std::async 就像是一个异步函数调用。
std::async 之下呢是一个task,非常好用的task。
std::async
std::async 使用一个 callable 作为一个工作包。
在本例中,它可以是个函数、函数对象或者匿名函数。
// async.cpp
#include <future>
#include <iostream>
#include <string>
std::string helloFunction(const std::string& s) {
return "Hello C++11 from " + s + ".";
}
class HelloFunctionObject {
public:
std::string operator()(const std::string& s) const {
return "Hello C++11 from " + s + ".";
}
};
int main() {
std::cout << std::endl;
// 带函数的future
auto futureFunction = std::async(helloFunction, "function");
// 带函数对象的future
HelloFunctionObject helloFunctionObject;
auto futureFunctionObject = std::async(helloFunctionObject, "function object");
// 带匿名函数的future
auto futureLambda = std::async([](const std::string& s) {return "Hello C++11 from " + s + "."; }, "lambda function");
std::cout << futureFunction.get() << "\n"
<< futureFunctionObject.get() << "\n"
<< futureLambda.get() << std::endl;
std::cout << std::endl;
}程序执行结果:
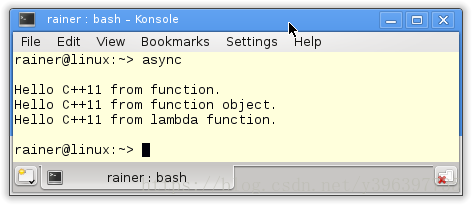
future 获得了一个函数(第23行), 一个函数对象(第27行) 和一个匿名函数(第30行)。
最后, 每个future 都获取到了返回值(第32行).
再说的稍微正式点:
std::async在第23,27,30行的调用在两端的future和promise创建了一个数据通道。
promise立即开始执行它的工作包,那是它的默认行为。
通过future的get()调用,future收到了它的工作包的返回结果。
Eager or lazy evaluation(急速或惰性求值)
Eager or lazy evaluation(急速或惰性求值) 是计算表达式结果的两种策略。
- 在急速求值的情况下,将立即计算评估表达式。
- 在惰性求值的情况下,只会在需要的情况下评估表达式。
通常惰性求值被称为call-by-need,按需调用。
懒惰求值可以节省时间和计算能力,因为没有对不确定因素的评估(because there is no evaluation on suspicion)。
表达式可以是数学计算、函数或std::async调用。
通常情况下, std::async 立即开始执行它的工作包。
C++运行时决定, 计算是发生在同一个线程还是一个新的线程。
使用std::launch::async参数的话,std::async 将在一个新线程中运行它的工作包。
相反,使用参数 std::launch::deferred, std::async将在同一个线程中运行它的工作包。 这种情况下属于惰性求值。
这意味着,急速求值是立即执行的,但是惰性求值的策略std::launch::deferred是随着future调用get()后才开始执行。
下面的程序显示了它们行为的区别:
// asyncLazy.cpp
#include <chrono>
#include <future>
#include <iostream>
int main() {
std::cout << std::endl;
auto begin = std::chrono::system_clock::now();
auto asyncLazy = std::async(std::launch::deferred, [] { return std::chrono::system_clock::now(); });
auto asyncEager = std::async(std::launch::async, [] { return std::chrono::system_clock::now(); });
std::this_thread::sleep_for(std::chrono::seconds(1));
auto lazyStart = asyncLazy.get() - begin;
auto eagerStart = asyncEager.get() - begin;
auto lazyDuration = std::chrono::duration<double>(lazyStart).count();
auto eagerDuration = std::chrono::duration<double>(eagerStart).count();
std::cout << "asyncLazy evaluated after : " << lazyDuration << " seconds." << std::endl;
std::cout << "asyncEager evaluated after: " << eagerDuration << " seconds." << std::endl;
std::cout << std::endl;
}第13至15行都调用了std::async,并且都是返回当前时间点。
但是第一个调用是惰性的,第二个是急速的(greedy)。
在第17行的睡眠1秒,使得程序显而易见了。
第19行的asyncLazy.get()调用,结果在一个短暂的打盹后才能获得。
asyncEager就不一样了,asyncEager.get()立即获取到工作包的返回值。

一个规模大的计算任务
std::async很方便,把更多的计算工作放在更多的肩上来承担。
下面例子中演示了四个异步调用对标积的计算。
// dotProductAsync.cpp
#include <chrono>
#include <iostream>
#include <future>
#include <random>
#include <vector>
#include <numeric>
static const int NUM = 100000000;
long long getDotProduct(std::vector<int>& v, std::vector<int>& w) {
auto future1 = std::async([&] {return std::inner_product(&v[0], &v[v.size() / 4], &w[0], 0LL); });
auto future2 = std::async([&] {return std::inner_product(&v[v.size() / 4], &v[v.size() / 2], &w[v.size() / 4], 0LL); });
auto future3 = std::async([&] {return std::inner_product(&v[v.size() / 2], &v[v.size() * 3 / 4], &w[v.size() / 2], 0LL); });
auto future4 = std::async([&] {return std::inner_product(&v[v.size() * 3 / 4], &v[v.size()], &w[v.size() * 3 / 4], 0LL); });
return future1.get() + future2.get() + future3.get() + future4.get();
}
int main() {
std::cout << std::endl;
// 从 0 到 100 获取 NUM 个随机数
std::random_device seed;
// 生成随机数
std::mt19937 engine(seed());
// 0~100之间均匀分配
std::uniform_int_distribution<int> dist(0, 100);
// 放进 vector 容器
std::vector<int> v, w;
v.reserve(NUM);
w.reserve(NUM);
for (int i = 0; i < NUM; ++i) {
v.push_back(dist(engine));
w.push_back(dist(engine));
}
// 计算执行时间
std::chrono::system_clock::time_point start = std::chrono::system_clock::now();
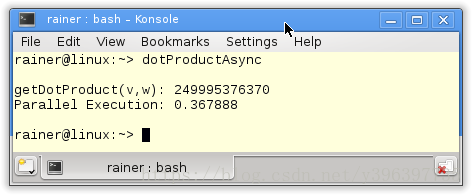
std::cout << "getDotProduct(v,w): " << getDotProduct(v, w) << std::endl;
std::chrono::duration<double> dur = std::chrono::system_clock::now() - start;
std::cout << "Parallel Execution: " << dur.count() << std::endl;
std::cout << std::endl;
}
程序解释:
程序使用了随机和时间库的功能,库都是C++11的一部分。
在第27~43行,创建了2个vector容器v,w,各放入100万个值(第 40 ~ 43 行)。
第41和42行的dist(engine)生成随机数,均匀分布在0~100之间。
当前的标积的计算在函数getDotProduct中 (第 12 ~ 20行)。
std::async使用内部标准模板库的算法std::inner_product。
最后将各future的值加起来返回。
在我的PC上大约花了0.4秒来计算结果。
现在问题是,那要是一核的情况下执行,程序运行需要多久呢?
稍微修改程序getDotProduct,我们就知道结果了:
long long getDotProduct(std::vector<int>& v,std::vector<int>& w){
return std::inner_product(v.begin(),v.end(),w.begin(),0LL);
}
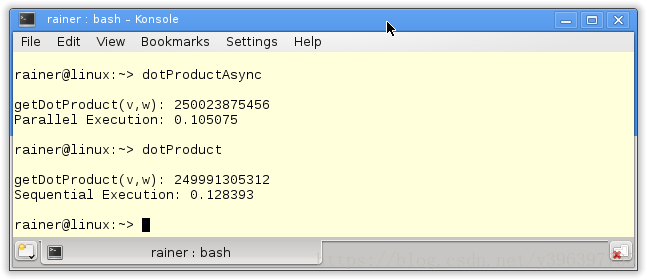
程序的执行速度慢了四倍。
优化
但是,如果我使用我的GCC以最大优化级别O3编译程序,性能差异几乎消失了,并行执行的速度提高了约10%。
原文地址:
http://www.modernescpp.com/index.php/asynchronous-function-calls