这个月是入职易流科技的第一个月,我被分到了易流云重构的项目组,易流云作为公司的核心项目,原先是使用.NET语言开发的,代码逻辑就我看来比较臃肿,数据库设计不完善,很多字段的使用已经和定义的时候大不相同了。现在公司想使用java重新做易流云,我们项目组就作为先锋军做本次易流云迭代开发的一个功能:设备地图。
项目是我们的架构师飞哥进行基础搭建的,我新进公司就分到飞哥手下。月初是我新进公司,我做了一些其他项目的开发,主要是伊利奶粉项目,开发了一个星期,主要做的是一些简单的业务逻辑整改和两个基础报表。
第二周我正式进入易流云项目,周一开了个会认识了一下新项目组的同事。介绍了新项目开发模式,和所用到的技术。用到的技术还是比较新的 spring cloud 基于 spring boot 1.5x(没有用2.0.x),使用fegin进行rpc通信。由于我上个月就简单学习了spring cloud相关技术,上手起来还是比较快的。当天就做完了项目分下来的用户自定义列的查询和保存的一个小接口。第二天例会上我向组长反映了我的进度。组长决定让我搭建一个基于spring boot 2.x的网关 使用 2.0 spring 官方新出的spring cloud gateway框架。作为易流云的网关,具体结构是这样的首先是用户请求通过Nginx 分配到gateway 网关,gateway网关再次做负载均衡 分配到monitor-web 再由 monitor-web 通过 rpc接口 调到 rpc接口实现的Controller 再调 数据库。我当天照着网上的例子简单实现了一个gateway网关,同时由于其他同事还在其他项目组有事,所有搭建ms-base项目的事我也顺手完成了。第二天,组长要求网关的路由是可以动态配置生效的,也就是说我本来访问/aa/bb 调的可能是base-monitor-web 现在项目已经启动了,要求我修改配置文件 让/aa/bb访问到 track-monitor-web。这就比较麻烦了,由于这个技术才发布几个月,网上的资料很少,而且我对这些内容的理解又很浅薄,spring cloud 都没有完全学明白。所以我就去看官方文档,发现可以通过在类上添加类似
@Bean //代码中手动配置route
public RouteLocator customRouteLocator(RouteLocatorBuilder builder) {
return builder.routes()
.route(
r -> r.path("/getAll")
.uri("http://localhost:8762")
)
.route(
r -> r.method("POST")
.uri("https://github.com")
)
.route(
r -> r.path("/kk/**").filters(
f -> f.stripPrefix(1)
)
.uri("lb://SERVICE-HI")
)
.build();
}这样的代码,手动配置路由。这就表示路由可以通过修改内存中已经注册好的路由来动态修改。这样就实现了动态路由。我发现RouteDefinition对象就能定义一个路由 RouteDefinitionWriter类里可以save路由,这代表我只要得到这个路由的内容,通过save方法就可以将我修改后的路由动态完成修改。照着这个思路,我实现了一个动态路由。但是这样的动态路由很不方便,他是通过spring cloud bus 通过rabbitMq 做了一个消息总线,修改配置文件来动态修改路由。每次修改完还要执行post bus操作,这时我问了组长,发现公司有apollo环境,(apollo可以管理配置文件,修改配置文件点击发布就触发apollo里的监控方法将新的配置文件内容推送过来)花了一天时间使用apollo实现了完整的动态路由配置。
第三周主要写了一个全局过滤器实现了判断用户是否有访问底层接口的功能。也就是一点业务。写起来很快,2天我就写完了整个业务内容。并进行了抽象重新整理代码结构。在组长的指导下,我完成了代码的效率优化。主要针对需要通过http访问接口查询的数据和读redis的内容进行了内存缓存。极大的提高了效率。下面我贴一个我自己实现的内存缓存类。
/**
* @Description uid缓存接口实现
* @Author [email protected]
* @Created Date: 2018/7/23 18:44
* @ClassName UidCacheServiceImpl
* @Version: 1.0
*/
@Service
public class UidCacheServiceImpl implements UidCacheService {
//初始化为静态变量,类加载即初始化
private static ConcurrentHashMap<String, UidAndTimestamp> uidMap = new ConcurrentHashMap<>();
//缓存uid
@Override
public void put(String token,Integer uid){
UidAndTimestamp uidAndTimestamp = uidMap.get(token);
if(uidAndTimestamp!=null && uidAndTimestamp.getUid()!=null){
uidAndTimestamp.setTimestamp(System.currentTimeMillis());
return;
}
uidAndTimestamp = new UidAndTimestamp();
uidAndTimestamp.setUid(uid);
uidAndTimestamp.setTimestamp(System.currentTimeMillis());
uidMap.put(token,uidAndTimestamp);
}
//通过token验证uid是否存在
@Override
public boolean checkUidIsExist(String token){
return uidMap.containsKey(token);
}
//根据token 获得uid
@Override
public Integer getUid(String token){
UidAndTimestamp uidAndTimestamp = uidMap.get(token);
if(uidAndTimestamp == null){
return null;
}
return uidAndTimestamp.getUid();
}
/**
* 定时删除超时数据
*/
@Scheduled(fixedRate = 5000)
public void DropUidByTimeStamp(){
for (Map.Entry<String, UidAndTimestamp> entry : uidMap.entrySet()) {
long timestamp = System.currentTimeMillis();
if(entry.getValue().getTimestamp() + 5000*10 < timestamp ){
uidMap.remove(entry.getKey());
}
}
}
/**
* 内部类封装 uid 和 时间戳
*/
static class UidAndTimestamp{
private Integer uid;
private Long timestamp;
public Integer getUid() {
return uid;
}
public void setUid(Integer uid) {
this.uid = uid;
}
public Long getTimestamp() {
return timestamp;
}
public void setTimestamp(Long timestamp) {
this.timestamp = timestamp;
}
}
}
以此实现了一种简单的内存缓存,五分钟内不访问就删除掉不再维护。
第四周在完成了gateway的开发的基础上,做了一个动态数据源的实现,在原本的代码中,需要对多数据源支持,每个数据源就要写两个类做多数据源配置,很麻烦类似于

这样,导致我们每次写一个新的数据源都要去写两个类。我们现在不想要这些内容,就要想办法把他干掉。这里发现了其中的规律
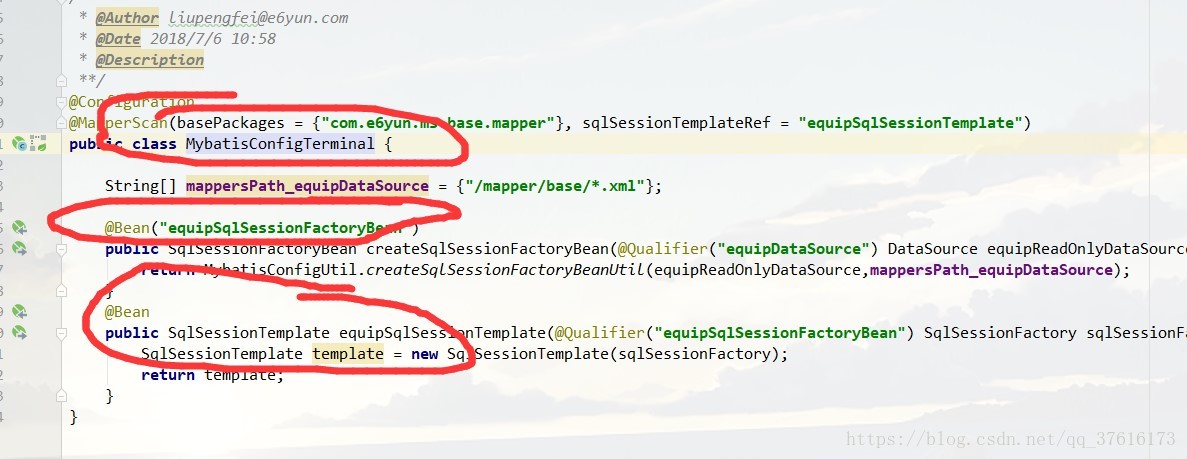
我只要向spring ioc中将下面的两个bean注入,再自定义实现MapperScan就能够自定义完成这个类的操作,jpa也是类似的内容。通过一个星期的努力最终实现了很不错的效果。(其中的痛苦就很多了,网上没有类似的案例,只能去看springbeanFactory的源码,和mybatis jpa的源码,用到了很多函数式变成的东西)

我只要在配置文件中这样写,动态多数据源配置就完成了,至此成功自己造了一个轮子。
本月是来公司的第一个月,带我的飞哥是一个对技术一丝不苟的人,很认真,所有的细节都不愿错过。而且希望我们实现的代码好用而且能够给别人用。所以他要求做的内容很慢,慢工出细活。这个月学到了非常多的东西,对spring ioc容器有了一个很深刻的理解,而且本月强迫自己看源码(不看源码任务就没法做了),学到了很多看源码的知识。总之这个月是一个好的开始,学习的内容非常多。