前言
高并发场景越来越多的应用在互联网业务上。
本文将重点介绍悲观锁、乐观锁、Redis分布式锁在高并发环境下的如何使用以及优缺点分析。
本文相关的学习项目–抢红包,欢迎Star.
三种方式介绍
悲观锁
悲观锁,假定会发生并发冲突,在你开始改变此对象之前就将该对象给锁住,直到更改之后再释放锁。
其实,悲观锁是一种利用数据库内部机制提供的锁的方法,也就是对更新的数据进行加锁。这样在并发期间一旦有一个事务持有了数据库记录的锁,其他的线程将不能再对数据进行更新了,这就是悲观锁的实现方式。
悲观锁的实现方式: SQL + FOR UPDATE
<!--悲观锁-->
<select id="getRedPacketForUpdate" parameterType="int" resultType="com.demo.entity.RedPacket">
select id, user_id as userId, amount, send_date as sendDate, total, unit_amount as unitAmount,
stock, version, note
from t_red_packet
where
id = #{id} for update
</select>根据加锁的粒度,当对主键查询进行加锁时,意味着将持有对数据库记录的行更新锁(因为这里使用主键查询,所以只会对行加锁。如果使用的是非主键查询,要考虑是否对全表加锁的问题,加锁后可能引发其他查询的阻塞〉,那就意味着在高并发的场景下,当一条事务持有了这个更新锁才能往下操作,其他的线程如果要更新这条记录,都需要等待,这样就不会出现超发现象引发的数据一致性问题了。
对于悲观锁来说,当一条线程抢占了资源后,其他的线程将得不到资源,那么这个时候, CPU 就会将这些得不到资源的线程挂起,挂起的线程也会消耗CPU 的资源,尤其是在高井发的请求中。
一旦线程l 提交了事务,那么锁就会被释放,这个时候被挂起的线程就会开始竞争资源,那么竞争到的线程就会被CPU 恢复到运行状态,继续运行。
于是频繁挂起,等待持有锁线程释放资源,一旦释放资源后,就开始抢夺,恢复线程,周而复始直至所有红包资源抢完。试想在高并发的过程中,使用悲观锁就会造成大量的线程被挂起和恢复,这将十分消耗资源,这就是为什么使用悲观锁性能不佳的原因。有些时候,我们也会把悲观锁称为独占锁,毕竟只有一个线程可以独占这个资源,或者称为阻塞锁,因为它会造成其他线程的阻塞。无论如何它都会造成并发能力的下降,从而导致CPU频繁切换线程上下文,造成性能低下。为了克服这个问题,提高并发的能力,避免大量线程因为阻塞导致CPU进行大量的上下文切换,程序设计大师们提出了乐观锁机制,乐观锁已经在企业中被大量应用了。
乐观锁。
乐观锁是一种不会阻塞其他线程并发的机制,它不会使用数据库的锁进行实现,它的设计里面由于不阻塞其他线程,所以并不会引发线程频繁挂起和恢复,这样便能够提高井发能力,所以也有人把它称为非阻塞锁。

它的实现思路是,在更新时会判断其他线程在这之前有没有对数据进行修改,一般用版本号机制。
读取出数据时,将此版本号一同读出,之后更新时,对此版本号加一。此时,将提 交数据的版本数据与数据库表对应记录的当前版本信息进行比对,如果提交的数据 版本号大于数据库表当前版本号,则予以更新,否则认为是过期数据。
<!--乐观锁-->
<update id="decreaseRedPacketByVersion">
update t_red_packet
set
stock = stock - 1,
version = version + 1
where
id = #{id}
and version = #{version}
</update>但是,仅仅这样是不行的,在高并发的情景下,由于版本不一致的问题,存在大量红包争抢失败的问题。为了提高抢红包的成功率,我们加入重入机制。
重入机制
- 按时间戳重入(比如100ms时间内)
示例代码:
// 记录开始的时间
long start = System.currentTimeMillis();
// 无限循环,当抢包时间超过100ms或者成功时退出
while(true) {
// 循环当前时间
long end = System.currentTimeMillis();
// 如果抢红包的时间已经超过了100ms,就直接返回失败
if(end - start > 100) {
return FAILED;
}
....
}- 按次数重入(比如3次机会之内)
示例代码:
// 允许用户重试抢三次红包
for(int i = 0; i < 3; i++) {
// 获取红包信息, 注意version信息
RedPacket redPacket = redPacketDao.getRedPacket(redPacketId);
// 如果当前的红包大于0
if(redPacket.getStock() > 0) {
// 再次传入线程保存的version旧值给SQL判断,是否有其他线程修改过数据
int update = redPacketDao.decreaseRedPacketByVersion(redPacketId, redPacket.getVersion());
// 如果没有数据更新,说明已经有其他线程修改过数据,则继续抢红包
if(update == 0) {
continue;
}
....
}
...
}
这样就可以消除大量的请求失败,避免非重入的时候大量请求失败的场景。
Redis
我们知道当数据量非常大时,频繁的存取数据库,对于数据库的压力是非常大的。这时我们可以采用缓存技术,利用Redis的轻量级、便捷、快速的机制解决高并发问题。
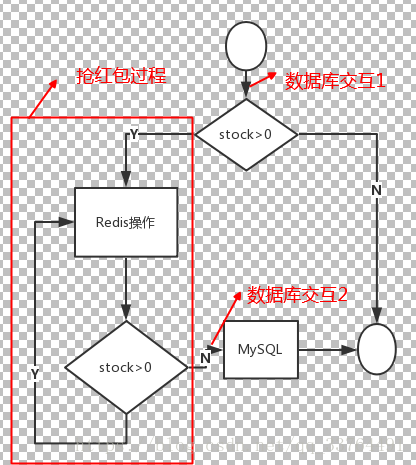
通过流程图,我们看到整个流程与数据库交互只有两次,用户抢红包操作的过程其实都是在Redis中完成的,这显然提高了效率。
但是如何解决数据不一致带来的超发问题呢?
分布式锁
通俗的讲,分布式锁就是说,缓存中存入一个值(key-value),谁拿到这个值谁就可以执行代码。
在并发环境下,我们通过锁住当前的库存,来确保数据的一致性。知道信息存入缓存、库存-1之后,我们再重新释放锁。
为了防止死锁的发生,可以设置锁的过期时间来解决。
- 加锁
// 先判断缓存中是否存在值,没有返回true,并保存value,已经有值就不保存,返回false
if(stringRedisTemplate.opsForValue().setIfAbsent(key, value)) {
return true;
}
String curentValue = stringRedisTemplate.opsForValue().get(key);
// 如果锁过期
if(!StringUtils.isEmpty(curentValue) && Long.parseLong(curentValue) < System.currentTimeMillis()) {
// getAndSet设置新值,并返回旧值
// 获取上一个锁的时间
String oldValue = stringRedisTemplate.opsForValue().getAndSet(key, value);
if(!StringUtils.isEmpty(curentValue) && oldValue.equals(curentValue)) {
return true;
}
}
return false;- 解锁
try {
String currentValue = stringRedisTemplate.opsForValue().get(key);
if(!StringUtils.isEmpty(currentValue) && currentValue.equals(value)) {
stringRedisTemplate.opsForValue().getOperations().delete(key);
}
} catch (Exception e) {
logger.error("RedisLock 解锁异常:" + e.getMessage());
}总结
悲观锁使用了数据库的锁机制,可以消除数据不一致性,对于开发者而言会十分简单,但是,使用悲观锁后,数据库的性能有所下降,因为大量的线程都会被阻塞,而且需要有大量的恢复过程,需要进一步改变算法以提高系统的井发能力。
使用乐观锁有助于提高并发性能,但是由于版本号冲突,乐观锁导致多次请求服务失败的概率大大提高,而我们通过重入(按时间戳或者按次数限定)来提高成功的概率,这样对于乐观锁而言实现的方式就相对复杂了,其性能也会随着版本号冲突的概率提升而提升,并不稳定。使用乐观锁的弊端在于, 导致大量的SQL被执行,对于数据库的性能要求较高,容易引起数据库性能的瓶颈,而且对于开发还要考虑重入机制,从而导致开发难度加大。
使用Redis去实现高并发,消除了数据不一致性,并且在整个过程中尽量少的涉及数据库。但是这样使用的风险在于Redis的不稳定性,因为其事务和存储都存在不稳定的因素,所以更多的时候,建议使用独立Redis服务器做高并发业务,一方面可以提高Redis的性能,另一方面即使在高并发的场合,Redis服务器岩机也不会影响现有的其他业务,同时也可以使用备机等设备提高系统的高可用,保证网站的安全稳定。
以上讨论了3 种方式实现高并发业务技术的利弊,妥善规避风险,同时保证系统的高可用和高效是值得每一位开发者思考的问题。