这篇文章最初出现在kasperfred(https://kasperfred.com/posts/the-future-of-deep-learning/)
在介绍Andrew NG关于这个话题,他谈到了在深度学习社区的两个趋势;规模和端到端的深度学习。
对大多数人来说,即使对深度学习有兴趣,规模也不会令人吃惊。在过去的10到20年里,我们获得了更多的数据。我们已经到达了一个点,几乎所有东西都以某种方式记录并存储在某个数据库中。同样,计算能力也在同期增加。可视化的一种方式是看游戏中的图形;20年前,DOOM 3D风靡一时,而现在却很难从CGI中分辨现实。

很多关于深学习的理论已经存在很长时间了,但是还没有足够的数据,也没有足够强大的计算机能让它成为可行的。事实上,直到最近,神经网络,和深度学习不认为是有效的,或实际可行的,与该领域今天没有相同的吸引力;很大程度上是因为他们当时不实用。
但是,计算能力的增加并不能解释为什么神经网络也可以伸缩,水平的(每层有多少神经元)和垂直的(有多少层)。
结果表明,一个神经网络有多大与它的规模有多大关系。小的神经网络倾向于只增加很少的计算能力,当更多的计算能力被添加,并且训练持续更多的纪元(1纪元是一个循环在所有训练数据)。而中等神经网络更多地受益于更多的计算能力。
不管神经网络变得多大,这种趋势似乎仍在继续,可以用下面的图表来描述:
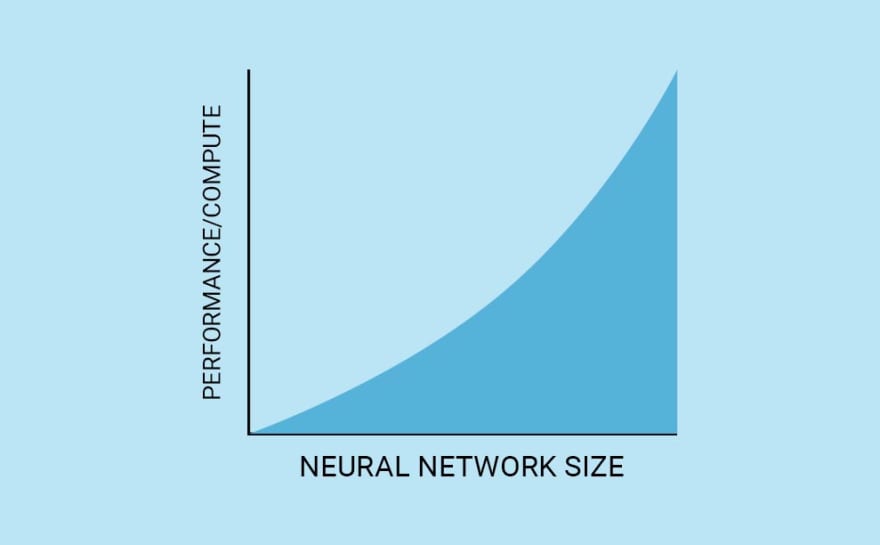
(图仅供说明用途,不作比例)
这种关系与可以编码到神经网络中的信息多少有关。但事实证明信息并没有那么多,这就是为什么他们倾向于概括大量数据,但这是另一回事。
此外,你的神经网络的深度和需要的宽度之间存在着一种松散的关系。作为一般的经验法则,您希望能够从顶部神经元绘制对角线到输出神经元之一。

鉴于大规模客户使用带来的巨大好处,许多消费产品现在都在使用深层学习,这一趋势很可能在不久的将来继续下去。
另一个主要趋势是端到端的深度学习。
传统上,机器学习模型会像二进制一样有一个简单的输出,例如,检查是正的还是负的?或者可能用物体识别一个整数,这是一只狗,一只猫还是一个人?
与端到端深入学习,你可以输出更复杂的东西。例如,直接从一个图像到一系列文本,描述图像中的内容,或者从音频直接转到文本记录。传统上,音频被分割成音素(声音的基本单位)。
另一个端到端深层学习有用的地方是机器翻译;直接从一种语言转到另一种语言。
然而,端到端的深度学习并不是解决一切问题的方法。例如,如果你想做一个模型,预测他们的手骨X线图像的一个人的年龄,使用一个端到端的策略是困难的;因为没有足够的数据。
深度学习的致命弱点是:你需要大量的标记数据。
虽然深度学习可能还不普及,因为只有当我们收集更多的标记数据时,端到端的深层学习很可能变得更广泛。
另一个端到端深度学习可能会产生很大影响的地方是自驾车。传统的方法是把图像作为输入,定位图像中的物体,找到轨迹,最后找到它应该引导的方向。端到端方法以图像作为输入,输出转向。
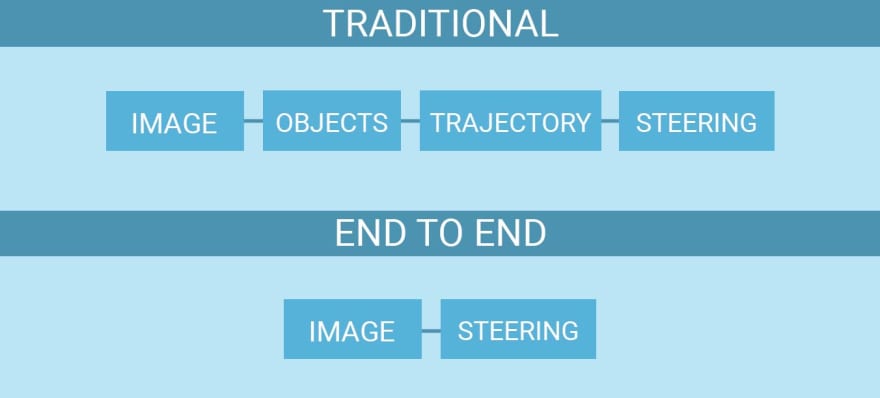
然而,到目前为止,还没有足够的数据能使端到端的深度学习驱动自驾车成为一种可行的技术。