把文件拖入IDA进行反编译。然后到main函数F5查看伪代码(IDA7.0版本不能查看伪代码,6.8版本可以)
代码非常好读懂,输入一个数然后处理,然后再与某个字符串对比,完全一样即为flag。

要对比的字符串存在dword_694060

dword为双字类型,即每32位为一个字符。又因为在参与运算时候为BYTE类型

所以只需要取第一个字节,共取25个形成处理后的flag字符串。

接下来就是过滤的事,将所有的操作取出,用脚本进行处理。逆运算即可得到答案。
python脚本:
import re
file_name = 'a.txt'
a=[]
b=""
with open(file_name) as file_obj:
for line in file_obj:
if 'byte_6941' in line: #过滤掉不含有byte_6941的运算
if '--' not in line and '++' not in line: #其中有的运算是以++,++开头,需要单独处理
a.append(re.findall(r"6941(.+?);",line.rstrip()))#用re的字符串过滤,来处理,即只取r6941到;中间的内容
else:
a.append(re.findall(r"(.+?);",line.rstrip()))#保留r6941,因为是++,--开头
c =[0xC0,0x85,0xF9,0x6C,0xE2,0x14,0xBB,0xe4,0xd,0x59,0x1c,0x23,0x88,0x6e,0x9b,0xca,0xba,0x5c,0x37,0xfff,0x48,0xd8,0x1f,0xab,0xa5]
for i in reversed(a): #逆取出,从后往前逆向运算。以下处理都是根据处理完后的字符打印出来,取出相应位置的数据进行处理
if i[0][2]=='+':
num1=int(i[0][13:],16)
c[num1]=c[num1]-1
elif i[0][2]=='-':
num1=int(i[0][13:],16)
c[num1]=c[num1]+1
elif i[0][3] =='+':
num1=i[0][:2]
if 'x' in i[0]:
num2=int(i[0][8:],16)
c[int(num1,16)]-=num2
else:
num2=int(i[0][6:],10)
c[int(num1,16)]-=num2
elif i[0][3] =='-':
num1=i[0][0:2]
if 'x' in i[0]:
num2=int(i[0][8:],16)
c[int(num1,16)]+=num2
else:
num2=int(i[0][6:],10)
c[int(num1,16)]+=num2
elif i[0][3] =='^':
num1=i[0][0:2]
if 'x' in i[0]:
num2=int(i[0][8:],16)
c[int(num1,16)]^=num2
else:
num2=int(i[0][6:],10)
c[int(num1,16)]^=num2
flag = ""
for i in c:
flag+=chr(i%128)
print(flag)其中处理的txt文件内容截取:
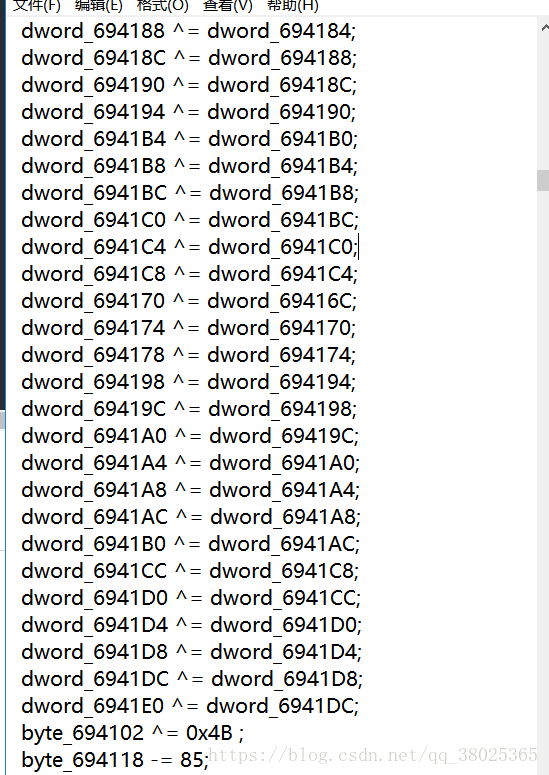
最终跑出来的答案:
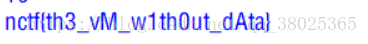
总结,题目本身不难,难点可能在数据量庞大,需要过滤处理。但是仍然不难