Table of Contents
前言
我们通过pip命令可以下载所需要的模块,但是一个一个下载非常麻烦。推荐使用Anaconda,Anaconda的使用教程以及安装教程请阅读下面的文章写的非常详细。
这里可以学习安装并使用 Anaconda
学会了使用Anaconda再学习一下代码编辑器 jupyter notebook。
这里有pycharm 如何使用 Anaconda的环境 pycharm结合Anaconda
上述遇到的问题总结:
安装完Anaconda以后先配置一下国内的镜像,否则后续更新包会因为网速太慢而导致更新失败,配置国内镜像
如果在 Anaconda中 更新包的时候出现下面的错误
CondaError: Cannot link a source that does not exist. D:\ancoda\Scripts\conda.exe
Running `conda clean --packages` may resolve your problem.有可能是因为你还没有安装pip命令
conda install pip安装以后再次更新就不会出现问题了。
如果你的Anaconda启动失败,如下图所示
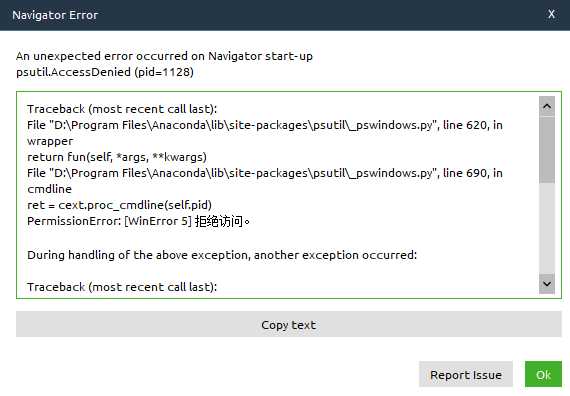
1)使用管理员运行:conda prompt
2)执行命令 conda update anaconda-navigator
3)还是不行就试试命令:anaconda-navigator --reset
在pycharm中配置Project Interpreter时,要选择Existing environment,然后找到Anaconda根目录的python.exe文件,这个是Anacoda的默认环境,即附带很多包。如果你在pycharm中自己新建了一些模块,则需要找到模块文件夹下的python.exe
如下,我自己建的环境Pillow 放在了 Anacoda根目录下的 envs 文件夹下

设置成功后就可以在pycharm中使用该环境下的相关包了。
上述学习完毕以后,我们再开始进入第三方模块的学习。
Pillow
更改图片长宽以及加模糊滤镜
# -*- coding: utf-8 -*-
from PIL import Image, ImageFilter
# 打开图片,返回一个图片对象
im = Image.open(r'D:\image\1.jpg')
# 获取图片长宽
w, h = im.size
print('Original image size: %sx%s' % (w, h))
# 将图片对象的 长和宽 缩小50%
im.thumbnail((w//2, h//2))
print('Resize image to: %sx%s' % (w//2, h//2))
# 增加模糊滤镜效果
im.filter(ImageFilter.BLUR)
# 将图片对象 以jpeg格式存入硬盘
im.save(r'D:\image\thumbnail1.jpg', 'jpeg')
效果如下
原图

加模糊滤镜

长宽缩小 50%

绘制验证码
# -*- coding: utf-8 -*-
from PIL import Image, ImageDraw, ImageFont, ImageFilter
import random
# 随机字母 大写字母 A~Z
def rndChar():
return chr(random.randint(65, 90)) # Ascii码65代表A,90代表Z
# 随机颜色1:
def rndColor():
return (random.randint(64, 255),random.randint(64, 255),random.randint(64, 255))
# 随机颜色2:
def rndColor2():
return (random.randint(32, 127),random.randint(32, 127),random.randint(32, 127))
width = 240
height = 60
# 创建验证码图片,RGB是一种设置颜色的方式,255代表最亮即白色
# 即生成一个图片背景色是白色 宽240 高60
image = Image.new('RGB', (width, height), (255, 255, 255))
# 创建Font对象(设置验证码上的字体以及字体大小)
font = ImageFont.truetype(r'C:\Windows\Fonts\Arial.ttf', 36) # C:\Windows\Fonts 有很多字体
# 创建Draw对象(画笔,指定画在哪个图片上)
draw = ImageDraw.Draw(image)
# 填充每个像素,就是给之前的白色图片上色
for x in range(width):
for y in range(height):
draw.point((x, y), fill=rndColor())
# 输出文字,参数1字与字间隙,参数2 字内容,参数3 字体,参数4 字颜色
for t in range(4):
draw.text((60 * t + 10, 10), rndChar(), font=font, fill=rndColor2())
# 模糊:
image = image.filter(ImageFilter.BLUR)
image.save(r'D:\image\code.jpg', 'jpeg')效果图

由于图片中每一个像素的时候都调用一次rndColor函数,所以背景色是花的,而文字是每写一个字换一次颜色。
requests
这个模块是urllib的一个升级版,功能更强大,使用更加方便
get请求
# coding=utf8
import requests
# params 代表get请求传递的参数,如果没有参数 则不用写 params
r = requests.get('https://www.douban.com/search', params={'q':'python', 'cat':'1001'})
print('状态码:', r.status_code)
print('实际请求的RUL:', r.url)
print('页面编码:', r.encoding)
print('Cookie:\n%s' % r.cookies['bid'])
print('响应头:', r.headers)
print('页面源码byte类型:\n%s' % r.content)
print('页面源码 :', r.text)
状态码: 200
实际请求的RUL: https://www.douban.com/search?q=python&cat=1001
页面编码: utf-8
Cookie:
7sXlaVSRPLo
响应头: {'Date': 'Sun, 09 Sep 2018 09:00:26 GMT', 'Content-Type': 'text/html; charset=utf-8', 'Transfer-Encoding': 'chunked', 'Connection': 'keep-alive', 'Keep-Alive': 'timeout=30', 'Vary': 'Accept-Encoding', 'X-Xss-Protection': '1; mode=block', 'X-Douban-Mobileapp': '0', 'Expires': 'Sun, 1 Jan 2006 01:00:00 GMT', 'Pragma': 'no-cache', 'Cache-Control': 'must-revalidate, no-cache, private', 'Set-Cookie': 'bid=efAbYQs59iE; Expires=Mon, 09-Sep-19 09:00:26 GMT; Domain=.douban.com; Path=/', 'X-DOUBAN-NEWBID': 'efAbYQs59iE', 'X-DAE-Node': 'beleg2', 'X-DAE-App': 'bywater', 'Server': 'dae', 'Strict-Transport-Security': 'max-age=15552000;', 'Content-Encoding': 'gzip'}
页面源码byte类型:
b'<!DOCTYPE html>\n<html lang="zh-cmn-Hans" class="">\n<head>\n <meta http-equiv="Content-Type" content="text/html; charset=utf-8">\n <meta name="renderer"
...
页面源码 : <!DOCTYPE html>
<html lang="zh-cmn-Hans" class="">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
<meta name="renderer" content="webkit">
<meta name="referrer" content="always">
<meta name="google-site-verification" content="ok0wCgT20tBBgo9_zat2iAcimtN4Ftf5ccsh092Xeyw" />
<title>
搜索: python
</title>
...
要在请求中传入Cookie,只需准备一个dict传入cookies参数:
>>> cs = {'token': '12345', 'status': 'working'}
>>> r = requests.get(url, cookies=cs)
最后,要指定超时,传入以秒为单位的timeout参数:
>>> r = requests.get(url, timeout=2.5) # 2.5秒后超时Post请求
设置Request Header,模拟手机向服务器发送请求
r = requests.get('https://www.douban.com/', headers={'User-Agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit'})
print('手机版页面源码:%s' % r.text)
手机版页面源码:
<!DOCTYPE html>
<html itemscope itemtype="http://schema.org/WebPage">
<head>
<meta charset="UTF-8">
<title>豆瓣(手机版)</title>
<meta name="google-site-verification" content="ok0wCgT20tBBgo9_zat2iAcimtN4Ftf5ccsh092Xeyw" />
<meta name="viewport" content="width=device-width, height=device-height, user-scalable=no, initial-scale=1.0, minimum-scale=1.0, maximum-scale=1.0">
<meta name="format-detection" content="telephone=no">
<link rel="canonical" href="
http://m.douban.com/">
<link href="https://img3.doubanio.com/f/talion/de3978c284c5726b87e5c53db054821e1e849397/css/card/base.css" rel="stylesheet">
<meta name="description" content="读书、看电影、涨知识、学穿搭...,加入兴趣小组,获得达人们的高质量生活经验,找到有相同爱好的小伙伴。">
<meta name="keywords" content="豆瓣,手机豆瓣,豆瓣手机版,豆瓣电影,豆瓣读书,豆瓣同城">
....post请求传递参数
1: date
下面是输入完用户名、密码向豆瓣服务器发送的登录请求,传递的参数写在data后面。
requests默认使用application/x-www-form-urlencoded对POST数据编码。
r = requests.post('https://accounts.douban.com/login', data={'form_email': ' ', 'form_password': ' '})
2: json
params = {'key': 'value'}
r = requests.post(url, json=params) # 内部自动序列化为JSON3: files
>>> upload_files = {'file': open('report.xls', 'rb')}
>>> r = requests.post(url, files=upload_files)
在读取文件时,注意务必使用'rb'即二进制模式读取,这样获取的bytes长度才是文件的长度。
把post()方法替换为put(),delete()等,就可以以PUT或DELETE方式请求资源。
爬取图片的一个小案例
import requests, re
# 第一步 先获取爬的网址
# 第二步 用正则表达式来匹配不同图片的url
# 第三步 找到每张图片的链接
def get_urls():
# 获取网址
response = requests.get('http://qq.yh31.com/zjbq/2920180.html')
# 用正则表达式匹配不同的图片url , 共有的内容保留 border = 0
url_add = r'<img border="0" .*? src="(.*?)"'
# 找到每张图片的链接
url_list = re.findall(url_add, response.text)
# 将图片地址列表返回
return url_list
# 下载目标网页的数据
def get_gif(url, name):
# 拿到图片的地址
response = requests.get(url)
# 把图片保存到D:\image\qq
with open('D:\image\qq\%d.gif' % a, 'wb') as ft:
ft.write(response.content)
if __name__ == '__main__':
url_list = get_urls()
# 把列表当中的数据提取 并拼接这个url
# 定义一个变量 ,给图片命名
a = 1
for url in url_list:
com_url = 'http://qq.yh31.com%s' % url
# 调用下载图片的函数并传递拼接好的链接
get_gif(com_url, a)
a += 1效果如下

chardet
chardet.detect 可以查看一个byte类型的数据是以哪种形式进行编码的
import chardet
print(chardet.detect(b'Hello,world!'))
print(chardet.detect('天王盖地虎,小鸡炖蘑菇'.encode('gbk')))
print(chardet.detect('你好,世界!'.encode('utf-8')))
print(chardet.detect('ニュース'.encode('euc-jp')))结果如下
{'encoding': 'ascii', 'confidence': 1.0, 'language': ''}
{'encoding': 'GB2312', 'confidence': 0.7407407407407407, 'language': 'Chinese'}
{'encoding': 'utf-8', 'confidence': 0.9690625, 'language': ''}
{'encoding': 'EUC-JP', 'confidence': 0.99, 'language': 'Japanese'}
encoding 代表 编码
confidence 代表准确率
language 代表语言
要注意一下gbk编码,如果文字较少,python无法猜测出编码,如下
print(chardet.detect('你好,世界!'.encode('gbk')))
{'encoding': None, 'confidence': 0.0, 'language': None}psutil
能够查看各种系统信息
# coding=utf8
import psutil
print(psutil.cpu_count()) # CPU逻辑处理器数量
print(psutil.cpu_count(logical=False)) # CPU物理核心数
print(psutil.cpu_times()) # 统计CPU的用户/系统/空闲时间
for x in range(10): # CPU使用率,每秒刷新一次,累计10次
print(psutil.cpu_percent(interval=1, percpu=True))
print(psutil.virtual_memory()) # 获取物理内存信息
print(psutil.swap_memory()) # 获取内存交换区信息
print(psutil.disk_partitions()) # 磁盘分区信息
print(psutil.disk_usage('/')) # 磁盘使用情况
print(psutil.disk_io_counters()) # 磁盘IO
print(psutil.net_io_counters()) # 获取网络读写字节/包的个数
print(psutil.net_if_addrs()) # 获取网络接口信息
print(psutil.net_if_stats()) # 获取网络接口状态
print(psutil.net_connections()) # 获取当前网络连接信息
print(psutil.pids()) # 所有进程ID
p = psutil.Process(792) # 获取指定进程ID=3776,其实就是当前Python交互环境
print(p.name()) # 进程名称
print(p.exe()) # 进程 exe路径
print(p.cwd()) # 进程工作目录
print(p.cmdline()) # 进程启动命令行
print(p.ppid()) # 父进程ID
print(p.parent()) # 父进程
print(p.children()) # 子进程列表
print(p.status()) # 进程状态
print(p.create_time()) # 进程创建时间
print(p.terminal()) # 进程终端
print(p.cpu_times()) # 进程使用的CPU时间
print(p.memory_info()) # 进程使用的内存
print(p.open_files()) # 进程打开的文件
print(p.connections()) # 进程相关网络连接
print(p.num_threads()) # 进程的线程数量
print(p.threads()) # 所有线程信息
print(p.environ()) # 进程环境变量
print(p.terminate()) # 结束进程
上面的代码有可能会出现错误,如下
Traceback (most recent call last):
...
PermissionError: [Errno 1] Operation not permitted
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
...
psutil.AccessDenied: psutil.AccessDenied (pid=3847) 你可能会得到一个AccessDenied错误,原因是psutil获取信息也是要走系统接口,而获取网络连接信息需要root权限,这种情况下,可以退出Python交互环境,在linux中用sudo重新启动,在windows,使用管理员权限打开。
psutil还提供了一个test()函数,可以模拟出ps命令的效果:
