项目相关要求
- 基本功能
- 统计C语言源文件的字符数(完成)
- 统计C语言源文件的词的数目(完成)
- 统计C语言源文件的行数(完成)
- 拓展功能
- 递归处理目录下符合条件的文件(完成)
- 返回更复杂的数据(代码行 / 空行 / 注释行)(完成)
- 高级功能
- 实现图形界面(待完成)
首先,我们需要明确一下“字符”,“词”,“行”,“代码行”,“空行”,“注释行”的定义。
字符:一个ASCII字符,包括控制字符和可打印字符。
词:一个由空白字符(不仅指空格,还指'\f','\v','\n','\r'这些控制字符)分隔的非空字符串。
行:一个由换行符分隔的字符串,可以为空。一行结束的标志是换行符。
代码行:本行包括多于一个字符的代码。
空行:本行全部是空格或格式控制字符,如果包括代码,则只有不超过一个可显示的字符,例如“{”。
注释行:本行不是代码行,并且本行包括注释。
以上代码行、空行、注释行的说明摘自项目说明。
为了消除歧义,特提出以下补充说明:
1.项目说明指出了下面第一行是注释行,类似的,第二行和第三行也是项目行。
} //注释
{ //注释
; //注释2.按照定义,下面这一行是代码行,但不是注释行。
printf("Hello, world"); //say "Hello, world"3.按照定义,第一行是代码行,但不是注释行。第二行和第三行是注释行。
printf("Hello, world"); /*say "Hello, world"
*/4.第二行不是空白行。第一行到第三行都是注释行。
/* The next line is a comment line.
*/思路
对于字符数的统计,每读取一个字符,让chracters加一即可。
对于词数的统计,需要一个标记,用于记录前面一个字符是不是空白字符,假如前面一个字符是空白字符且当前字符是可显示字符,那么让words加一。
对于行数的统计,每读取到一个换行符,让lines加一即可。
对于空白行、代码行、注释行的统计,需要用到一个块注释标记和一些正则表达式,具体如下:
bool blockCommentFlag = false;
string blankLineRegex = "(\\s*)([{};]?)(\\s*)";
string lineCommentRegex = "(\\s*)([{};]?)(\\s*)(//)(.*)";
string blockCommentStartFlagRegex = "(\\s*)([{};]?)(\\s*)(/{1})(\\*{1})(.*)";
string blockCommentStartFlag1Regex = "(.*)(/{1})(\\*{1})(.*)";
string blockCommentCloseFlagRegex = "(.*)(\\*{1})(/{1})(\\s*)";- 每读取一行,首先需要判断当前行是不是位于块注释中,假如是,让注释行加一,否则进行2
- 使用blankLineRegex这个正则表达式判断当前行是不是空白行,假如是,让空白行加一,否则进行3
- 使用lineCommentRegex判断当前行是不是行注释,假如是,让注释行加一,否则进行4
- 使用blockCommentStartFlagRegex判断当前行是不是含有块注释开始的标志且为注释行,假如是,把blockCommentFlag改为true,并将注释行加一,否则进行5
- 使用blockCommentStartFlag1Regex判断当前行是不是含有块注释开始的标志且为代码行,假如是,把blockCommentFlag改为true,并将代码行加一,否则进行6
- 假如以上情况都不是,那么说明该行是代码行,让代码行加一,并结束该行的判断
设计
File类:
- 变量:
characters, words, lines, blankLines, codeLines, commentLines. - 方法:
countBasic:统计字符数、词数、行数。countSpecialLines:统计空白行、代码行、注释行。print:输出统计结果。
setMode函数:根据输入参数设置模式。
readFile函数:处理一个文件。
recursiveReadFiles函数:处理一个目录。

主要流程就是读取命令行参数,然后调用setMode设置参数,接着根据对象是文件还是目录,分别调用readFile或recursiveReadFiles。
readFile接着又会调用countBasic和countSpecialLines,执行程序的核心部分,进行统计。接着调用print输出结果。
关键代码
1.统计字符、词、行
void countBasic(FILE *pFile) {
char c;
bool spaceFlag = true;
while((c = fgetc(pFile)) != EOF) {
characters++;
words += (spaceFlag == true && isgraph(c));
spaceFlag = isspace(c);
lines += c == '\n';
}
}2.统计空白行、代码行、注释行
/* 要确定一行是不是空白行,只要通过判断该行的可打印字符个数是否不超过1个即可。另外还要注意,该行不能在块注释中。
* 要确定一行是不是代码行,只要判断该行的可打印字符个数是否超过1个即可。另外还要注意,改行不在块注释中。
* 假如一行是注释行,那么该行首先必须不是代码行,其次,需要有注释标志。
* 根据以上信息,可写出正则表达式进行匹配。
*/
void countSpecialLines() {
string line;
ifstream file(fileName);
bool blockCommentFlag = false;
string blankLineRegex = "(\\s*)([{};]?)(\\s*)";
string lineCommentRegex = "(\\s*)([{};]?)(\\s*)(//)(.*)";
string blockCommentStartFlagRegex = "(\\s*)([{};]?)(\\s*)(/{1})(\\*{1})(.*)";
string blockCommentStartFlag1Regex = "(.*)(/{1})(\\*{1})(.*)";
string blockCommentCloseFlagRegex = "(.*)(\\*{1})(/{1})(\\s*)";
while (getline(file, line)) { if(blockCommentFlag) {
commentLines++;
if(regex_match(line, regex(blockCommentCloseFlagRegex))) {
blockCommentFlag = false;
}
}
else if(regex_match(line, regex(blankLineRegex))) {
blankLines++;
}
else if(regex_match(line, regex(lineCommentRegex))) {
commentLines++;
}
else if(regex_match(line, regex(blockCommentStartFlagRegex))) {
commentLines++;
blockCommentFlag = true;
}
else if(regex_match(line, regex(blockCommentStartFlag1Regex))) {
codeLines++;
blockCommentFlag = true;
}
else {
codeLines++;
}
}
file.close();
}3.根据参数输出统计结果,注意输出顺序是有规律的,依次为字符数 词数 行数 空白行数 代码行数 注释行数。
void print(map<char, bool> mode) {
if(mode['c'])
printf("%6d", characters);
if(mode['w'])
printf("%6d", words);
if(mode['l'])
printf("%6d", lines);
if(mode['a'])
printf("%6d%6d%6d", blankLines, codeLines, commentLines);
putchar('\n');
}测试报告
首先我制作了几个经典的测试样例以及对应的参考统计结果,另外,为了节省测试时间,我还写了一个脚本来进行自动化测试。
假如所有的测试样例都通过了,则会提示ok,如下:

假如有些样例没有通过,则会提示wrong,并指出错在哪里,如下:
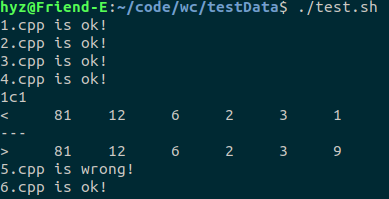
我构造的测试样例及测试结果如下:
- 空文件

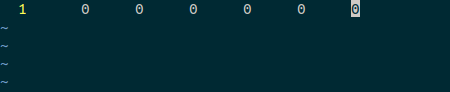
这里输出的依次是字符数、词数、行数、空行数、代码行数、注释行数。下面的也一样。 - 一个字符的文件


- 一个单词的文件

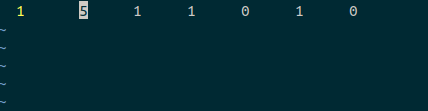
- 一行的文件
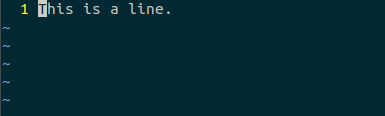
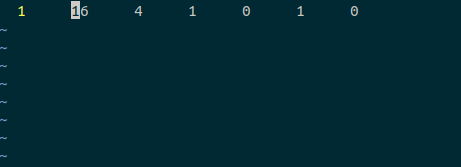
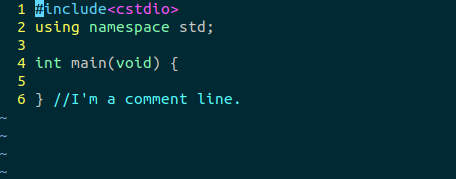
- 典型的C源文件
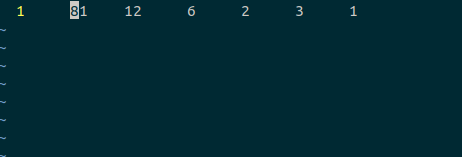
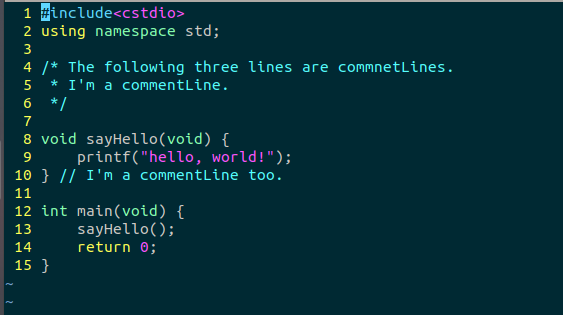
- 另一个典型的C源文件

除了测试这些样例,我还测试了非法输入的情况,如下:
- 没有输入参数

- 参数非法

- 文件或目录不存在

- 在未输入s参数的情况下查询目录

拓展功能的查询更复杂信息和查询目录的测试:
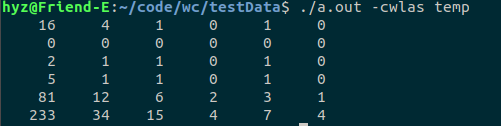
代码覆盖率(Todo)
遇到的困难及解决方法
- 之前很少用C++写与文件操作相关的代码,所以对于实现-s这个参数的时候无从下手,最后,通过搜索引擎,查阅官方文档和他人的博客,学习到了新知识,顺利地解决了这个问题。
- 实现-a这个参数,需要统计空行、代码行、注释行。一开始,我的想法是逐个读取字符,进行相关变量的更新,并进行状态转化。但是,这样实现的话,会需要很多的标记,让代码晦涩难懂。而且由于这个状态机的状态很多,状态之间的转化也相当复杂。所以,最后我放弃了这种实现方式,改用正则表达式来实现,这样会简单很多。这启发我,在具体实现前,最好先比较一下各种实现方式的难易程度,再选择一种比较容易的来写。
PSP
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 25 | 50 |
| · Estimate | · 估计这个任务需要多少时间 | 25 | 50 |
| Development | 开发 | 525 | 600 |
| · Analysis | · 需求分析 (包括学习新技术) | 75 | 75 |
| · Design Spec | · 生成设计文档 | 25 | 0 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 0 | 0 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 25 | 0 |
| · Design | · 具体设计 | 25 | 50 |
| · Coding | · 具体编码 | 325 | 425 |
| · Code Review | · 代码复审 | 25 | 25 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 25 | 25 |
| Reporting | 报告 | 100 | 100 |
| · Test Report | · 测试报告 | 50 | 50 |
| · Size Measurement | · 计算工作量 | 25 | 25 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 25 | 25 |
| 合计 | 650 | 750 |
总结
一开始没有认真分析需求,没有想好就开始动手编码实现,中途停停顿顿,浪费了不少时间。从上面的PSP也可以看出,我花了很少时间在“生成设计文档”、“设计复审”、“代码规范”这三个环节上,导致我后面“具体编码”的环节花的时间比预估的时间长了很多。后来,我重新阅读了项目文件,明确了需求,并进行了相关设计,然后就实现得比较顺利了。这启发我,在开始动手编码前,应该先想好思路,并设计好模块,磨刀不误砍柴工嘛。



