当一个系统访问量上来的时候,不只是数据库性能瓶颈问题了,数据库数据安全也会浮现,这时候合理使用数据库锁机制就显得异常重要了。
本系列:demo下载
(一)MySQL优化笔记(一)–库与表基本操作以及数据增删改
(二)MySQL优化笔记(二)–查找优化(1)(非索引设计)
(三)MySQL优化笔记(二)–查找优化(2)(外连接、多表联合查询以及查询注意点)
(四) MySQL优化笔记(三)–索引的使用、原理和设计优化
(五) MySQL优化笔记(四)–表的设计与优化(单表、多表)
(六)MySQL优化笔记(五)–数据库存储引擎
(七)MySQL优化笔记(六)–存储过程和存储函数
(八)MySQL优化笔记(七)–视图应用详解
文章结构:(1)锁机制概述;(2)MySQL各种锁详解(并针对MyISAM和InnoDB引擎);(3)项目中锁的设计方式。
目录结构:
(1)锁机制概述
- 什么是锁,以及为什么使用锁和锁的运作?
- 锁定机制分类?
- 按封锁类型分类
- 按封锁的数据粒度分类
- 行级锁定
- 表级锁定
- 页级锁定
- 数据库事务机制。
- 什么叫事务?简称ACID。
- 事务引起的并发调度问题
- 理论上的事务的三级封锁协议
- 事务隔离级别
- 活锁与死锁的探究
- 活锁
- 死锁
(2)MySQL各种锁详解(并针对MyISAM和InnoDB引擎)
- 在这之前先讲述下MySQL在共享锁、排他锁基础上的一个锁拓展–**意向锁
- MySQL锁机制总述
- MyISAM引擎的锁机制
- 测试MyISAM表共享读锁
- 测试MyISAM表独占写锁
- 行级锁定
- 表级锁定
- 页级锁定
- InnoDB引擎的锁机制
- 与MyISAM不同,InnoDB有两大不同点
- 查看InnoDB行锁争用情况
- Innodb行锁模式以及加锁方法
- InnoDB查看锁语句
- InnoDB行锁实现方式与验证
- 补充:基于InnoDB对索引加锁的间隙锁
- 补充:InnoDB引擎什么时候使用表锁??
- 事务引擎导致的死锁
(3)项目中锁的设计方式
- InnoDB与MyISAM的不同死锁
- 在项目中如何去避免死锁
- 如何查看死锁
一、MySQL锁机制概述:
(一)什么是锁,以及为什么使用锁和锁的运作?
锁是计算机协调多个进程或纯线程并发访问某一资源的机制。在数据库中,除传统的计算资源(CPU、RAM、I/O)的争用以外,数据也是一种供许多用户共享的资源。如何保证数据并发访问的一致性、有效性是所在有数据库必须解决的一个问题,锁冲突也是影响数据库并发访问性能的一个重要因素。从这个角度来说,锁对数据库而言显得尤其重要,也更加复杂。
防止更新丢失,并不能单靠数据库事务控制器来解决,需要应用程序对要更新的数据加必要的锁来解决。
锁的运作?
事务T在度某个数据对象(如表、记录等)操作之前,先向系统发出请求,对其加锁,加锁后事务T就对数据库对象有一定的控制,在事务T释放它的锁之前,其他事务不能更新此数据对象。
(二)锁定机制分类?
锁定机制就是数据库为了保证数据的一致性而使各种共享资源在被并发访问访问变得有序所设计的一种规则。MySQL数据库由于其自身架构的特点,存在多种数据存储引擎,每种存储引擎所针对的应用场景特点都不太一样,为了满足各自特定应用场景的需求,每种存储引擎的锁定机制都是为各自所面对的特定场景而优化设计,所以各存储引擎的锁定机制也有较大区别。
按封锁类型分类:(数据对象可以是表可以是记录)
1)排他锁:(又称写锁,X锁)
一句总结:会阻塞其他事务读和写。
若事务T对数据对象A加上X锁,则只允许T读取和修改A,其他任何事务都不能再对加任何类型的锁,知道T释放A上的锁。这就保证了其他事务在T释放A上的锁之前不能再读取和修改A。
2)共享锁:(又称读取,S锁)
一句总结:会阻塞其他事务修改表数据。
若事务T对数据对象A加上S锁,则其他事务只能再对A加S锁,而不能X锁,直到T释放A上的锁。这就保证了其他事务可以读A,但在T释放A上的S锁之前不能对A做任何修改。
X锁和S锁都是加载某一个数据对象上的。也就是数据的粒度。
按封锁的数据粒度分类如下:
1)行级锁定(row-level):
一句总结:行级锁:开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高。
详细:行级锁定最大的特点就是锁定对象的颗粒度很小,也是目前各大数据库管理软件所实现的锁定颗粒度最小的。由于锁定颗粒度很小,所以发生锁定资源争用的概率也最小,能够给予应用程序尽可能大的并发处理能力而提高一些需要高并发应用系统的整体性能。
缺陷:由于锁定资源的颗粒度很小,所以每次获取锁和释放锁需要做的事情也更多,带来的消耗自然也就更大了。此外,行级锁定也最容易发生死锁。
2)表级锁定(table-level):
一句总结:表级锁:开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低。
详细:和行级锁定相反,表级别的锁定是MySQL各存储引擎中最大颗粒度的锁定机制。该锁定机制最大的特点是实现逻辑非常简单,带来的系统负面影响最小。所以获取锁和释放锁的速度很快。由于表级锁一次会将整个表锁定,所以可以很好的避免困扰我们的死锁问题。
缺陷:锁定颗粒度大所带来最大的负面影响就是出现锁定资源争用的概率也会最高,致使并发度大打折扣。
3)页级锁定(page-level):(MySQL特有)
一句总结:页级锁:开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般。
详细:页级锁定是MySQL中比较独特的一种锁定级别,在其他数据库管理软件中也并不是太常见。页级锁定的特点是锁定颗粒度介于行级锁定与表级锁之间,所以获取锁定所需要的资源开销,以及所能提供的并发处理能力也同样是介于上面二者之间。
缺陷:页级锁定和行级锁定一样,会发生死锁。
从这里我们应该引申去思考行锁更多的缺点:(因为我们执行sql主要依赖行锁来提高并发度)
1- 比表级锁、页级锁消耗更多内存
2- 如果你在大部分数据上经常进行GROUP BY操作或者必须经常扫描整个表,比其它锁定明显慢很多。
3- 更容易发生死锁。
其次,我们应该思考什么情况下用表锁、行锁
(因为我们主要使用引擎默认是这两个,MyISAM是表级锁;InnoDb是行级锁,当然也支持表级锁)
(三)数据库事务机制(这个是数据库核心,本系列多篇文章提到并重复)(为什么提及事务?因为事务中有封锁机制)
1)什么叫事务?简称ACID。是恢复和并发控制的基本单位。
A 事务的原子性(Atomicity):指一个事务要么全部执行,要么不执行.也就是说一个事务不可能只执行了一半就停止了.比如你从取款机取钱,这个事务可以分成两个步骤:1划卡,2出钱.不可能划了卡,而钱却没出来.这两步必须同时完成.要么就不完成.
C 事务的一致性(Consistency):指事务的运行并不改变数据库中数据的一致性.例如,完整性约束了a+b=10,一个事务改变了a,那么b也应该随之改变.
I 独立性(Isolation):事务的独立性也有称作隔离性,是指两个以上的事务不会出现交错执行的状态.因为这样可能会导致数据不一致.
D 持久性(Durability):事务的持久性是指事务执行成功以后,该事务所对数据库所作的更改便是持久的保存在数据库之中,不会无缘无故的回滚.
2)事务引起的并发调度问题:(这些会另开一篇给予实例)首先明确读数据要以最新的为准。
下面这些是并发操作破坏了事务的隔离性导致的。
例子根结点:原本有31张票,甲售货员读取票数为事务一,乙售货员读取票数为事务二。甲售货员卖出一张票为事务三。乙售货员卖出一张票为事务四。
1.脏读(dirty read):A事务读取B事务尚未提交的更改数据,并在这个数据基础上操作。如果B事务回滚,那么A事务读到的数据根本不是合法的,称为脏读。在oracle中,由于有version控制,不会出现脏读。
例子:事务三中售出一张票,修改了数据库31变30,可是事务还没提交,事务一读了修改了的数据(30),但是事务三被中断撤销了,比如存钱修改数据库后,在返回数据给客户时出现异常,那么事务三就是不成功的,数据会变回31。可是事务一读了一个不正确的数据。
2.不可重复读(unrepeatable read):A事务读取了B事务已经提交的更改数据。比如A事务第一次读取数据,然后B事务更改该数据并提交,A事务再次读取数据,两次读取的数据不一样。
例子:事务一读取后,事务三对31张票修改,可是事务一中,有再次读这张票的SQL语句,那么事务一得到的跟第一次不同的值(31张票就可能变成30张了)。
3.幻读(phantom read):A事务读取了B事务已经提交的新增数据。注意和不可重复读的区别,这里是新增与删除,不可重复读是更改。这两种情况对策是不一样的,对于不可重复读,只需要采取行级锁防止该记录数据被更改或删除,然而对于幻读必须加表级锁,防止在这个表中新增一条数据。
例子:事务一按一定条件读取31条记录,但是后面还有一些步骤需要再次读取此数据校验,所以没提交事务,可这个时候事务三(31条记录变30条记录)执行成功,卖出了票。那当事务一再次读的时候,就读到了30。这样读到的数据就不是最新的了。
4.丢失更新:A事务撤销时,把已提交的B事务的数据覆盖掉。
5.覆盖更新:A事务提交时,把已提交的B事务的数据覆盖掉。
4和5的例子:事务一和事务二同时读入同一数据–16张,事务一执行卖一张A-1=15,将15返回;事务二执行卖一张A-1=15,将15返回;这样一来就会覆盖了事务一对数据库的修改。
有朋友反馈说,还是区分不了不可重复读与幻读。
在这里重新补充:
不可重复读重在修改,就是你刚读过的一个数据,再读一次又一不一样了。而幻读重在记录的增删,就是你第一次读的数据量,第二次读又不一样了。
所以要解决:
解决不可重复读:这个数据只有在修改事务完全提交后才可读取数据。
解决幻读:符合这个条件下的数据,在操作事务完成处理之前,其他事务不可添加新数据、或者删除数据。
3)理论上的事务的三级封锁协议:
1.一级封锁协议:事务T中如果对数据R有写操作,必须在这个事务中对R的第一次读操作前对它加X锁,直到事务结束才释放。事务结束包括正常结束(COMMIT)和非正常结束(ROLLBACK)。
2.二级封锁协议:一级封锁协议加上事务T在读取数据R之前必须先对其加S锁,读完后方可释放S锁。
3.三级封锁协议 :一级封锁协议加上事务T在读取数据R之前必须先对其加S锁,直到事务结束才释放。
三级锁操作一个比一个厉害(满足高级锁则一定满足低级锁)。但有个非常致命的地方,一级锁协议就要在第一次读加x锁,直到事务结束。几乎就要在整个事务加写锁了,效率非常低。三级封锁协议只是一个理论上的东西,实际数据库常用另一套方法来解决事务并发问题。
4)事务隔离级别:
这个是mysql用意向锁(另一种机制,一会讲解)来解决事务并发问题,为了区别封锁协议,弄了一个新概念隔离性级别:包括Read Uncommitted、Read Committed、Repeatable Read、Serializable。mysql 一般默认Repeatable Read。
1.读未提交(Read Uncommited,RU)
一句总结:读取数据一致性在最低级别,只能保证不读物理上损坏的数据,会脏读,会不可重复读,会幻读。
这种隔离级别下,事务间完全不隔离,会产生脏读,可以读取未提交的记录,实际情况下不会使用。
2.读提交(Read commited,RC)
一句总结:读取数据一致性在语句级别,不会脏读,会不可重复读,会幻读。
仅能读取到已提交的记录,这种隔离级别下,会存在幻读现象,所谓幻读是指在同一个事务中,多次执行同一个查询,返回的记录不完全相同的现象。幻读产生的根本原因是,在RC隔离级别下,每条语句都会读取已提交事务的更新,若两次查询之间有其他事务提交,则会导致两次查询结果不一致。虽然如此,读提交隔离级别在生产环境中使用很广泛。
3.可重复读(Repeatable Read, RR)
一句总结:读取数据一致性在事务级别,不会脏读,不会不可重复读,会幻读。
可重复读隔离级别解决了不可重复读的问题,但依然没有解决幻读的问题。不可重复读重点在修改,即读取过的数据,两次读的值不一样;而幻读则侧重于记录数目变化【插入和删除】。
4.串行化(Serializable)
一句总结:读取数据一致性在最高级别,事务级别,不会脏读,不会不可重复读,不会幻读。
在串行化隔离模式下,消除了脏读,幻象,但事务并发度急剧下降,事务的隔离级别与事务的并发度成反比,隔离级别越高,事务的并发度越低。实际生产环境下,dba会在并发和满足业务需求之间作权衡,选择合适的隔离级别。
这样就解释了为什么仅靠事务就能解决丢失修改是错误的了。
| 隔离级别/会不会/并发调度问题 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 读未提交 | 会 | 会 | 会 |
| 读已提交 | 不会 | 会 | 会 |
| 可重复读 | 不会 | 不会 | 会 |
| 串行化 | 不会 | 不会 | 不会 |
(四)活锁与死锁的探究:
采用封锁的方法可以有效防止数据的不一致性,单封锁本身会引起麻烦,就是死锁和活锁。
1)活锁:
定义:
如果事务T1封锁了数据对象R后,事务T2也请求封锁R,于是T2等待,接着T3也请求封锁R。当T1释放了加载R上的锁后,系统首先批准T3的请求,T2只能继续等待。接着T4也请求封锁R,T3释放R上的锁后,系统又批转了T4的请求。这样的一直循环下去,事务T2就只能永远等待了,这样情况叫活锁。
解决方法:
采用先来先服务的队列策略。队列式申请。
2)死锁:
定义:
当两个事务分别锁定了两个单独的对象,这时每一个事务都要求在另一个事务锁定的对象上获得一个锁,因此每一个事务都必须等待另一个事务释放占有的锁。这就发生了死锁了。
例子:两个事务,事务都有两个操作。当同时发生时,事务A锁定first表,事务B锁定second表,导致了死锁。
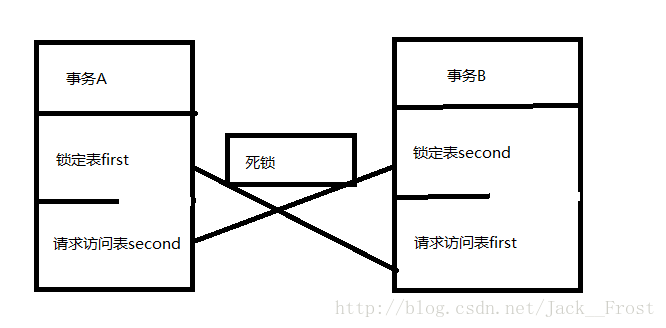
解决方法:
理论上预防死锁的发生就是要破坏产生死锁的条件。
1. 一次封锁法。
一次封锁法要求每个事务必须一次将所有要使用的数据全部加锁,否则就不能继续执行。
此方法存在的问题:(一)一次将以后要用到的全部数据加锁,加大封锁范围,降低系统的并发度。(二)数据库中数据是不断变化的,原来不要求封锁的数据,在执行过程中可能会变成封锁对象,所以很难事先精确确定每个事务要封锁的数据对象,为此只能扩大封锁范围,将事务在执行过程中可能要封锁的数据对象全部加锁,这就更降低了并发度。
2.顺序封锁法:
预先对数据对象规定一个封锁熟悉怒,所有事务都按这个顺序实行封锁。如:在B树结构的索引中,规定封锁的顺序必须从根结点开始,然后是下一级的子女结点,逐级封锁。
此方法存在的问题:(一)数据库系统中封锁的数据对象极多,随着数据的插入、删除等操作而不断变化,要维护这样的资源的封锁顺序很难,成本高。(二)事务的封锁请求可随着事务的执行而动态地决定,很难事先确定每一个事务要封锁哪些对象,因此很难按规定的顺序去加锁。比如:规定数据对象的封锁顺序:A、B、C、D、E。事务T3起初要求封锁数据对象B、C、E,但当它封锁了B、C后,才发现需要封锁A。
以上就是策略就是操作系统中广为采用的预防死锁的策略,但并不适合数据库。所以数据库系统一般采用诊断并解除死锁的方法。
死锁的诊断与解除:
数据库系统中诊断死锁的方法与操作系统类似,一般是用超时法或事务等待图法。
1.超时法:
指的是如果一个事务的等待时间超过了规定的时限,就认为发送死锁。
不足:(一)有可能误判死锁,事务因为其他原因使等待时机超过时限。(二)时限若设置得太长,死锁发生后不能及时发现。
2.等待图法:
指的是用事务等待图动态反应所有事务的等待情况。
事务等待图是一个有向图G=(T,U),其中T为结点的集合,每个结点表示正在运行的事务。U为边的集合,每条边表示事务等待的情况。若T1等待T2,则T1、T2之间划一条有向边,从T1指向T2。事务等待图动态地反映了所有事务的等待情况。并发控制子系统周期性地检测事务等待图,如果发现图中存在回路,则表示系统中出现了死锁。
以上就是死锁的诊断与解除了**。而且DBMS并发控制子系统一旦检测到系统中存在死锁,就会设法解除。通常是选择一个处理死锁代价最小的事务,将其撤销,释放此事务持有的所有的锁,使其他事务能继续运行下去。(而且要对撤销的事务所执行的数据修改操作进行恢复)
死锁真实例子呈现:
//测试表
CREATE TABLE `tb3` (
`id` SMALLINT(5) UNSIGNED NOT NULL AUTO_INCREMENT,
`username` VARCHAR(30) NOT NULL,
PRIMARY KEY (`id`)
)
COLLATE='latin1_swedish_ci'
ENGINE=InnoDB
AUTO_INCREMENT=5
;
//测试数据,就这样插几条
insert into tb3(username) values('fuzhu');测试开始:
mysql> set autocommit=0;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from tb3 where id=3 for update
-> ;
+----+----------+
| id | username |
+----+----------+
| 3 | Rose |
+----+----------+
1 row in set (0.00 sec)//再用一线程去访问(wins、Linux再开个窗口)
mysql> delete from tb3 where id =2; //行锁没锁住第二行
Query OK, 1 row affected (0.00 sec)
mysql> delete from tb3 where id =3; //因为前面有查询修改事务锁住了这一行
//然后出现死锁,最终出现以下信息:
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction最后导出死锁日志:
mysql> show engine innodb status\G;
*************************** 1. row ***************************
Type: InnoDB
Name:
Status:
=====================================
170618 20:55:42 INNODB MONITOR OUTPUT //INNODB引擎监控
=====================================
Per second averages calculated from the last 46 seconds
-----------------
BACKGROUND THREAD
-----------------
srv_master_thread loops: 19 1_second, 19 sleeps, 1 10_second, 10 background, 10
flush
srv_master_thread log flush and writes: 19
----------
SEMAPHORES
----------
OS WAIT ARRAY INFO: reservation count 4, signal count 4
Mutex spin waits 1, rounds 19, OS waits 0
RW-shared spins 4, rounds 120, OS waits 4
RW-excl spins 0, rounds 0, OS waits 0
Spin rounds per wait: 19.00 mutex, 30.00 RW-shared, 0.00 RW-excl
------------
TRANSACTIONS //事务信息
------------
Trx id counter 8450C
Purge done for trx's n:o < 8432A undo n:o < 0
History list length 1942
LIST OF TRANSACTIONS FOR EACH SESSION:
---TRANSACTION 8450A, not started
MySQL thread id 2, OS thread handle 0x15e4, query id 272 localhost 127.0.0.1 roo
t
---TRANSACTION 8450B, ACTIVE 35 sec starting index read //事务ID=8450E,活跃了35s
mysql tables in use 1, locked 1 //表有一个在使用
LOCK WAIT 3 lock struct(s), heap size 376, 2 row lock(s), undo log entries 1 //3个锁,2个行锁,1个undo log
MySQL thread id 3, OS thread handle 0x2130, query id 278 localhost 127.0.0.1 roo //该事务的线程ID=3
t updating
delete from tb3 where id =3 //这是当前事务执行的SQL,死锁的sql
------- TRX HAS BEEN WAITING 32 SEC FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 0 page no 312 n bits 72 index `PRIMARY` of table `test`.`t //上面SQL等待的锁信息
b3` trx id 8450B lock_mode X locks rec but not gap waiting
Record lock, heap no 4 PHYSICAL RECORD: n_fields 4; compact format; info bits 0
0: len 2; hex 0003; asc ;;
1: len 6; hex 000000000908; asc ;;
2: len 7; hex 890000013b0110; asc ; ;;
3: len 4; hex 526f7365; asc Rose;;
------------------
---TRANSACTION 84509, ACTIVE 101 sec //事务ID=84509,活跃了101s
2 lock struct(s), heap size 376, 1 row lock(s) //2个锁,1个行锁,1个undo log
MySQL thread id 1, OS thread handle 0x2358, query id 279 localhost 127.0.0.1 roo ///该事务的线程ID=1
t
show engine innodb status //这是当前事务执行的SQL,查询日志
--------
FILE I/O //IO流输出日志
--------
I/O thread 0 state: wait Windows aio (insert buffer thread)
I/O thread 1 state: wait Windows aio (log thread)
I/O thread 2 state: wait Windows aio (read thread)
I/O thread 3 state: wait Windows aio (read thread)
I/O thread 4 state: wait Windows aio (read thread)
I/O thread 5 state: wait Windows aio (read thread)
I/O thread 6 state: wait Windows aio (write thread)
I/O thread 7 state: wait Windows aio (write thread)
I/O thread 8 state: wait Windows aio (write thread)
I/O thread 9 state: wait Windows aio (write thread)
Pending normal aio reads: 0 [0, 0, 0, 0] , aio writes: 0 [0, 0, 0, 0] ,
ibuf aio reads: 0, log i/o's: 0, sync i/o's: 0
Pending flushes (fsync) log: 0; buffer pool: 0
489 OS file reads, 12 OS q file writes, 11 OS fsyncs
0.00 reads/s, 0 avg bytes/read, 0.11 writes/s, 0.09 fsyncs/s
-------------------------------------
INSERT BUFFER AND ADAPTIVE HASH INDEX //插入缓冲区和自适应哈希索引
-------------------------------------
Ibuf: size 1, free list len 0, seg size 2, 0 merges
merged operations:
insert 0, delete mark 0, delete 0
discarded operations:
insert 0, delete mark 0, delete 0
Hash table size 222149, node heap has 1 buffer(s)
0.00 hash searches/s, 0.04 non-hash searches/s
---
LOG
---
Log sequence number 1718594032
Log flushed up to 1718594032
Last checkpoint at 1718594032
0 pending log writes, 0 pending chkp writes
12 log i/o's done, 0.04 log i/o's/second
----------------------
BUFFER POOL AND MEMORY //缓存池与内存
----------------------
Total memory allocated 114835456; in additional pool allocated 0
Dictionary memory allocated 267680
Buffer pool size 6848
Free buffers 6369
Database pages 478
Old database pages 0
Modified db pages 0
Pending reads 0
Pending writes: LRU 0, flush list 0, single page 0
Pages made young 0, not young 0
0.00 youngs/s, 0.00 non-youngs/s
Pages read 478, created 0, written 3
0.00 reads/s, 0.00 creates/s, 0.04 writes/s
Buffer pool hit rate 1000 / 1000, young-making rate 0 / 1000 not 0 / 1000
Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s
LRU len: 478, unzip_LRU len: 0
I/O sum[0]:cur[0], unzip sum[0]:cur[0]
--------------
ROW OPERATIONS
--------------
0 queries inside InnoDB, 0 queries in queue
1 read views open inside InnoDB
Main thread id 3220, state: waiting for server activity
Number of rows inserted 0, updated 0, deleted 1, read 30
0.00 inserts/s, 0.00 updates/s, 0.02 deletes/s, 0.02 reads/s
----------------------------
END OF INNODB MONITOR OUTPUT
============================
1 row in set (0.00 sec)
ERROR:
No query specified以上就是锁机制的基本知识了。
二、MySQL各种锁详解(并针对MyISAM和InnoDB引擎):
部分参考此文章
(1)在这之前先讲述下MySQL在共享锁、排他锁基础上的一个锁拓展–意向锁。
(InnoDB特有,此外在索引加上中,InnoDB还有一种锁叫间隙锁。一会补充。)
封锁粒度结合封装类型又是一层设计。也就是说表锁中使用又可分为共享锁和排他锁。同理行锁。(MySQL意向锁基于这个问题的出现而设计)
但是我们要思考一个问题:(表级锁和行级锁之间的冲突)
事务A锁住了表中的一行,让这一行只能读,不能写。之后,事务B申请整个表的写锁。如果事务B申请成功,那么理论上它就能修改表中的任意一行,这与A持有的行锁是冲突的。数据库需要避免这种冲突,就是说要让B的申请被阻塞,直到A释放了行锁。数据库要怎么判断这个冲突呢?
普通认为两步:step1:判断表是否已被其他事务用表锁锁表。step2:判断表中的每一行是否已被行锁锁住。但是这样的方法效率很低,因为要遍历整个表。
所以解决方案是:意向锁。
在意向锁存在的情况下,事务A必须先申请表的意向共享锁,成功后再申请一行的行锁。
在意向锁存在的情况下,两步骤为:step1:判断表是否已被其他事务用表锁锁表。step2:发现表上有意向共享锁,说明表中有些行被共享行锁锁住了,因此,事务B申请表的写锁会被阻塞。
注意:申请意向锁的动作是数据库完成的,就是说,事务A申请一行的行锁的时候,数据库会自动先开始申请表的意向锁,不需要我们程序员使用代码来申请。
意向锁目的:解决表级锁和行级锁之间的冲突
意向锁是一种表级锁,锁的粒度是整张表。结合共享与排他锁使用,分为意向共享锁(IS)和意向排他锁(IX)。意向锁为了方便检测表级锁和行级锁之间的冲突,故在给一行记录加锁前,首先给该表加意向锁。也就是同时加意向锁和行级锁。
(2)刚刚MySQL锁机制总述:
MySQL中不同的存储引擎支持不同的锁机制。比如MyISAM和MEMORY存储引擎采用的表级锁,BDB采用的是页面锁,也支持表级锁,InnoDB存储引擎既支持行级锁,也支持表级锁,默认情况下采用行级锁。
三类: 行级、表级、页级
仅从锁的角度来说:表级锁更适合于以查询为主,只有少量按索引条件更新数据的应用,如Web应用;而行级锁则更适合于有大量按索引条件并发更新少量不同数据,同时又有并发查询的应用,如一些在线事务处理(OLTP)系统。
(3)MyISAM引擎的锁机制:
MyISAM只有表锁,其中又分为读锁和写锁。
前面得知:mysql的表锁有两种模式:表共享读锁(table read lock)和表独占写锁(table write lock)。(意向锁是解决行锁与表锁冲突,不在此引擎中)。
所以对于MyISAM引擎的锁兼容用一个常规图描述:
表阅读姿势:先确定当前锁模式,思考另一用户请求,就去看请求锁模式,思考是否兼容。
| 请求锁模式/是否兼容/当前锁模式 | NONE | 读锁 | 写锁 |
|---|---|---|---|
| 读锁 | 是 | 是 | 否 |
| 写锁 | 是 | 否 | 否 |
(一)MyISAM表的读操作,不会阻塞其他用户对同一个表的读请求,但会阻塞对同一个表的写请求。
(二)MyISAM表的写操作,会阻塞其他用户对同一个表的读和写操作。
(三)MyISAM表的读、写操作之间、以及写操作之间是串行的。
当一个线程获得对一个表的写锁后,只有持有锁线程可以对表进行更新操作。其他线程的读、写操作都会等待,直到锁被释放为止。
MyISAM引擎的锁表演示讲述:
首先明确:1. MySQL认为写请求一般比读请求重要。 2. MyISAM在执行查询语句(SELECT)前,会自动给涉及的所有表加读锁,在执行更新操作(UPDATE、DELETE、INSERT等)前,会自动给涉及的表加写锁,这个过程并不需要用户干预,因此用户一般不需要直接用LOCK TABLE命令给MyISAM表显式加锁。
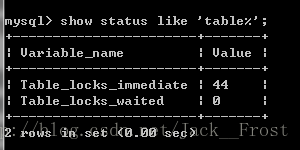
查看MyISAM表级锁的争用状态:
接着我们开始演示MyISAM引擎锁表:
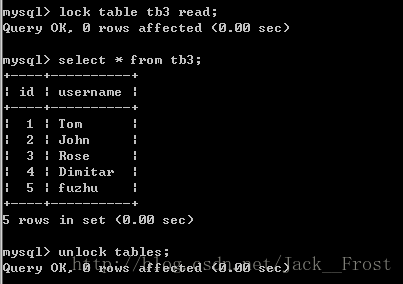
(一)测试MyISAM表共享读锁
数据准备
CREATE TABLE `tb3` (
`id` SMALLINT(5) UNSIGNED NOT NULL AUTO_INCREMENT,
`username` VARCHAR(30) NOT NULL,
PRIMARY KEY (`id`)
)
COLLATE='latin1_swedish_ci'
ENGINE=MyISAM
AUTO_INCREMENT=6
;
//测试数据,就这样插几条
insert into tb3(username) values('fuzhu');测试语句。打开两个MySQL访问窗口去访问。
其中一个:
另外一个:在前一个访问后,就立刻去访问。
(二)测试MyISAM表独占写锁
两个窗口,一个开启写的事务,这样的话在这个事务提交以前,其他事务都不可以修改与读取这个表了。
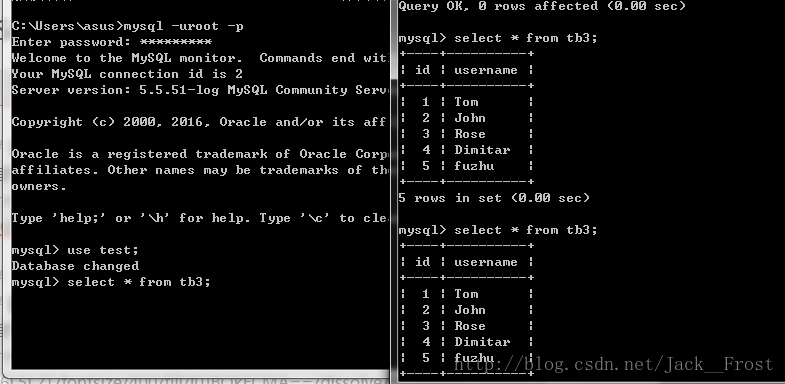
直到这个事务提交,另一个事务才能读取成功。且看时间停了多久
(三)另外,MyISAM的锁调度就是让我们更好地去让MySQL适应市场的需求,解决刚刚首要明确的问题。
1. 通过指定启动参数low-priority-updates,使MyISAM引擎默认给予读请求以优先的权利。
2. 通过执行命令SET LOW_PRIORITY_UPDATES=1,使该连接发出的更新请求优先级降低。
3. 通过指定INSERT、UPDATE、DELETE语句的LOW_PRIORITY属性,降低该语句的优先级。
虽然上面方式都挺极端的。但是MySQL也提供了一种折中的办法来调节读写冲突,即给系统参数max_write_lock_count设置一个合适的值,当一个表的读锁达到这个值后,MySQL变暂时将写请求的优先级降低,给读进程一定获得锁的机会。
(四)MyISAM并发插入问题:
MyISAM存储引擎有一个系统变量,concurrent_insert,专门用来控制并发插入行为的,值可以为0,1,2.
concurrent_insert为0时候,不允许插入
concurrent_insert为1时候,如果mysql没有空洞(中间没有被删除的行),myISAM运行一个进程读表的时候,另一个进程从表尾插入记录,这也是mysql默认设置。
concurrent_insert为2时候,无论MyISAM表中有没有空洞,都允许在表尾并行的插入。
(4)InnoDB引擎的锁机制:
(一)与MyISAM不同,InnoDB有两大不同点:
1)支持事务
2)采用行级锁
(二)查看InnoDB行锁争用情况:
(三)Innodb行锁模式以及加锁方法:
一共三类:共享锁,排他锁,意向锁。其中意向锁分为意向共享锁和意向排他锁。详情请见前文。
表阅读姿势:先确定当前锁模式,思考另一用户请求,就去看请求锁模式,思考是否兼容。
| 请求锁模式/是否兼容/当前锁模式 | 共享锁 | 排他锁 | 意向共享锁 | 意向排他锁 |
|---|---|---|---|---|
| 共享锁 | 兼容 | 冲突 | 兼容 | 冲突 |
| 排他锁 | 冲突 | 冲突 | 冲突 | 冲突 |
| 意向共享锁 | 兼容 | 冲突 | 兼容 | 兼容 |
| 意向排他锁 | 冲突 | 冲突 | 兼容 | 兼容 |
注意:
如果一个事务请求的锁模式与当前的锁模式兼容,innodb就将请求的锁授予该事务;反之,如果两者不兼容,该事务就要等待锁释放。意向锁是Innodb自动加的,不需要用户干预。
对于UPDATE、DELETE、INSERT语句,Innodb会自动给涉及的数据集加排他锁(X);对于普通SELECT语句,Innodb不会加任何锁。
(四)InnoDB查看锁语句:
//显示共享锁(S) :
SELECT * FROM table_name WHERE .... LOCK IN SHARE MODE
//显示排他锁(X):
SELECT * FROM table_name WHERE .... FOR UPDATE.使用select … in share mode获取共享锁,主要用在需要数据依存关系时,确认某行记录是否存在,并确保没有人对这个记录进行update或者delete。
(五)InnoDB行锁实现方式与验证:(可能会遇到所有事务并发问题–InnoDB是事务引擎)
InnoDB行锁是通过给索引上的索引项加锁来实现的,这一点MySQL与Oracle不同,后者是通过再数据块中,对相应数据行加锁来实现的。InnoDB这种行锁实现特点意味着:只有通过索引条件检索数据,innoDB才使用行级锁,否则InnoDB将使用表锁,在实际开发中应当注意。
验证一:行锁是针对索引的
1.数据表准备:注意是没有索引的表!没有索引!没有索引!唯一索引也是一种索引,不能用!
CREATE TABLE `tb0` (
`id` SMALLINT(5) UNSIGNED NOT NULL,
`id2` SMALLINT(5) UNSIGNED NOT NULL
)
COLLATE='latin1_swedish_ci'
ENGINE=InnoDB
;
//插两条记录
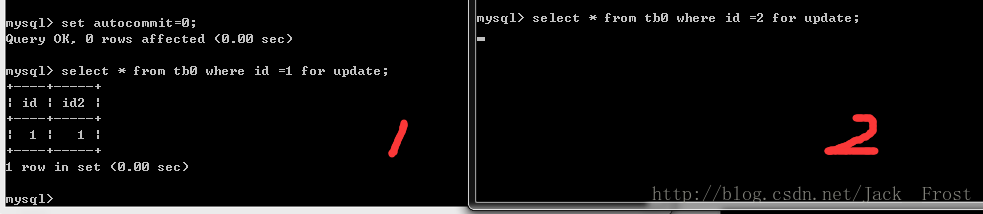
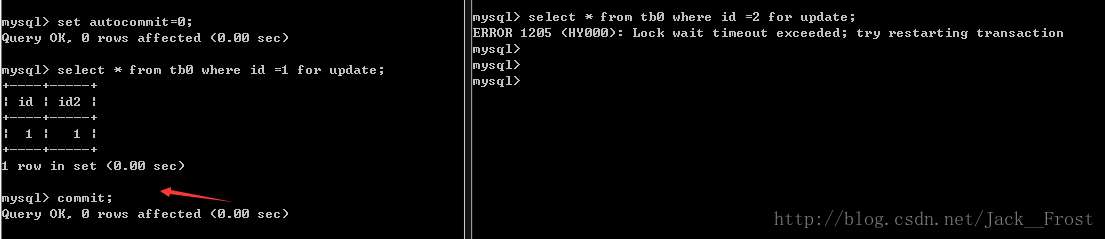
insert into tb0 values(1,1),(2,2);2. 可以看到有1和2的session窗口去访问。
第一个窗口(用户)去访问。先设置事务提交方式,再进行去查询修改操作。没有索引情况下,一个用户访问,可事务还没提交,第二个用户就不能访问。可见,行锁是针对索引的!!!
3.提交事务后。
可见第二个窗口(用户)锁等待超时。
验证二:行锁真正的作用范围
1. 数据准备:表基于第一个验证去改造(加索引–普通索引,索引值可出现多次。),测试状态也是:set autocommi = 0; 事务手动提交。
在innodb中,不同的索引的考量是不同的。具体见:
CREATE TABLE `tb7` (
`id` SMALLINT(5) UNSIGNED NOT NULL,
`id2` SMALLINT(5) UNSIGNED NOT NULL,
INDEX id (id)
)
COLLATE='latin1_swedish_ci'
ENGINE=InnoDB
;
insert into tb7 values(1,1),(2,2),(1,3);
//并且添加索引:
ALTER TABLE tb0 ADD INDEX id1(id);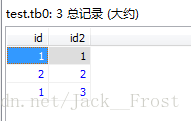
2. 还是两个窗口(用户)同时访问:结果是第一个用户访问不再锁表,而是锁行。

3. 还是两个窗口(用户)同时访问。使用的是普通索引,所以索引值可多个。也就是我故意插入的1和3记录。那么当确定访问第一条记录,就会把索引为1指向的给锁定,也就是锁定了1和3记录,因为他们的索引值都是1。

最终会导致第二个窗口(用户)访问超时。

因为Mysql行锁是针对索引加的锁,不是针对记录加的锁,索引虽然访问不同的记录,但是他们的索引相同,是会出现冲突的,在设计数据库时候需要注意这一点。上面只有将字段id2,也添加上索引才能解决冲突问题。这也是mysql效率低的一个原因。
(六)补充:基于InnoDB对索引加锁的间隙锁
定义:
当我们用范围条件而不是相等条件检索数据,并请求共享或排他锁时,InnoDB会给符合条件的已有数据的索引项加锁;对于键值在条件范围内但并不存在的记录,叫做“间隙(GAP)”,InnoDB也会对这个“间隙”加锁,这种锁机制就是所谓的间隙锁(Next-Key锁)。
举例来说
假如user表中只有101条记录,其userid 的值分别是1,2,…,100,101,下面的SQL:SELECT * FROM user WHERE userid > 100 FOR UPDATE
上面是一个范围条件的检索,InnoDB不仅会对符合条件的userid 值为101的记录加锁,也会对userid 大于101(这些记录并不存在)的“间隙”加锁。
目的:
一方面是为了防止幻读,以满足相关隔离级别的要求,对于上面的例子,要是不使用间隙锁,如果其他事务插入了userid 大于100的任何记录,那么本事务如果再次执行上述语句,就会发生幻读;另一方面,是为了满足其恢复和复制的需要。有关其恢复和复制对机制的影响,以及不同隔离级别下InnoDB使用间隙锁的情况。
实际开发:
可见,在使用范围条件检索并锁定记录时,InnoDB这种加锁机制会阻塞符合条件范围内键值的并发插入,这往往会造成严重的锁等待。因此,在实际开发中,尤其是并发插入比较多的应用,我们要尽量优化业务逻辑,尽量使用相等条件来访问更新数据,避免使用范围条件。
补充对行锁之间隙锁的思考、LBCC到MVCC的设计思考
我们也应该从这里开始深入:思考InnoDB的行锁算法。
InnoDB是一个支持行锁的存储引擎,锁的类型有:共享锁(S)、排他锁(X)、意向共享(IS)、意向排他(IX)。
也就是我们的LBCC,基于锁的并发控制。
InnoDB有三种行锁的算法:
1)Record Lock:单个行记录上的锁。
2)Gap Lock:间隙锁,锁定一个范围,但不包括记录本身。GAP锁的目的,是为了防止同一事务的两次当前读,出现幻读的情况。
3)Next-Key Lock:1+2,锁定一个范围,并且锁定记录本身。对于行的查询,都是采用该方法,主要目的是解决幻读的问题。
而上面所说的间隙锁就是行锁的算法之一。
但是 我们要想到LBCC这样的加锁访问,其实并不算是真正的并发,或者说它只能实现并发的读,因为它最终实现的是读写串行化,这样就大大降低了数据库的读写性能。
基于这样,MySQL在后续设计中引入MVCC这一基于多版本的并发控制协议。主要是解决读写的冲突!!!
MVCC只工作在RC与RR级别下,当然最主要还是为RR级别设计。(MVCC的博客解析太多了,我就不多说了)。
然后我们要思考一个问题,MVCC解决读写冲突,那写写冲突如何解决?
那就是一个乐观锁的设计了。(这个博客也很多,也不多说了)
(七)补充:InnoDB引擎什么时候使用表锁??
对于InnoDB表,在绝大部分情况下都应该使用行级锁,因为事务和行锁往往是我们之所以选择InnoDB表的理由。但在个另特殊事务中,也可以考虑使用表级锁。
1. 第一种情况是:事务需要更新大部分或全部数据,表又比较大,如果使用默认的行锁,不仅这个事务执行效率低,而且可能造成其他事务长时间锁等待和锁冲突,这种情况下可以考虑使用表锁来提高该事务的执行速度。
2. 第二种情况是:事务涉及多个表,比较复杂,很可能引起死锁,造成大量事务回滚。这种情况也可以考虑一次性锁定事务涉及的表,从而避免死锁、减少数据库因事务回滚带来的开销。
在InnoDB下 ,使用表锁要注意以下两点。
(1)使用LOCK TALBES虽然可以给InnoDB加表级锁,但必须说明的是,表锁不是由InnoDB存储引擎层管理的,而是由其上一层MySQL Server负责的,仅当autocommit=0、innodb_table_lock=1(默认设置)时,InnoDB层才能知道MySQL加的表锁,MySQL Server才能感知InnoDB加的行锁,这种情况下,InnoDB才能自动识别涉及表级锁的死锁;否则,InnoDB将无法自动检测并处理这种死锁。
(2)在用LOCAK TABLES对InnoDB锁时要注意,要将AUTOCOMMIT设为0,否则MySQL不会给表加锁;事务结束前,不要用UNLOCAK TABLES释放表锁,因为UNLOCK TABLES会隐含地提交事务;COMMIT或ROLLBACK产不能释放用LOCAK TABLES加的表级锁,必须用UNLOCK TABLES释放表锁,正确的方式见如下语句。
如果需要写表t1并从表t读,可以按如下做:
mysql> SET AUTOCOMMIT=0;
mysql> LOCAK TABLES t1 WRITE, t2 READ, ...;
[do something with tables t1 and here];
mysql> COMMIT;
mysql> UNLOCK TABLES;三、项目中锁的设计方式
1)两个引擎的死锁对比
MyISAM表锁是无死锁的,这是因为MyISAM总是一次性获得所需的全部锁,要么全部满足,要么等待,因此不会出现死锁。但是在InnoDB中,除单个SQL组成的事务外,锁是逐步获得的,这就决定了InnoDB发生死锁是可能的。
发生死锁后,InnoDB一般都能自动检测到,并使一个事务释放锁并退回,另一个事务获得锁,继续完成事务。但在涉及外部锁,或涉及锁的情况下,InnoDB并不能完全自动检测到死锁,这需要通过设置锁等待超时参数innodb_lock_wait_timeout来解决。需要说明的是,这个参数并不是只用来解决死锁问题,在并发访问比较高的情况下,如果大量事务因无法立即获取所需的锁而挂起,会占用大量计算机资源,造成严重性能问题,甚至拖垮数据库。我们通过设置合适的锁等待超时阈值,可以避免这种情况发生。
通常来说,死锁都是应用设计的问题,通过调整业务流程、数据库对象设计、事务大小、以及访问数据库的SQL语句,绝大部分都可以避免。
2)下面就通过实例来介绍几种死锁的常用避免和解决方法。
1)在应用中,如果不同的程序会并发存取多个表,应尽量约定以相同的顺序为访问表,这样可以大大降低产生死锁的机会。如果两个session访问两个表的顺序不同,发生死锁的机会就非常高!但如果以相同的顺序来访问,死锁就可能避免。
2)在程序以批量方式处理数据的时候,如果事先对数据排序,保证每个线程按固定的顺序来处理记录,也可以大大降低死锁的可能。
3)在事务中,如果要更新记录,应该直接申请足够级别的锁,即排他锁,而不应该先申请共享锁,更新时再申请排他锁,甚至死锁。
4)在REPEATEABLE-READ隔离级别下,如果两个线程同时对相同条件记录用SELECT…ROR UPDATE加排他锁,在没有符合该记录情况下,两个线程都会加锁成功。程序发现记录尚不存在,就试图插入一条新记录,如果两个线程都这么做,就会出现死锁。这种情况下,将隔离级别改成READ COMMITTED,就可以避免问题。
5)当隔离级别为READ COMMITED时,如果两个线程都先执行SELECT…FOR UPDATE,判断是否存在符合条件的记录,如果没有,就插入记录。此时,只有一个线程能插入成功,另一个线程会出现锁等待,当第1个线程提交后,第2个线程会因主键重出错,但虽然这个线程出错了,却会获得一个排他锁!这时如果有第3个线程又来申请排他锁,也会出现死锁。对于这种情况,可以直接做插入操作,然后再捕获主键重异常,或者在遇到主键重错误时,总是执行ROLLBACK释放获得的排他锁。
尽管通过上面的设计和优化等措施,可以大减少死锁,但死锁很难完全避免。因此,在程序设计中总是捕获并处理死锁异常是一个很好的编程习惯。
3)如何查看死锁
如果出现死锁,可以用SHOW INNODB STATUS命令来确定最后一个死锁产生的原因和改进措施。