腾讯AI Lab主导提出一种新的视频再定位方法,能在多个备选视频中快速找到希望搜索的片段。该研究论文被顶级会议ECCV 2018收录,以下是技术详细解读。
ECCV(European Conference on Computer Vision,计算机视觉欧洲大会)将于 9 月 8 日-14 日在德国慕尼黑举办,该会议与 CVPR、ICCV 共称为计算机视觉领域三大顶级学术会议,每年录用论文约 300 篇。AI Lab 是第二次参与该会议,录取文章数高达 19 篇,位居国内前列。在刚结束的计算机视觉领域另外两大会议 CVPR,ICCV 中也收获颇丰,分别录取 21 篇和 7 篇论文。
■ 论文 | Video Re-localization
■ 链接 | https://www.paperweekly.site/papers/2272
■ 作者 | Yang Feng / Lin Ma / Wei Liu / Tong Zhang / Jiebo Luo
该研究由腾讯 AI Lab 主导,与美国罗切斯特大学(University of Rochester)合作完成,研究目的是在给定一个欲搜索的视频后,在某个备选视频中,快速找到与搜索视频语义相关的片段,这在视频处理研究领域仍属空白。
因此本文定义了一个新任务——视频再定位(Video Re-localization),重组 ActivityNet 数据集视频,生成了一个符合研究需求的新数据集,并提出一种交叉过滤的双线性匹配模型,实验已证明了其有效性。
目前应用最广泛的视频检索方法是基于关键字的视频检索,这种检索方法依赖人工标记,而人工标记不能涵盖视频的所有内容。基于内容的视频检索(CBVR)可以克服上述不足,但是 CBVR 方法一般返回完整的视频,并不会返回具体的相关内容的位置。行为定位(Action Localization)方法可以定位到具体行为在视频当中发生的位置,但是这类方法一般只能定位某些具体的行为类别。

▲ 图1:一段查询视频(上)和两段备选视频(中、下)。与查询视频相关的片段已经用绿色方框标出。
图 1 当中有三段视频,当给定图 1 中的查询视频之后,如何在两个备选视频当中找到与查询视频语义相关的片段?
已有的视频处理方法并不能很好的解决这个问题。比如,视频拷贝检测(Video Copy Detection)方法只能检测同一段视频出现的不同位置,拷贝检测不能处理图 1 当中的场景变化和动作角色变化的情况。另外,也很难用行为定位方法来解决这个问题,因为训练行为定位的模型需要大量的行为样本数据,在图 1 的例子当中,我们只有一个数据样本。
思路
为了解决这类问题,我们定义了一项新的任务,任务的名字是视频再定位。在给定一段查询视频和一段备选视频之后,视频再定位的目标是快速的在备选视频当中定位到与查询视频语义相关的视频片段。
要解决视频再定位问题,面临的第一个困难是缺少训练数据。虽然目前有很多视频数据集,但是它们都不适合视频再定位研究。训练视频再定位模型,需要成对的查询视频和备选视频,并且备选视频当中需要有和查询视频语义相关的片段,相关片段的起始点和终止点也需要标注出来。

收集这样的训练数据费时费力。为了得到训练数据,我们决定重新组织现有的数据集,来生成一个适合视频再定位研究的新数据集。经过调研,我们决定使用 ActivityNet 数据集当中的视频,来构建新数据集。
ActivityNet 数据集当中包含 200 类行为,我们认为同一个类别下的两个行为片段是互相语义相关的。在 ActivityNet 数据集当中,每类行为的样本被划分到训练集,验证集和测试集。因为视频再定位并不局限在一些特定的类别,这种划分并不适合视频再定位任务。
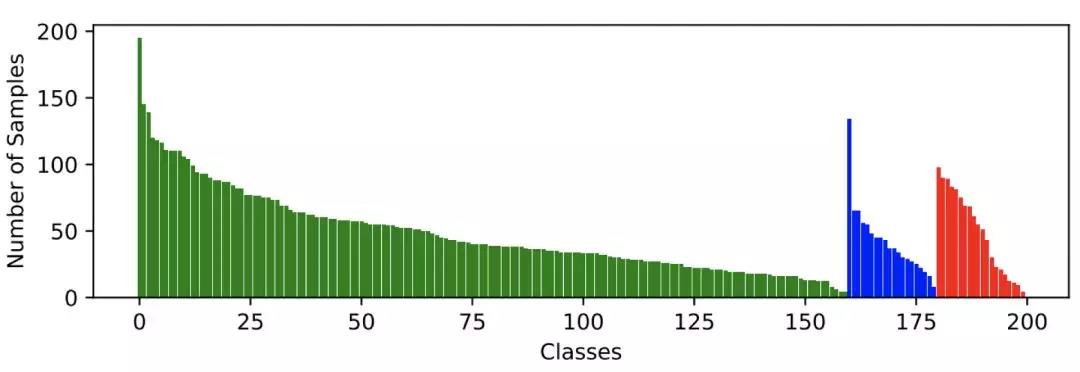
▲ 图2:本文构建的数据集当中,每类行为当中的视频样本个数。绿色,蓝色和红色分别表示训练,验证和测试用的视频。
标题
为了解决视频再定位问题,我们提出了一种交叉过滤的双线性匹配模型。对于给定一段查询视频以及一段备选视频,我们首先分别对查询视频和备选视频进行特征提取,然后将查询视频使用注意力机制合并成一个特征向量用于与备选视频匹配。匹配的时候,我们过滤掉不相关的信息,提取相关的信息,然后用双向 LSTM 来生成匹配结果。最后,我们把匹配结果整合,输出预测的起始点和终止点的概率。
接下来,我们着重介绍模型中具有创新性的交叉过滤机制*,双向性匹配机制,以及定位层*。
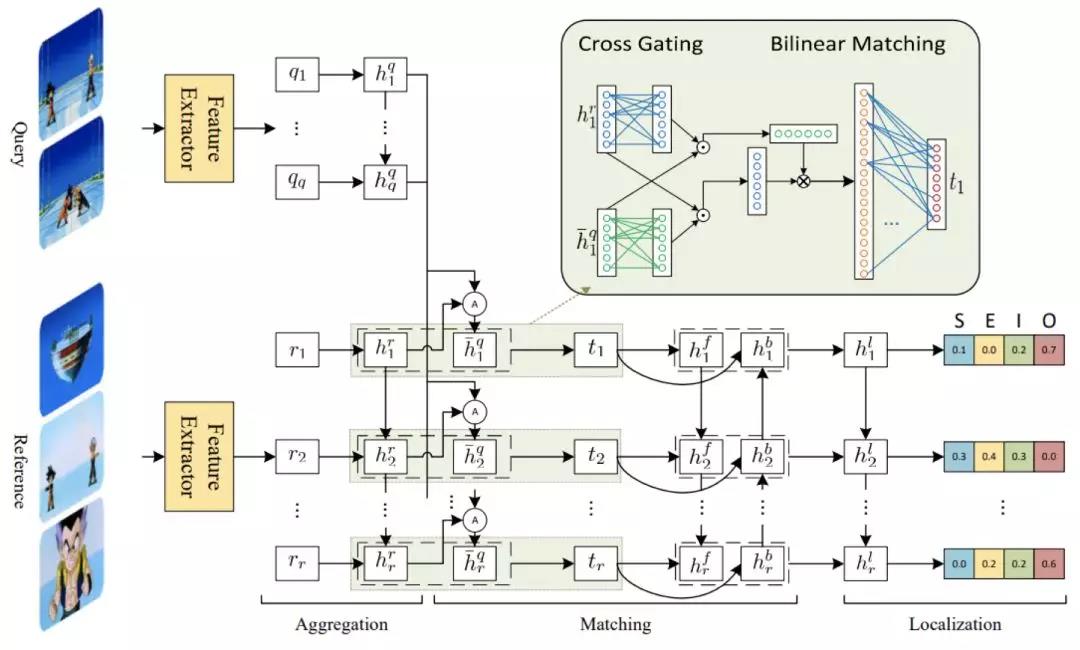
▲ 图3:模型的框架图
交叉过滤(Cross Gating)
因为在备选视频当中有很多我们不关心的内容,所以在匹配的过程当中,我们需要一种过滤机制来去除不相关的内容。我们根据当前的查询视频的特征,来生成一个过滤门,用来过滤备选视频。相应的,我们根据备选视频的特征,来生成另外一个过滤门,来过滤查询视频。
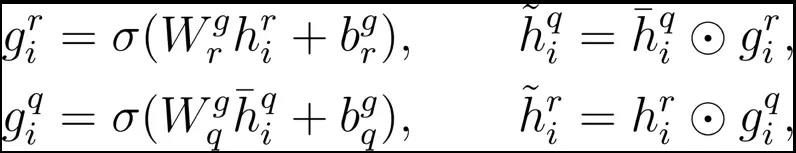
这里的 表示sigmoid函数, 表示对对应位相乘, 是模型参数。 分别是备选视频和查询视频的特征表示。
双线性匹配(Bilinear Matching)
在得到查询视频和备选视频的特征表示之后,传统的方法将他们拼接到一起,然后输入到神经网络来计算匹配结果。直接的拼接的方法,并不能很好的得到视频中相关的内容,所以我们采用双线性匹配的方法来代替拼接,来更加全面的获取视频的相关内容。
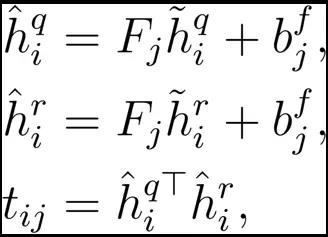
上式中, 是模型的参数。
定位层(Localization)
根据视频匹配结果,我们来预测备选视频当中每个时间点是开始点和结束点的概率。除此之外,我们还预测了一个时间点是在相关视频片段之内或者不在相关视频片段之内的概率。
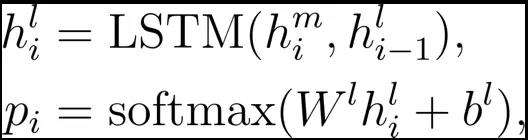
其中,
是LSTM的隐含状态,
是模型的参数,
是上一层匹配得到的结果。在预测的时候,我们选择联合概率最大的视频片段。
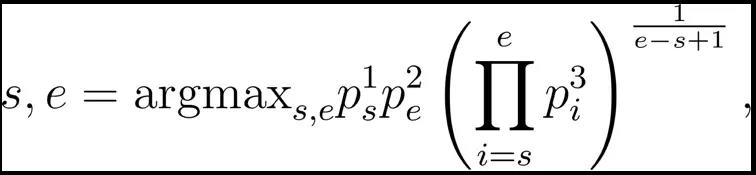
其中, 是第s个时间点是视频片段的起始点的概率, 是第e个时间点是视频片段的终止点的概率, 是第i个时间点是视频片段中的一个时间点的概率。
实验
在实验当中,我们设计了三种基线方法。第一个基线方法根据视频帧之间的相似度,计算两个视频片段的相关程度。第二个基线方法把每个视频编码成一个特征向量,然后用特征向量的距离表示两段视频的相关程度。第三个基线方法没有使用查询视频,仅根据备选视频选择最有可能包含行为的视频片段。
在新构建的数据集上定位的定量结果如表 1 所示。另外,一些定性的结果如图 4 所示。可以看到我们提出的方法取得的较优的定位结果。
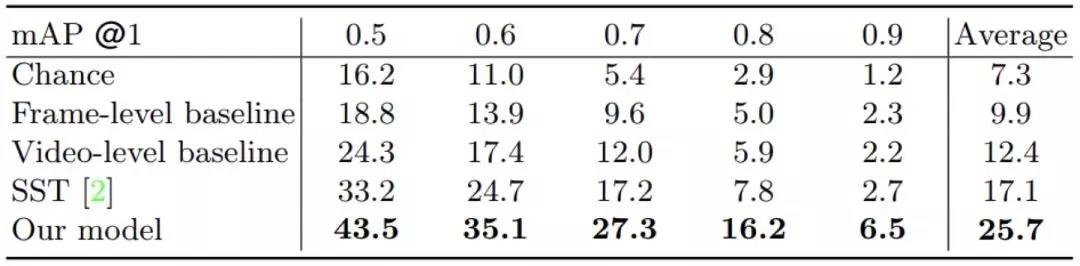
▲ 表1. 不同方法的定位结果

▲ 图4. 定性结果