版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/Hanani_Jia/article/details/82498469
今天在刷剑指offer的时候遇到了sort函数然后并不是很懂,所以简单的看了一下发现东西还是很多的,这里简单给大家总结一下我理解的一些东西。

首先看一些基础的就是sort函数的用法,我们在cplusplus网站上可以查一下sort的用法,这里有一个默认用法和一个扩展的用法,可以看出来两种用法传入的参数个数是不相同的,默认的函数我们传入了两个参数,通过英文也能看出来他的两个参数一个是要数组的起始位置,一个是终止位置。这里我们拿一下cplusplus上边的例子可以看一下。

可以看出来这里的第一个参数就是我们的数组的begin也就是起始位置,第二个位置是起始位置+4,所以排序过后只有前4个数字进行了排序。所以我们可以通过这两个参数来控制我们想要排序的部分。这个很好理解。
但是扩展之后的sort虽然不是很复杂但是不太好理解。

这是官网对参数部分的介绍,这里我们看cmp,他说这是一个二进制的函数他接受范围内的两个参数也就是你在比较的时候操作的两个数字,并且这个函数的返回类型必须是bool型的,返回值的指示作为第一个参数传递的元素是否被看成他它定义的特定严格弱排序中位于第二个参数之前。这里其实我认为就是你返回一个bool值如果是说你返回了true说明这是真的sort就不操作了,如果是假的sort就要将这两个数字的位置进行一下交换,并且这个函数是不能在函数内部对我们传入的参数进行修改的,这里就算解开了我的疑惑,明明我们在调用这个函数的时候是没有参数传入的,但是他的函数确实需要两个参数并且还没有报错。原因就在这里。
sort是STL库中的一个函数,并且这个函数的底层实现是经常被问到的问题很多人认为sort就是通过我们的快速排序来实现的,但实际上并不是只有快速排序这么简单。
#include <algorithm>
template< class RandomIt > void sort( RandomIt first, RandomIt last );
template< class RandomIt, class Compare > void sort( RandomIt first, RandomIt last, Compare comp );一种就是我们上边说到的默认的,这种他的比较函数默认的是<也就是说是升序进行排序的。还有一种就是我们上边用到的自己定义比较函数。他比我们自己写的快速排序效率是要高很多,速度快很多。
因为我们学快速排序的时候都知道,我们的快速排序是需要一个中间值的,如果这个中间值选的不好选的比较极端没有将你的数据划分开很有可能就将自己的快速排序的时间复杂度变成了O(n2),所以就有了我们的三值取中法,我们头部、尾部还有中间值三个数值中间大下的那个数据当做我们的枢纽。
David R.Musser于1996年提出一种混合式排序算法:Introspective Sorting(内省式排序),简称IntroSort,其行为大部分与上面所说的median-of-three Quick Sort完全相同,但是当分割行为有恶化为二次方的倾向时,能够自我侦测,转而改用堆排序,使效率维持在堆排序的 O(nlgn),又比一开始就使用堆排序来得好。
我们看一下STL中sort的源码
template <class _RandomAccessIter>
inline void sort(_RandomAccessIter __first, _RandomAccessIter __last) {
__STL_REQUIRES(_RandomAccessIter, _Mutable_RandomAccessIterator);
__STL_REQUIRES(typename iterator_traits<_RandomAccessIter>::value_type,
_LessThanComparable);
if (__first != __last) {
__introsort_loop(__first, __last,
__VALUE_TYPE(__first),
__lg(__last - __first) * 2);
__final_insertion_sort(__first, __last);
}
}其中,__introsort_loop便是上面介绍的内省式排序,其第三个参数中所调用的函数__lg()便是用来控制分割恶化情况。代码如下:
template <class Size>
inline Size __lg(Size n) {
Size k;
for (k = 0; n > 1; n >>= 1) ++k;
return k;
}也就是意味着我们的递归是最多递归到2*lg(n)层。
内省式排序的代码如下
template <class _RandomAccessIter, class _Tp, class _Size>
void __introsort_loop(_RandomAccessIter __first,
_RandomAccessIter __last, _Tp*,
_Size __depth_limit)
{
while (__last - __first > __stl_threshold) {
if (__depth_limit == 0) {
partial_sort(__first, __last, __last);
return;
}
--__depth_limit;
_RandomAccessIter __cut =
__unguarded_partition(__first, __last,
_Tp(__median(*__first,
*(__first + (__last - __first) / 2),
*(__last - 1))));
__introsort_loop(__cut, __last, (_Tp*)0, __depth_limit);
__last = __cut;
}
}-
这里进来之后会首先进行判断元素是否大于__stl_threshold,__stl_threshold是一个常量值是16,意思就是说我传入的元素规模小于我们的16的时候我们就没必要采用我们的内省式算法,直接退回去采用我们的插入排序。
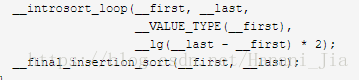
这里能看到我们的内省式算法结束之后就是我们的插入排序函数。
2.如果说我们的元素规模大于我们的16了,那就需要去判断如果我们是不是能采用快速排序,怎么判断呢?快排是使用递归来实现的,如果说我们进行判断我们的递归深度没有到达我们的最深层次上边的函数已经看过了,最深是2*lg(n)。那我们就去使用我们的快速排序来进行排序
template <class _RandomAccessIter, class _Tp>
_RandomAccessIter __unguarded_partition(_RandomAccessIter __first,
_RandomAccessIter __last,
_Tp __pivot)
{
while (true) {
while (*__first < __pivot)
++__first;
--__last;
while (__pivot < *__last)
--__last;
if (!(__first < __last))
return __first;
iter_swap(__first, __last);
++__first;
}
}