如果遇到请求量非常的项目,那数据库必须读写分离,那为什么要读写分离?mysql为例:
1.写时锁表,更新索引耗时多
如果表的数据量大,那为了加快读(select * from)的速度,必须创建合理的索引。但是如果索引过多(各种复杂统计需要),必然写(insert,update,delete)的时候为了维护索引mysql会耗时更长。
读写分离后,可以在写库上保留少量索引即可,至于复杂统计sql所需的索引可以在读库上创建。
2.多个读库,分压io
一写多读,多个读库间采取负载均衡策略,将庞大的请求分到不同的读库,避免所有的请求都在同一个库上处理。
我在博文“spring boot学习7之mybatis+mysql读写分离(一写多读)+事务”中,数据库源的切换采取的是AbstractRoutingDataSource,多个读库的负载均衡,只是简单的轮询
/**
* 把所有数据库都放在路由中
* @return
*/
@Bean(name="roundRobinDataSouceProxy")
public AbstractRoutingDataSource roundRobinDataSouceProxy() {
Map<Object, Object> targetDataSources = new HashMap<Object, Object>();
//把所有数据库都放在targetDataSources中,注意key值要和determineCurrentLookupKey()中代码写的一至,
//否则切换数据源时找不到正确的数据源
targetDataSources.put(DataSourceType.write.getType(), writeDataSource);
targetDataSources.put(DataSourceType.read.getType()+"1", readDataSource01);
targetDataSources.put(DataSourceType.read.getType()+"2", readDataSource02);
final int readSize = Integer.parseInt(readDataSourceSize);
// MyAbstractRoutingDataSource proxy = new MyAbstractRoutingDataSource(readSize);
//路由类,寻找对应的数据源
AbstractRoutingDataSource proxy = new AbstractRoutingDataSource(){
private AtomicInteger count = new AtomicInteger(0);
/**
* 这是AbstractRoutingDataSource类中的一个抽象方法,
* 而它的返回值是你所要用的数据源dataSource的key值,有了这个key值,
* targetDataSources就从中取出对应的DataSource,如果找不到,就用配置默认的数据源。
*/
@Override
protected Object determineCurrentLookupKey() {
String typeKey = DataSourceContextHolder.getReadOrWrite();
if(typeKey == null){
// System.err.println("使用数据库write.............");
// return DataSourceType.write.getType();
throw new NullPointerException("数据库路由时,决定使用哪个数据库源类型不能为空...");
}
if (typeKey.equals(DataSourceType.write.getType())){
System.err.println("使用数据库write.............");
return DataSourceType.write.getType();
}
//读库, 简单负载均衡
int number = count.getAndAdd(1);
int lookupKey = number % readSize;
System.err.println("使用数据库read-"+(lookupKey+1));
return DataSourceType.read.getType()+(lookupKey+1);
}
};
proxy.setDefaultTargetDataSource(writeDataSource);//默认库
proxy.setTargetDataSources(targetDataSources);
return proxy;
}
使用Mycat的话,那应用代码,就无需这么复杂了,因为读写分离的配置只需在Mycat中配置好,应用程序仍旧像操作一个数据库那样就OK了,无需关心读写分离的逻辑。
读写分离后,写库和读库之间的数据同步,是有mysql完成的,如果网络异常的时候,会导致写库和读库之间存在同步延迟,但应用代码可能会这样操作,立即insert,然后立即select,如果select走读库,读库的数据却还没从写库同步过来,那就会导致应用代码出现问题。mycat的处理方法是,写的时候开启事务,开启了事务,那读(select)的时候,就不走读库了,而是直接查询写库。
接下来,动手实践下。
准备环境
1.两个或多个mysql服务,配置后一主一从或一主多从,参考博文“mysql5.7主从配置--docker创建mysql”
2.mycat的安装或源码运行模式,navicat连接mycat
写库:192.168.174.136:3306
读库:192.168.174.136:3307

mycat的schema.xml
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<!-- 逻辑库配置 -->
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1">
<!-- 表分片配置在这些 -->
</schema>
<!-- 节点配置 -->
<dataNode name="dn1" dataHost="host01" database="test" />
<!-- 读写分离的配置 -->
<dataHost name="host01" maxCon="1000" minCon="10" balance="3"
writeType="0" dbType="mysql" dbDriver="native" switchType="-1" slaveThreshold="100">
<heartbeat>show slave status</heartbeat>
<writeHost host="hostM1" url="192.168.174.136:3306" user="root" password="123456">
<!-- 可以在这配置它对应的多个读库 -->
<readHost host="hostS1" url="192.168.174.136:3307" user="root" password="123456" />
</writeHost>
<!--主故障,顶替写节点,主正常是分担都读压力-->
<!-- <writeHost host="hostS1" url="192.168.1.200:3308" user="root" password="123456" />
-->
</dataHost>
</mycat:schema>name 该属性唯一标示dataHost标签,供上层的标签使用。
maxCon 该属性指定每个实例连接池的最多连接。也就是说,标签内嵌套的writeHost、readHost标签都会使用这个属性的值来实例化出连接池的最多连接数。
minCon 该属性指定每个读写实例连接池的最小连接,初始化连接池的大小。
balance 属性,负载均衡类型,目前的值有3种:
1. balance="0", 不开启读写分离机制,所有读操作都发送到当前可用的writeHost上。
2. balance="1",全部的readHost与stand by writeHost参与select询句的负载均衡,简单的说,当双主双从模式(M1->S1,M2->S2,并且M1与 M2互为主备),正常情况下,M2,S1,S2都参不select语句的负载均衡。
3. balance="2",所有读操作都随机的在writeHost、readhost上分发。
4. balance="3",所有读请求随机的分发到wiriterHost对应的readhost执行,writerHost不负担读压力,注意balance=3
writeType 属性
负载均衡类型,目前的取值有3种:
1. writeType="0", 所有写操作发送到配置的第一个writeHost,第一个挂了切换到还生存的第二个writeHost,重新启动后已切换后的为准,切换记录在配置文件中:dnindex.properties .
2. writeType="1",所有写操作都随机的发送到配置的writeHost,1.5以后废弃不推荐使用。
switchType 属性
-1 表示不自动切换
1 默认值,自动切换
2 基二MySQL主从同步的状态决定是否切换
dbType 属性
指定后端连接数据库类型,目前支持二进制的mysql协议,还有其他使用JDBC连接的数数据库。例如:mongodb、oracle、spark等。
dbDriver 属性
指定连接后端数据库使用的Driver,目前可选的值有native和JDBC。使用native的话,因为这个值执行的是二进制的mysql协议,所以可使用mysql和maridb。其他类型的数据库需要使用JDBC驱劢来支持。
如果使用JDBC的话需要将符合JDBC 4标准的驱动JAR包放刡MYCAT\lib目录下,并检查驱劢JAR包中包括如下目录结构的文件:META-INF\services\java.sql.Driver。在这个文件内写上具体的Driver类名,例如:com.mysql.jdbc.Driver。
switchType 属性
-1 表示不自动切换
1 默讣值,自动切换
2 基二MySQL主仅同步癿状忏决定是否切换 心跳询句为 show slave status
3 基二MySQL galary cluster癿切换机刢(适吅集群)(1.4.1) 心跳询句为 show status like ‘wsrep%’.
tempReadHostAvailable 属性
如果配置了返个属忓writeHost 下面癿readHost仄旧可用,默讣0 可配置(0、1)。
heartbeat 标签
这个标签内指明于和后端数据库进行心跳检查的询句。例如,MYSQL可以使用select user(),Oracle可以使用select 1 from dual等。 这个标签还有一个connectionInitSql属性,主要是当使用Oracla数据库时,需要执行的初始化SQL语句就这个放到这里面来。例如:alter session set nls_date_format='yyyy-mm-dd hh24:mi:ss' 1.4主从切换的语句必项是:show slave status
writeHost标签、readHost标签
这两个标签都指定后端数据库的相关配置给mycat,用与实例化后端连接池。唯一不同的是,writeHost指定写实例、readHost指定读实例,组装这些读写实例来满足系统的要求。
在一个dataHost内可以定义多个writeHost和readHost。但是,如果writeHost指定的后端数据库宕机,那么这个writeHost绑定的所有readHost都将不可用。另一方面,由于这个writeHost宕机系统会自动的检测到,并切换到备用的writeHost上去。 这两个标签的属性相同,这里就一起介绍。
host属性
用与标识不同实例,一般writeHost我们使用*M1,readHost我们用*S1。
url属性
后端实例连接地址,如果是使用native的dbDriver,则一般为address:port返种形式。用JDBC或其他的dbDriver,则需要特殊指定。当使用JDBC时则可以这么写:jdbc:mysql://localhost:3306/。
user属性
后端物理数据数据实例所需要的用户名
password属性
后端物理数据数据实例所需要的密码
weight 属性
权重 配置在readhost 中作为读节点的权重
usingDecrypt 属性
是否对密码加密默认0 否 如需要开启配置1,同时使用加密程序对密码加密,加密命令为: 执行mycat.jar 程序
debug模式启动mycat(我是用eclipse运行源码模式),然后navicat连接mycat(为了避免乱码,记得mysql,mycat,navicat连接mysql的设置,都配置为utf-8).
连接mycat后,执行sql:
insert `user`(user_name) values('小红'),('小明');检查3306,3307表user的时候,发现都有数据了,直接在读库3307修改,把"小明"修改为"小明R",然后在mycat下select * from `user` where id=8(小明对应的id),得到的数据是“小明R”,说明select的时候走的是读库。
select的时候强制指定走写/读库
现在写库和读库上的id=8对应的小明不同了,写库上是“小明”,读库上是“小明R”,然后直接select * from user where id=8,那得到的时候“小明R”,如果想走写库得到“小明”呢?Mycat提供了方法。
1.sql中写明强制走哪个类型的库
强制走写库
/*!mycat:db_type=master*/select * from `user` where id=8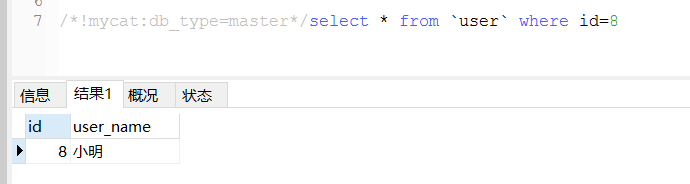
强制走读库
/*!mycat:db_type=slave*/select * from `user` where id=8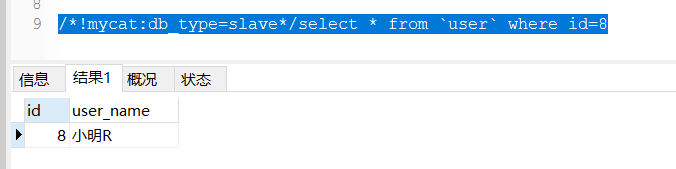
这种模式的弊端是,写sql 的时候限制死了是走写库还是读库。
2.开启事务的时候走写库
begin;
select * from `user` where id=8;
commit;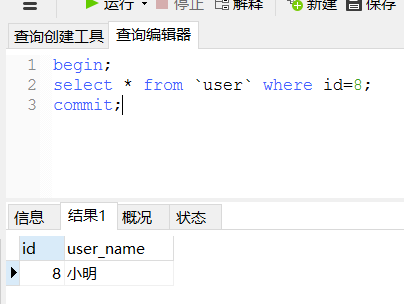
测试:写库挂了,还能写/读吗?
关闭3306
然后insert失败了
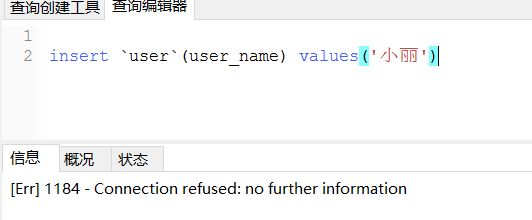
select 也失败
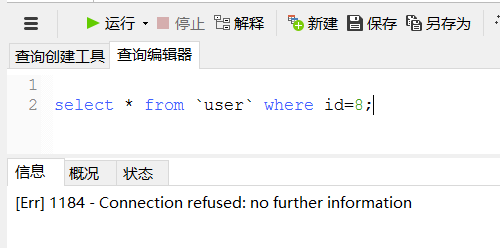
可见当写挂了,读也不可用了。官方文档有些schema.xml中读写分离的另一种配置方式,可以起到写挂了,读仍然可用。
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="1"
writeType="0" dbType="mysql" dbDriver="native">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="hostM1" url="localhost:3306" user="root" password="123456">
</writeHost>
<writeHost host="hostS1" url="localhost:3307" user="root" password="123456">
</writeHost>
</dataHost>