hbase实战
hbase官方文档:
http://https://hbase.apache.org/
hbase简介
Apache HBase™是Hadoop数据库,这是一个分布式,可扩展的大数据存储。
当您需要随机,实时读取/写入您的大数据时使用Apache HBase™。该项目的目标是托管非常大的表 - 数十亿行X百万列 - 在商品硬件集群上。HBase是一个开源的,分布式的,版本化的非关系数据库。
hbase优点
强一致性模型
当写入返回时,所有读者将看到相同的值自动扩展
数据增长过大时分割region
使用HDFS传播和复制数据内置恢复机制
使用预写日志 (与文件系统上的日记类似)
4. 集成Hadoop
MHBase上的MapReduce很简单
hbase安装与部署
HBASE是一个分布式系统
其中有一个管理角色: HMaster(一般2台,一台active,一台backup)
其他的数据节点角色: HRegionServer(很多台,看数据容量)
安装准备:
首先,要有一个HDFS集群,并正常运行; regionserver应该跟hdfs中的datanode在一起
其次,还需要一个zookeeper集群,并正常运行
然后,安装HBASE
角色分配如下:
Hdp01: namenode datanode regionserver hmaster zookeeper
Hdp02: datanode regionserver zookeeper
Hdp03: datanode regionserver zookeeper
集群时间同步:
yum install ntpdate -y
ntpdate 0.asia.pool.ntp.org
安装步骤:
安装zookeeper
安装hbase
**注意:hbase集群的服务器时间同步要求非常严格,机器之间的时间差不能超过30s
设置linux系统时间的命令:date -s ‘2017-11-08 16:00:30’**
hwclock -w
如果能访问网络,可用时间同步服务:
yum install ntpdate -y
ntpdate 0.asia.pool.ntp.org
解压hbase安装包
修改hbase-env.sh
export JAVA_HOME=/root/apps/jdk1.7.0_67
export HBASE_MANAGES_ZK=false
<configuration>
<!-- 指定hbase在HDFS上存储的路径 -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://wangzhihua1:9000/hbase</value>
</property>
<!-- 指定hbase是分布式的 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- 指定zk的地址,多个用“,”分割 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>hdp01:2181,hdp02:2181,hdp03:2181</value>
</property>
</configuration>
修改 regionservers
hdp01
hdp02
hdp03

启动hbase集群
Habse自带高可用模式
bin/start-hbase.sh
启动完后,还可以在集群中找任意一台机器启动一个备用的master
bin/hbase-daemon.sh start master
新启的这个master会处于backup状态
安装完后,可以通过web请求访问master的状态信息
http://hdp27-01:16010/
启动hbase的命令行客户端
必须在hbase集群开启式 才能启动hbase shell
bin/hbase shell
Hbase> list // 查看表
Hbase> status // 查看集群状态
Hbase> version // 查看集群版本
命令行操作示范:
建表
create ‘t_user’,’base_info’,’extra_info’
插入数据
put ‘t_user’,’rk001’,’base_info:name’,’zhangsan’
put ‘t_user’,’rk001’,’extra_info:married’,’false’
查询数据
– 全表扫描
scan ‘t_user’
– 单行获取
get ‘t_user’,’rk001’
修改数据 —— 就是put插入后覆盖
删除数据
–> 删除一个kv
delete ‘t_user’,’rk001’,’base_info:name’
–> 删掉整行
deleteall ‘t_user’,’rk001’
–> 清空整个表
truncate ‘t_user’
–> 删除整个表
disable ‘t_user’
drop ‘t_user’
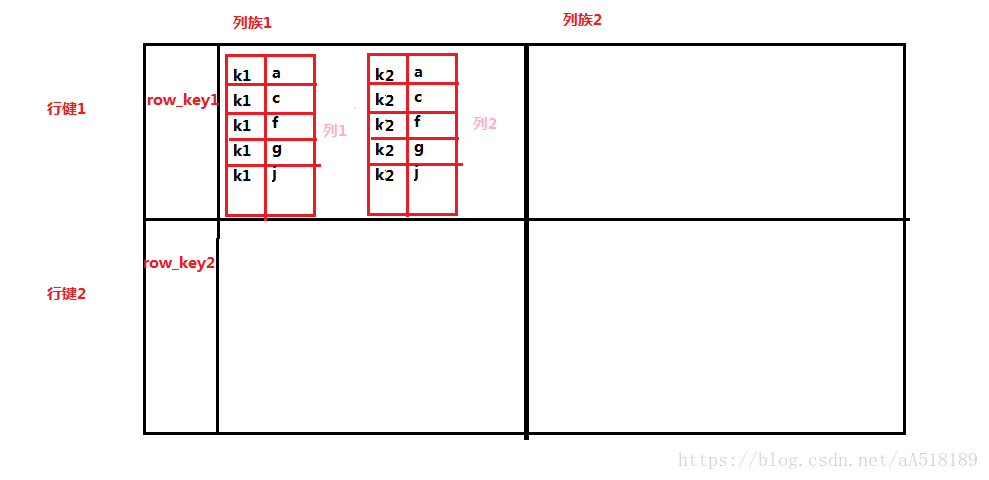
HBASE表模型
hbase的表模型跟mysql之类的关系型数据库的表模型差别巨大
hbase的表模型中有:行的概念;但没有字段的概念
行中存的都是key-value对,每行中的key-value对中的key可以是各种各样,每行中的key-value对的数量也可以是各种各样
Hbase中的列就是一组key相同的k-v对
一个put对象只能操作一行数据
Bytes.toBytes比getByte功能更强大 建议使用Bytes.toBytes
未完待续