBit/s(最大值)
Ttl: 719.61 kByte如果出现***情况,进入的流量就会很大,那么curr(当前值)就会很大,所以我们要多注意。
监控io性能(磁盘性能监控)
在日常运维的工作中,我们不仅要关注cpu,内存之外,磁盘的io也是重要指标之一。有时候cpu和内存都有剩余,但是系统的负载还是很高,用vmstat查看发现b列或者wa列比较大,那说明系统磁盘有瓶颈,那我们就要更详细的去查看磁盘的状态。
我们可以用iostat -x来看硬盘的状态,这里面有一个非常重要的选项,%util^C
[root@localhost ~]# iostat -x 1 3
Linux 3.10.0-693.el7.x86_64 (localhost.localdomain) 2018年03月07日 _x8664 (1 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
0.14 0.00 0.28 0.25 0.00 99.32
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.10 0.95 0.42 35.04 10.54 66.73 0.05 40.20 12.07 103.35 4.07 0.56
这个指标首先是一个百分比,它的含义是io等待,磁盘使用有多少时间占用cpu的,那我们的cup有一部分时间是交给进程进行处理的,计算的,那也有一部分是等待磁盘读写的,磁盘要读写数据,cpu是需要时间等待的,那么的时间比就是%util。
如果这个百分比很大,已经达到了50%~60%,这说明磁盘io很差了,说明它非常的忙,这个数值很大,说明磁盘的读(rkB/s)和写(wkB/s)这两列也很大,如果这两列不大,但是%util很大,就说明我们的硬盘有问题,有些故障,如果硬盘很慢,肯定会影响系统的性能。
如果我们发现磁盘io很忙,我很想知道是哪一个进程在频繁读写呢?这时候我们输入命令iotop,如果没有这条命令,那我们就直接安装iotop。这条命令和top命令相似,也是动态显示
[root@localhost ~]# iotop
Total DISK READ : 0.00 B/s | Total DISK WRITE : 0.00 B/s
Actual DISK READ: 0.00 B/s | Actual DISK WRITE: 0.00 B/s
TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND
1715 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.02 % [kworker/0:1]
1 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % systemd --switched-root --system --deserialize 21
2 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [kthreadd]
在io列中,排位靠前的就是使用io频繁的进程。
free:查看内存使用情况的命令
[root@localhost ~]# free -h
total used free shared buff/cache available
Mem: 988M 130M 715M 6.7M 142M 700M
Swap: 2.0G 0B 2.0G
它是由三行组成,第一行是说明。第二行是内存使用情况,第三行是交换分区使用情况。我们也可以使用参数-h,给他加上合适的单位。我们关注的是第二行,内存的使用情况。
第一列 total内存总大小。
第二列 used:使用了多少。
第三列 free:空闲了多少。
第四列 shared:共享了多少。
第五列 buff/cache :缓冲和缓存。
这里有一个问题,我们的used(使用)和free(空闲)之和不等于total(总和),这是为什么呢?这是因为linux系统他会把你的内存先预分配一部分出来给buff(缓冲)/cache(缓存),这两个词看似相近,但是他俩是不同的概念。
cache:我们现在有一个数据,要从磁盘中读出来,交给cpu去运算,磁盘到cpu要经过内存,由于磁盘和cpu的速度差距很大,所以我们中间有一个内存设备,为了就是让这两者的速度有一个缓和,所以中间要经过一个内存到cpu,这个内存就是cache。 磁盘-->内存(cache)-->cpu
buff:cpu将数据计算完后要想把它存到磁盘中去,由于cpu速度快而磁盘速度慢,入股想直接写到磁盘中去速度会很慢,这样会拖慢cpu的工作效率,所以cpu就先将数据放到内存中去(buff),然后再放入磁盘中去。 cpu-->内存(buff)-->磁盘第六列 available:可得到的剩余物理内存。它是free和buff/cache 剩余部分之和。我们真正要查看的就是这项。
ps:监控系统状态
ps aux:静态的列出系统所以进程
[root@localhost ~]# ps aux |head -4
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.6 128164 6820 ? Ss 20:34 0:02 /usr/lib/systemd/systemd --switched-root --system --deserialize
root 2 0.0 0.0 0 0 ? S 20:34 0:00 [kthreadd]
root 3 0.0 0.0 0 0 ? S 20:34 0:00 [ksoftirqd/0]
第一列 user:进程的运行用户
第二列 pid:进程id。这个在我们杀死进程的时候可以用到,kill+pid。
第三列 %CPU:cpu百分比
第四列 %MEM :内存百分比
第五列 VSZ:虚拟内存
第六列 RSS :物理内存
第七列 TTY:在哪个TTY上。
第八列 STAT:进程状态。这也是我们需要关注的一项。
进程的状态有如下几种:
D :不能中断的进程,这样会造成系统负载很高,这说明D进程会不断使用cpu。这个很少见。
R:正在跑的进程。
S:休眠的进程,但是有一种情况,一个程序正在运行,但是我们查看的时候他还在处S的状态,这时因为他虽然在运行,但是不是不停的运行、而是某一个时刻抓一下,所以他占用cpu的时间很短,它运行完的会后就处于S的状态,这种进程基本不会耗费cpu的资源。
S+:前台进程。
T:暂停的进程。
[root@localhost ~]# ps aux |grep vmstat
root 1501 0.0 0.1 148316 1348 pts/0 T 23:08 0:00 vmstat 1
这就说明进程被暂停了,这时候他就没有在运行。
Z:僵尸进程。如果有僵尸进程,我们就要想办法杀死它。
<:高优先级进程。cpu优先运行这个进程。
N:低优先级进程。cpu会延后运行这个进程。
L:内存中被锁了内存分页的。
s:主进程。
|:多线程进程。
第九列 START:什么时候启动的
第十列 TIME:启动多久了
第十一列COMMAND:命令
如果我们想产看系统中某一个程序是否运行,可以用管道符加grep,比如我们先要看nginx这个程序是否运行
[root@localhost ~]# ps aux |grep nginx
root 1462 0.0 0.0 112676 984 pts/0 R+ 22:47 0:00 grep --color=auto nginx
这样就可以实现了。
netstat:查看网络状态 yum install -y net-tools
linux作为服务器的一种操作系统,这个服务器会有很多的服务,服务他往往是和客户端相互通信的,所以也就意味着他有监听端口,要有对外通信端口,netstat这个命令就是监听TCP/IP通信的状态,比如说我们要安装一个服务,有了服务,我们就要监听一个端口。
监听端口:正常情况下一台机器是没有端口监听的,没有端口监听,他就没法和其他机器通信,如果想提服务,如果让其他人访问你的服务器,你的网站,就需要监听一个端口,他把端口放开,打开一个洞,就好比在网卡打开一个洞,你的远程设备想办法和我们的这个小洞相连,你的数据从这个小洞进入到我们的网卡,我们的服务器中,相互的去通信。
netstat -lnp:查看监听端口
[root@localhost ~]# netstat -lnp
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:22 0.0.0.0: LISTEN 889/sshd
tcp 0 0 127.0.0.1:25 0.0.0.0: LISTEN 991/master
tcp6 0 0 :::22 ::: LISTEN 889/sshd
tcp6 0 0 ::1:25 ::: LISTEN 991/master
udp 0 0 0.0.0.0:68 0.0.0.0: 694/dhclient
udp 0 0 0.0.0.0:47393 0.0.0.0: 694/dhclient
udp 0 0 127.0.0.1:323 0.0.0.0: 547/chronyd
udp6 0 0 :::10353 ::: 694/dhclient
udp6 0 0 ::1:323 ::: 547/chronyd
raw6 0 0 :::58 ::: 7 570/NetworkManager
我们着重要注意以上这些内容,因为我们以后要添加的一些服务,如果想看这些服务是否正常启动,就会用到条命令,也可以用ps查看进程。
netstat -an:查看TCP/IP状态
查看所有的连接的状态,这里面会牵扯到TCP/IP的三次握手和四次挥手。
netstat-lntp:只查看tcp,不包含socket
查看所有状态数字的小技巧
[root@localhost ~]# netstat -an | awk '/^tcp/ {++sta[$NF]} END {for(key in sta) print key,"\t",sta[key]}'
LISTEN 4 (监听)
ESTABLISHED 2(保持连接)这个数字如果很大,说明你的系统很忙,网站并发连接数(并发连接数的概念就是同一时间有多少个客户端在连接你)。这有这个数字是在真正通信的。通常情况下,这个数字在1千以内。
ss -an:它和netstat类似,都可以查看TCP/IP状态,如果只想产看被监听的端口,我们可以接grep。
[root@localhost ~]# ss -an | grep -i listen |head -5
u_str LISTEN 0 128 /var/run/dbus/system_bus_socket 13578 0
u_str LISTEN 0 100 private/rewrite 17480 0
u_str LISTEN 0 100 private/bounce 17483 0
u_str LISTEN 0 100 private/defer 17486 0
u_str LISTEN 0 100 private/trace 17489 * 0
但是这个有一个缺点,他不会显示进程名字,但是netstat -lntp可以显示进程名字。
linux下抓包
有时候我们的网站会受到***,网卡流量异常,进入的包会有很多。这时候我们想知道都有哪些包进来,这时候我们就用tcpdump这个抓包工具来查看。
这个命令如果没有,我们就用yum来安装一下。
简单的抓包命令:tcpdump -nn -i ens33(由于我们设备名字特殊,所以我们要指定网卡名。)
[root@localhost ~]# tcpdump -nn -i ens33
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on ens33, link-type EN10MB (Ethernet), capture size 262144 bytes
时间 IP 源IP .源端口 >是到哪里去 目标源.目标端口 数据包信息
20:47:43.162758 IP 192.168.1.103.50895 > 192.168.1.105.22: Flags [.], ack 196, win 16246, length 0
20:47:43.163198 IP 192.168.1.105.22 > 192.168.1.103.50895: Flags [P.], seq 196:472, ack 1, win 255, length 276
20:47:43.163556 IP 192.168.1.105.22 > 192.168.1.103.50895: Flags [P.], seq 472:636, ack 1, win 255, length 164
20:47:43.163735 IP 192.168.1.103.50895 > 192.168.1.105.22: Flags [.], ack 636, win 16136, length 0
20:47:43.163914 IP 192.168.1.105.22 > 192.168.1.103.50895: Flags [P.], seq 636:896, ack 1, win 255, length 260
20:47:43.164169 IP 192.168.1.105.22 > 192.168.1.103.50895: Flags [P.], seq 896:1060, ack 1, win 255, length 164
我们重点关注的是源IP.源端口到目标源.目标端口。数据流向。
21:52:03.147158 IP 192.168.1.103.50895 > 192.168.1.105.22: Flags [.], ack 196, win 16147, length 0。
有时候我们也要注意length。有时候我们会看到一些奇怪的数据包,默认很多都是tcp的,有时候我们也有可能看到udp的包,如果出现udp的包很有可能你就被***了。有一种DDOS***,叫udp flood洪水***。如果遇到这种洪水***,我们只能借助于专业的防***设备或者是服务。
其中-nn中的第一个n代表你的IP,用数字的形式显示出来,如果不显示,则会显示主机名。
[root@localhost ~]# tcpdump -i ens33
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on ens33, link-type EN10MB (Ethernet), capture size 262144 bytes
20:51:19.244423 IP localhost.localdomain.ssh > 192.168.1.103.50895: Flags [P.], seq 504196553:504196749, ack 3367907909, win 255, length 196
20:51:19.244725 IP 192.168.1.103.50895 > localhost.localdomain.ssh: Flags [.], ack 196, win 16207, length 0
20:51:19.246481 IP localhost.localdomain.43235 > cache4-dlcity.domain: 13573+ PTR? 103.1.168.192.in-addr.arpa. (44)
20:51:19.248896 IP cache4-dlcity.domain > localhost.localdomain.43235: 13573 NXDomain 0/1/0 (99)
20:51:19.250229 IP localhost.localdomain.58113 > cache4-dlcity.domain: 50792+ PTR? 105.1.168.192.in-addr.arpa. (44)
20:51:19.251873 IP cache4-dlcity.domain > localhost.localdomain.58113: 50792 NXDomain 0/1/0 (99)
20:51:19.252153 IP localhost.localdomain.57475 > cache4-dlcity.domain: 15278+ PTR? 38.69.96.202.in-addr.arpa. (43)
ocalhost.localdomain这就是主机名,但是在网上我们并不知道他是谁,所以还是要加上-nn比较直观。
.ssh这时ssh服务的端口,22,如果我们知道还好,如果我们不知道,那么我们就不知道这个端口是哪个数字。
所以我们加上nn,就会以数字的形式显示端口号。(第二个n是端口号)
这台设备没有跑什么服务,只是ssh远程连接的,所以在我们抓包的时候看到的很多包都是从22端口出去的。
tcpdmup -nn prot 端口:指定端口
因为我们在抓包的时候会抓到很多的端口,因为有些端口我们不需要看,所以我们既要查看指定端口。
tcpdump -nn -i ens33 port 22:指网卡和端口
tcpdump -nn -i ens33 port 22 and host 192.168.1.105:我们还可以加条件,指定IP的包。比如我们指定了192.168.1.105这个IP的包。
还有一种情况,我们指定数据包,只抓100个,而且我想把它存到一个文件中去
[root@localhost ~]# tcpdump -nn -i ens33 -c 100 -w /tmp/llt.cap
tcpdump: listening on ens33, link-type EN10MB (Ethernet), capture size 262144 bytes
100 packets captured
100 packets received by filter
0 packets dropped by kernel
这样100个包就抓完了。
.cap这个文件实际上是就是从网卡里捕获的数据包,这个包中含有源IP,目标IP,通讯的数据包,数据内容等很多的信息。所以不能用cat去查看。如果要查看,我们要用tcpdump -r(read读)+文件的路径+文件名。他显示的也是数据流。而我-w写入的是真真正正的数据包,这是我们要区分的。然后我们查看一下抓好的包
[root@localhost ~]# tcpdump -r /tmp/llt1.cap
reading from file /tmp/llt1.cap, link-type EN10MB (Ethernet)
22:43:46.835843 IP localhost.localdomain.ssh > 192.168.1.103.50895: Flags [P.], seq 511436009:511436141, ack 3367974121, win 255, length 132
22:43:46.836126 IP 192.168.1.103.50895 > localhost.localdomain.ssh: Flags [.], ack 132, win 16314, length 0
22:43:47.292696 IP 192.168.1.100.39909 > 239.255.255.250.ssdp: UDP, length 268
22:43:47.344078 IP 192.168.1.100.39909 > 239.255.255.250.ssdp: UDP, length 277
22:43:47.400646 IP 192.168.1.100.39909 > 239.255.255.250.ssdp: UDP, length 324
22:43:47.442222 IP 192.168.1.100.39909 > 239.255.255.250.ssdp: UDP, length 322
22:43:47.492553 IP 192.168.1.100.39909 > 239.255.255.250.ssdp: UDP, length 334
22:43:47.542970 IP 192.168.1.100.39909 > 239.255.255.250.ssdp: UDP, length 332
22:43:47.795308 IP 192.168.1.103.53665 > 61.135.169.125.https: Flags [R.], seq 672714496, ack 3686534326, win 0, length 0
22:43:47.796094 IP 192.168.1.100.39909 > 239.255.255.250.ssdp: UDP, length 268
wireshark:抓包工具,它的作用和tcpdmup类似。wireshark这个包有一个命名,tshark。他有一个很实用的用法,用这个命令可以查看你指定网卡80端口的一个wed访问情况。
[root@localhost ~]# tshark -n -t a -R http.request -T fields -e "frame.time" -e "ip.src" -e "http.host" -e " http.request.metod" -e "http.request.uri"
这个类似于wed的访问日志,我们可以很清晰的发现在这个往卡上,有什么ip来访问网站
linux网络相关
ifconfig:查看网卡命令,这个命令在centos6中是默认安装的,在centos7中我们需要安装net-tools。
[root@localhost ~]# ifconfig
ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.1.105 netmask 255.255.255.0 broadcast 192.168.1.255
inet6 fe80::df71:e49:bd9a:8b3 prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:52:5a:0f txqueuelen 1000 (Ethernet)
RX packets 6714 bytes 894198 (873.2 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 9197 bytes 2440939 (2.3 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1 (Local Loopback)
RX packets 68 bytes 5912 (5.7 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 68 bytes 5912 (5.7 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
这里有一个参数-a,他的意思是网卡没有IP的时候它是不显示的。
ifdown 网卡名:关闭网卡
这里有一个参数-a,他的意思是网卡没有IP的时候它是不显示的。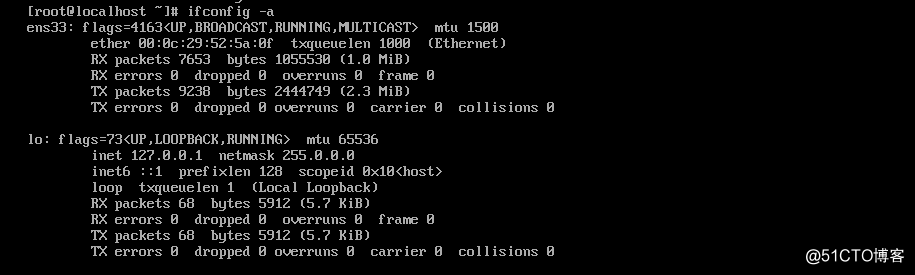
ifup 网卡名:网卡开启
ifup/ifdown这两个命令一般在我们单独针对一个网卡进行更改,比如我们增加一个dns或者更改网关,改完我们要重启网卡,但是我们又不想重启所有网卡,我们只需要重启指定网卡,那我们就可以用这两个命令,如果我们正在使用这个网卡,那我们不能直接ifdown网卡,那样我们就不能远程连接了。但是我们可以这个样做 ifdown 网卡名 && ifup 网卡名 。两个命令一起执行,这样就可以了。
给一个网卡设置多个IP
首先我们先到网卡配置文件中所在的目录中拷贝一下
[root@localhost ~]# cd /etc/sysconfig/network-scripts/
[root@localhost network-scripts]# ls
ifcfg-ens33 ifdown-eth ifdown-post ifdown-Team ifup-aliases ifup-ipv6 ifup-post ifup-Team init.ipv6-global
ifcfg-lo ifdown-ippp ifdown-ppp ifdown-TeamPort ifup-bnep ifup-isdn ifup-ppp ifup-TeamPort network-functions
ifdown ifdown-ipv6 ifdown-routes ifdown-tunnel ifup-eth ifup-plip ifup-routes ifup-tunnel network-functions-ipv6
ifdown-bnep ifdown-isdn ifdown-sit ifup ifup-ippp ifup-plusb ifup-sit ifup-wireless
然后拷贝一下当前网卡
[root@localhost network-scripts]# cp ifcfg-ens33 ifcfg-ens33\:0(\是脱意的意思)
然后我们编辑这个文件
vi ifcfg-ens33\:0
TYPE="Ethernet"
PROXY_METHOD="none"
BROWSER_ONLY="no"
BOOTPROTO="dhcp"
DEFROUTE="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
NAME="ens33:0"(需要改成新网卡名)
DEVICE="ens33:0"(需要改成新网卡名)
ONBOOT="yes"
IPV7_PRIVACY="no"
IPADDR=192.168.1.150(改成新IP)
然后执行命令
[root@localhost network-scripts]# ifdown ens33 && ifup ens33
成功断开设备 'ens33'。
连接已成功激活(D-Bus 活动路径:/org/freedesktop/NetworkManager/ActiveConnection/4)
然后我们再查询一下网络
[root@localhost network-scripts]# ifconfig
ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.1.105 netmask 255.255.255.0 broadcast 192.168.1.255
inet6 fe80::df71:e49:bd9a:8b3 prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:52:5a:0f txqueuelen 1000 (Ethernet)
RX packets 10789 bytes 1865182 (1.7 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 9772 bytes 2509163 (2.3 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
ens33:0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.1.150 netmask 255.255.255.0 broadcast 192.168.1.255
ether 00:0c:29:52:5a:0f txqueuelen 1000 (Ethernet)
这样我们就获得了新网卡
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1 (Local Loopback)
RX packets 96 bytes 8232 (8.0 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 96 bytes 8232 (8.0 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
然后我们用windows ping一下新网卡的ip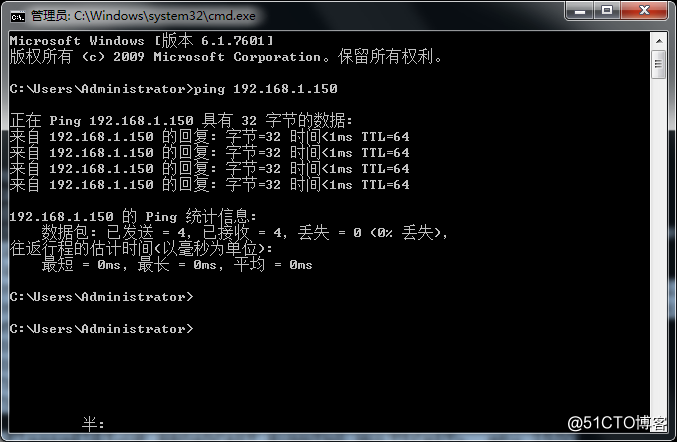
可以ping通,证明没有问题。
mii-tool 网卡名:查看网卡是否连接
[root@localhost network-scripts]# mii-tool ens33
ens33: negotiated 1000baseT-FD flow-control, link ok
这就证明我们的网卡是通的
有的时候我们用这个命令时会提示不支持,那我们就用ethtool 网卡名
[root@localhost network-scripts]# ethtool ens33
Settings for ens33:
Supported ports: [ TP ]
Supported link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
1000baseT/Full
Supported pause frame use: No
Supports auto-negotiation: Yes
Advertised link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
1000baseT/Full
Advertised pause frame use: No
Advertised auto-negotiation: Yes
Speed: 1000Mb/s
Duplex: Full
Port: Twisted Pair
PHYAD: 0
Transceiver: internal
Auto-negotiation: on
MDI-X: off (auto)
Supports Wake-on: d
Wake-on: d
Current message level: 0x00000007 (7)
drv probe link
Link detected: yes(如果是yes,就是连接成功。若是no则是没有连接网卡)
hostnamectl:更改主机名。
sentos6不支持这个命令。
[root@localhost ~]# hostnamectl set-hostname linletao-001
更改完后我们在当前的终端下我们可以用hostname来查看主机名
[root@localhost ~]# hostname
linletao-001
但是我们发现最前面我们的主机名还是没有改过来,如果我们想显示新的主机名,我们需要重新登录。
我们也可以进入一个子shell,让他显示新的主机名
[root@localhost ~]# bash
[root@linletao-001 ~]#
它的配置文件
[root@localhost ~]# cat /etc/hostname
linletao-001
设置DNS
DNS是用来解析域名的,平时我们上网都是直接数如一个网址,而DNS把这个网站解析到一个ip。
zailinux下设置DNS非常简单。只要把DNS地址写到配置文件/etc/resolv.conf中即可
[root@localhost ~]# cat /etc/resolv.conf
Generated by NetworkManager
search DHCP HOST
nameserver 202.96.69.38
nameserver 202.96.64.68
如果我们以后想改dns,那么就直接改网卡的配置文件,当然也可以vim /etc/resolv.conf。但是这样改只会是临时更改,如果网卡重启,那么他还会被以前的dns所覆盖。
linux下有一个特殊文件/etc/hosts也能解析域名,不过需要我们在里面手动添加IP和域名这些内容。它的作用是临时解析某个域名。
[root@localhost ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
我们用vim编辑这个文件,在里面增加一行内容。
[root@localhost ~]# vim /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.1.150 www.baidu.com(新增加的一行内容)
然后我们再ping一下www.baidu.com
[root@localhost ~]# ping www.baidu.com
PING www.baidu.com (192.168.1.150) 56(84) bytes of data.
64 bytes from www.baidu.com (192.168.1.150): icmp_seq=1 ttl=64 time=0.214 ms
64 bytes from www.baidu.com (192.168.1.150): icmp_seq=2 ttl=64 time=0.080 ms
64 bytes from www.baidu.com (192.168.1.150): icmp_seq=3 ttl=64 time=0.081 ms
^C
--- www.baidu.com ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2000ms
rtt min/avg/max/mdev = 0.080/0.125/0.214/0.062 ms
这样我们再ping这个网站的时候就会自动连接到我们设置的ip了。
/etc/hosts的格式很简单,每行记录一条记录,分为两部分,第一部分是IP,第二部分是域名。关于hosts的文件,我们需要注意以下几点。
1.一个ip后面可以跟多个域名,甚至是几十个上百个。
2.每行只能有一个ip,也就是一个域名不能对用多个ip。
3.如果有多行中出现相同的域名(对应ip不一样),会安最下面出现的记录来解析。
linux防火墙-netfilter
我们配置秘钥认证的时候后,我们要关闭selinux,关闭selinux分为为两种,一种是临时关闭,一种是永久关闭。
临时关闭的命令是:setenforce 0
永久关闭我们要编辑配置文件/etc/selinux/config
[root@linletao-001 ~]# vi /etc/selinux/config
This file controls the state of SELinux on the system.
SELINUX= can take one of these three values:
enforcing - SELinux security policy is enforced.
permissive - SELinux prints warnings instead of enforcing.
disabled - No SELinux policy is loaded.
SELINUX=enforcing改为(disabled关闭selinux)
SELINUXTYPE= can take one of three two values:
targeted - Targeted processes are protected,
minimum - Modification of targeted policy. Only selected processes are protected.
mls - Multi Level Security protection.
SELINUXTYPE=targeted(切记这行不要改)
然后我们用getenforce这个命令来查看selinux是否打开
[root@linletao-001 ~]# getenforce
Permissive
Permissive:虽然selinux也开启了,但是他仅仅是遇到需要发生阻断的时候它不需要真正的阻断,他仅仅是个提醒。
selinux我们平时都是关闭的,如果开启,会增大我们的运维管理成本,因为很多服务受限于selinux,我们把他关闭也不会有太大的安全问题。