首先声明,赌博一定不是什么好事,也完全没有意义,不要指望用彩票发财。之所以写这个,其实是用来练手的,可以参考这个来预测一些其他的东西,意在抛砖引玉。
啰嗦完了,马上开始,先上伪代码
打开网址
读取内容
内容解析
根据源码得到需爬取内容
1、开奖日期:2018年8月26日
2、红球
<li class="ball_red">03</li>
<li class="ball_red">07</li>
<li class="ball_red">08</li>
<li class="ball_red">14</li>

<li class="ball_red">25</li>
<li class="ball_red">32</li>
3、篮球
<li class="ball_blue">06</li>
打开数据库连接
爬取内容写入数据库
共3个字段
1、开奖日期
2、红球,红球使用分号“;”分隔,方便调用和导出
3、篮球
在写脚本前,建议先写伪代码,伪代码格式不是固定的,随自己喜好,主要就是在思维及算法落地前,把整个轮廓理清,可以有效降低都快写完了,发现前面有错误,结果导致整个脚本全部更新一遍这种事
的发生概率
伪代码解读:
共分为两个功能块
一就是抓取彩票数据,这个使用爬虫实现,分别抓取开奖日期、红球区、篮球区,因为考虑双色球的数据量比较庞大,所以这次使用数据库进行存储,选用的是免费又好用的mysql数据库,数据库接口文件使用MySQLdb,这个我以后会单独写一个说明,当然你也可以用文档存储,或者选择别的数据库比如oracle或者nosql的mangodb
二是用来分析彩票的,即使用彩票数据进行下一期的彩票预测,本次选用的是二项分布,这个在之前的算法里面有,就不重复说明了
下面先上脚本,再对脚本进行说明
#!/usr/bin/python # coding: UTF-8 ''' 打开网址 读取内容 内容解析 根据源码得到需爬取内容 1、开奖日期:2018年8月26日 2、红球 <li class="ball_red">03</li> <li class="ball_red">07</li> <li class="ball_red">08</li> <li class="ball_red">14</li> <li class="ball_red">25</li> <li class="ball_red">32</li> 3、篮球 <li class="ball_blue">06</li> 打开数据库连接 爬取内容写入数据库 共3个字段 1、开奖日期 2、红球,红球使用分号“;”分隔,方便调用和导出 3、篮球 create table tow_color_ball(open_date varchar(10),red_n varchar(20),blue_n varchar(2)) ''' import urllib import urllib2 import re import numpy as np import operator import MySQLdb # 连接mysql def conn_db(): db = 'pythondb' host = 'localhost' iuser = 'xxx' passwd = 'xxxxxx' conn = MySQLdb.connect(db = db, host = host, user = iuser, passwd = passwd) cursor = conn.cursor() return cursor # 处理网页获取页面源码 def get_html_values(url): url_open = urllib.urlopen(url) url_read = url_open.read() return url_read # 处理源码,获取日期、红球、篮球 def manage_html(html_values): red_no_re = re.compile('(?<=\<li class\=\"ball_red\"\>)[0-9]+(?=\<\/li\>)') blue_no_re = re.compile('(?<=\<li class\=\"ball_blue\"\>)[0-9]+(?=\<\/li\>)') date_re = re.compile('(?<=开奖日期:)[0-9]+年[0-9]+月[0-9]+日') red_no_list = re.findall(red_no_re,html_values) red_numbers = ';'.join(red_no_list) blue_number = re.search(blue_no_re,html_values) blue_number = blue_number.group() date_value = re.search(date_re,html_values) date_value = date_value.group() return date_value, red_numbers, blue_number # 可恶的日期,竟然是YYYY年MM月DD日,需要改成YYYY-MM-DD def manage_date(date_value): date_value = date_value.replace('年','-').replace('月','-').replace('日','') return date_value # 处理页面编号,每次编号-1,也就是说end_page要小于url中的页码 def get_page(url,end_page): url_num = re.search('(?<=\/)[0-9]+(?=\.)',url) url_num = url_num.group() if int(end_page) > int(url_num): return 'end' url_num_1 = int(url_num) - 1 url = url.replace(url_num,str(url_num_1)) return url # 查看库中是否已存在开奖日期,防止重复写入 def check_open_date(open_date): conn = conn_db() check_sql = 'select 1 from tow_color_ball where open_date = %r' %open_date conn.execute(check_sql) excur = conn.fetchall() conn.close() #如过未查到excur == () return excur # 写入数据库 def write_db(date_value, red_numbers, blue_number): conn = conn_db() in_sql = "insert into tow_color_ball(open_date,red_n,blue_n) values(%r,%r,%r)" %(date_value, red_numbers, blue_number) conn.execute(in_sql) conn.execute('commit') conn.close() # 彩票主程序,用来爬取彩票号码 def ball_main(url,end_page): while True: html_values = get_html_values(url) date_value, red_numbers, blue_number = manage_html(html_values) date_value = manage_date(date_value) data_check = check_open_date(date_value) if data_check == (): write_db(date_value, red_numbers, blue_number) url = get_page(url,end_page) if url == 'end': print 'url_page已到达end_page,获取完成' return 0 # 二项分布算法 class binomial_class(object): def __init__(self,case_count,real_count,p): self.case_count = case_count self.real_count = real_count self.p = p def multiply_fun(self,xlist): n = 1 for x in xlist: n *= x return n def fact_fun(self,n): if n == 0: return 1 n += 1 fact_list = [i for i in range(1,n)] fact_num = self.multiply_fun(fact_list) return fact_num def c_n_x(self): fact_n = self.fact_fun(self.case_count) fact_x = self.fact_fun(self.real_count) fact_n_x = self.fact_fun(self.case_count - self.real_count) c_n_x_num = float(fact_n) / (fact_x * fact_n_x) return c_n_x_num def binomial_fun(self): c_n_k_num = self.c_n_x() pi = (self.p ** self.real_count) * ((1 - self.p) ** (self.case_count - self.real_count)) binomial_num = c_n_k_num * pi return binomial_num # 从库里获取彩票信息 def get_ball_infomation(start_dt,end_dt): conn = conn_db() sql = "select red_n,blue_n from tow_color_ball where date_format(open_date,'%%Y-%%m-%%d') >= %r and date_format(open_date,'%%Y-%%m-%%d') <= %r" %(start_dt,end_dt) conn.execute(sql) excur = conn.fetchall() conn.close() case_array = np.array(excur) row_count = case_array.shape[0] col_count = case_array.shape[1] red_ball_array = case_array[:,0] blue_ball_array = case_array[:,1] return red_ball_array,blue_ball_array,row_count,col_count # 统计每个号码球的出现次数,这个应该在数据库里做,先放这,以后改 def every_ball_count(ball_array): ball_list = [] for ball_char in ball_array: ball_list += ball_char.split(';') ball_count = {} for ball_num in ball_list: if ball_num in ball_count: ball_count[ball_num] += 1 else: ball_count[ball_num] = ball_count.get(ball_num,0) + 1 return ball_count # 数据分析主函数,样本量必须大于等于7,否则不进行处理 def analysis_main(start_dt,end_dt): red_ball_array,blue_ball_array,row_count,col_count = get_ball_infomation(start_dt,end_dt) if row_count < 7: print '样本量不足以支持分析' return 1 red_count_dict = every_ball_count(red_ball_array) blue_count_dict = every_ball_count(blue_ball_array) for red_case in red_count_dict: red_rate = binomial_class((red_count_dict[red_case] + 1),(row_count + 1),0.5) red_count_dict[red_case] = red_rate.binomial_fun() for blue_case in blue_count_dict: blue_rate = binomial_class((blue_count_dict[blue_case] + 1),(row_count + 1),0.5) blue_count_dict[blue_case] = blue_rate.binomial_fun() sorted_red_count = sorted(red_count_dict.iteritems(),key=operator.itemgetter(1),reverse=True) sorted_blue_count = sorted(blue_count_dict.iteritems(),key=operator.itemgetter(1),reverse=True) print sorted_blue_count[0] print '选择红球是:' n = 1 for key,value in sorted_red_count: if n == 7: break print '%s,%s' %(key,str(value)) n += 1 print '选择蓝球是' print '%s,%s' %(sorted_blue_count[0][0],str(sorted_blue_count[0][1])) if __name__ == '__main__': n = '' while n != '1' or n != '2': input_n = raw_input(''' 请选择需要进行的功能 1、爬取页面的球号 2、进行球号分析 输入quit退出 请选择: ''') if input_n == '1': url = raw_input(''' 请输入需要爬取的地址(此为开始地址,因此建议选择页码较大的地址) 输入: ''') end_page = raw_input(''' 输入结束页码 (注意:如果结束页码大于输入地址的页码,则不会爬取任何页面) 输入: ''') ball_main(url,end_page) elif input_n == '2': analysis_main('2018-08-15','2018-09-09') elif input_n == 'quit': exit(0)
脚本共分两个功能块,一个是爬虫,用来爬取双色球号码,另一个是分析,使用二项分布对已抓取数据进行概率计算
先说说爬虫,依然是先观察页面
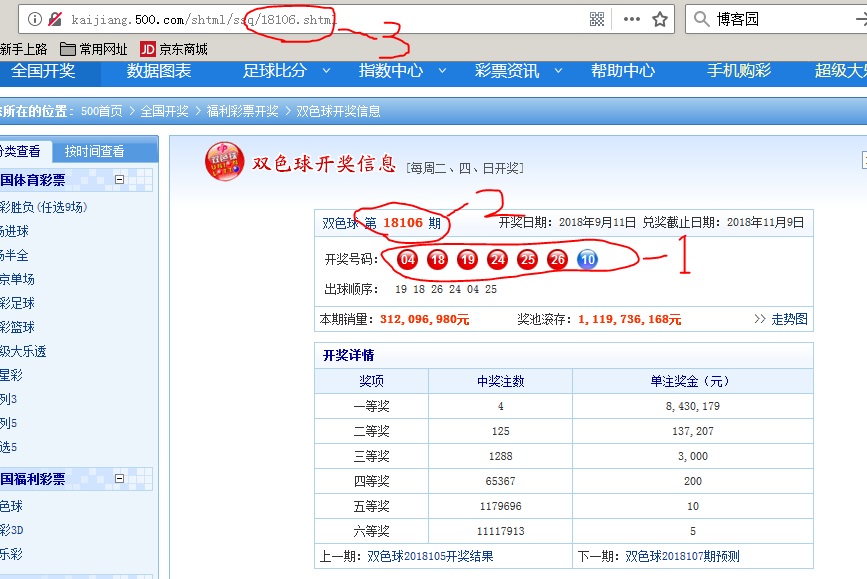
看过之前初级爬虫的同学应该对这个很熟悉,要爬的是1的地方,观察位置2和位置3,不难看出,每期占用一个页面,那么只要利用翻页,每次页码-1即可,下面看看1位置的源代码

在源码中搜索开奖号码,找到红圈位置,这个和伪代码中写的一样,现在看爬取正则
red_no_re = re.compile('(?<=\<li class\=\"ball_red\"\>)[0-9]+(?=\<\/li\>)')
blue_no_re = re.compile('(?<=\<li class\=\"ball_blue\"\>)[0-9]+(?=\<\/li\>)')
date_re = re.compile('(?<=开奖日期:)[0-9]+年[0-9]+月[0-9]+日')
分别爬取红球,篮球,日期
下面的事就好办了,将爬好的数据存入数据库,连接mysql,包含4个参数
db = 'pythondb'
host = 'localhost'
iuser = 'xxx'
passwd = 'xxxxxx'
分别是连接数据库、连接地址、用户名、密码
因为在每期开奖之后都需要爬一次新的号码,所以我没有把这个做成一次性的,用户需要输入开始爬取页面,以及结束页面编号,当爬取到结束编号页面后则停止
为防止重复爬入数据,导致数据库数据重复,因此在数据入库前需要对库数据进行验证需要入库数据是否已存在,详见check_open_date函数
最后需要注意的是,在写入完毕后应关闭数据库连接,因为mysql默认自动commit,因此我这个没有单独commit的sql,如果是oracle不要忘记加这个
接下来是分析模块,二项分布为方便管理,单独写了个类,以后也可以单独调用,这个用法我之前的文里面有说明,就不再说了。这里有几个功能说明下
1、与爬虫一样,分析也是需要写入开始日期和结束日期的,且从库中获取case必须大于7个,否则考虑样本不足,无法分析
2、将每个号码在时间段的出现频次进行统计并+1,即二项分布的成功k次数
3、获取时间段内的期数并+1,即二项分布的实验次数
4、因为每个号码只有两种可能,要么出现,要么不出现,因此事件的成功率是0.5

结果是这样,看到概率最高的是2.34863516114e-08,这是一个科学技术法,大约是0.00000002349,也就是1/5000万,因此这个概率没有任何意义,当然你也可以尝试买2块钱的,买不中别赖我啊,哈哈
细心的同学可能注意到了,算出来的最后两个红球概率是一样的,举个例子C(5,2)其实和C(5,3)的组合数是一样的,那么二项分布的概率当然也一样,这样就需要用到泊松分布,加入历史平均值的计算,因为这个需要在库中单独建表,还没有时间做这个事,因此没有加入这项计算,如果各位有兴趣可以自己尝试把这块加上,等我有时间了,我也会把这个写出来完善下的