该环境适合于学习使用的快速Spark环境,采用Apache预编译好的包进行安装。而在实际开发中需要使用针对于个人Hadoop版本进行编译安装,这将在后面进行介绍。
Spark预编译安装包下载——Apache版
下载地址:http://spark.apache.org/downloads.html (本例使用的是Spark-2.2.0版本)
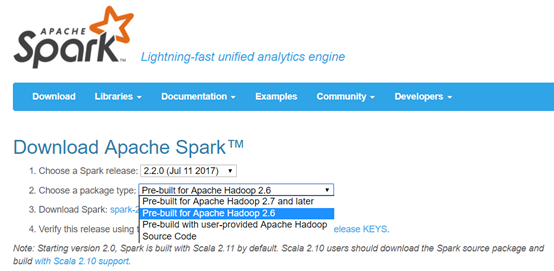
接下来依次执行下载,上传,然后解压缩操作。
[hadoop@masternode ~]$ cd /home/hadoop/app
[hadoop@masternode app]$ rz //上传
选中刚才下载好的Spark预编译好的包,点击上传。
[hadoop@masternode app]$ tar –zxvf spark-2.2.0-bin-hadoop2.6.tgz //解压
[hadoop@masternode app]$ rm spark-2.2.0-bin-hadoop2.6.tgz
[hadoop@masternode app]$ mv spark-2.2.0-bin-hadoop2.6/ spark-2.2.0 //重命名
[hadoop@masternode app]$ ll
total 24
drwxrwxr-x. 7 hadoop hadoop 4096 Aug 23 16:32 elasticsearch-2.4.0
drwxr-xr-x. 10 hadoop hadoop 4096 Apr 20 13:59 hadoop
drwxr-xr-x. 8 hadoop hadoop 4096 Aug 5 2015 jdk1.8.0_60
drwxrwxr-x. 11 hadoop hadoop 4096 Nov 4 2016 kibana-4.6.3-linux-x86_64
drwxr-xr-x. 12 hadoop hadoop 4096 Jul 1 2017 spark-2.2.0
drwxr-xr-x. 14 hadoop hadoop 4096 Apr 19 10:00 zookeeper
[hadoop@masternode app]$ cd spark-2.2.0/
[hadoop@masternode spark-2.2.0]$ ll
total 104
drwxr-xr-x. 2 hadoop hadoop 4096 Jul 1 2017 bin
drwxr-xr-x. 2 hadoop hadoop 4096 Jul 1 2017 conf
drwxr-xr-x. 5 hadoop hadoop 4096 Jul 1 2017 data
drwxr-xr-x. 4 hadoop hadoop 4096 Jul 1 2017 examples
drwxr-xr-x. 2 hadoop hadoop 12288 Jul 1 2017 jars
-rw-r--r--. 1 hadoop hadoop 17881 Jul 1 2017 LICENSE
drwxr-xr-x. 2 hadoop hadoop 4096 Jul 1 2017 licenses
-rw-r--r--. 1 hadoop hadoop 24645 Jul 1 2017 NOTICE
drwxr-xr-x. 6 hadoop hadoop 4096 Jul 1 2017 python
drwxr-xr-x. 3 hadoop hadoop 4096 Jul 1 2017 R
-rw-r--r--. 1 hadoop hadoop 3809 Jul 1 2017 README.md
-rw-r--r--. 1 hadoop hadoop 128 Jul 1 2017 RELEASE
drwxr-xr-x. 2 hadoop hadoop 4096 Jul 1 2017 sbin
drwxr-xr-x. 2 hadoop hadoop 4096 Jul 1 2017 yarn
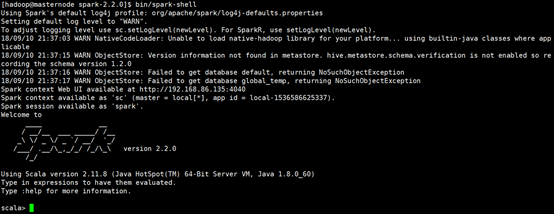
如图所示,可以进入Spark Shell模式,表示安装正常。
Spark目录介绍
1.bin 运行脚本目录
beeline find-spark-home load-spark-env.sh //加载spark-env.sh中的配置信息,确保仅会加载一次 pyspark //启动python spark shell,./bin/pyspark --master local[2] run-example //运行example spark-class //内部最终变成用java运行java类 sparkR spark-shell //启动scala spark shell,./bin/spark-shell --master local[2] spark-sql
spark-submit //提交作业到master
运行example
# For Scala and Java, use run-example:
./bin/run-example SparkPi
# For Python examples, use spark-submit directly: ./bin/spark-submit examples/src/main/python/pi.py # For R examples, use spark-submit directly: ./bin/spark-submit examples/src/main/r/dataframe.R2.conf
docker.properties.template fairscheduler.xml.template log4j.properties.template //集群日志模版 metrics.properties.template slaves.template //worker 节点配置模版 spark-defaults.conf.template //SparkConf默认配置模版 spark-env.sh.template //集群环境变量配置模版
3.data (例子里用到的一些数据)
graphx
mllib
streaming
4.examples 例子源码
jars
src
5.jars (spark依赖的jar包)
6.licenses (license协议声明文件)
7.python
8.R
9.sbin (集群启停脚本)
slaves.sh //在所有定义在${SPARK_CONF_DIR}/slaves的机器上执行一个shell命令
spark-config.sh //被其他所有的spark脚本所包含,里面有一些spark的目录结构信息
spark-daemon.sh //将一条spark命令变成一个守护进程
spark-daemons.sh //在所有定义在${SPARK_CONF_DIR}/slaves的机器上执行一个spark命令
start-all.sh //启动master进程,以及所有定义在${SPARK_CONF_DIR}/slaves的机器上启动Worker进程
start-history-server.sh //启动历史记录进程
start-master.sh //启动spark master进程
start-mesos-dispatcher.sh
start-mesos-shuffle-service.sh
start-shuffle-service.sh
start-slave.sh //启动某机器上worker进程
start-slaves.sh //在所有定义在${SPARK_CONF_DIR}/slaves的机器上启动Worker进程
start-thriftserver.sh
stop-all.sh //在所有定义在${SPARK_CONF_DIR}/slaves的机器上停止Worker进程
stop-history-server.sh //停止历史记录进程
stop-master.sh //停止spark master进程
stop-mesos-dispatcher.sh
stop-mesos-shuffle-service.sh
stop-shuffle-service.sh
stop-slave.sh //停止某机器上Worker进程
stop-slaves.sh //停止所有worker进程
stop-thriftserver.sh
10.yarn
spark-2.1.1-yarn-shuffle.jar
Spark example
下面运行一个官网的小example。
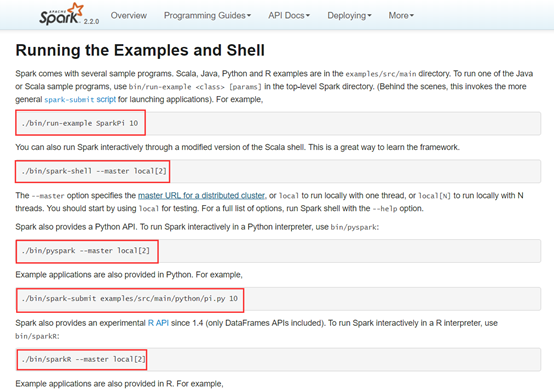
可以看到官网给出了详细的运行指令,我们运行第一个,算一下Pi的值。
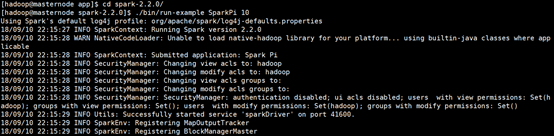
运算结果如下图所示:
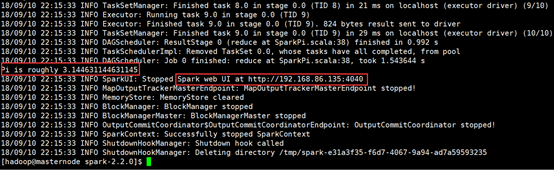
并且,如上图所示,我们可以根据图中URL地址查看web UI情况。

注意:此地址只能是在运行过程中才能查看的哦!