Implement strStr().
Return the index of the first occurrence of needle in haystack, or -1 if needle is not part of haystack.
Example 1:
Input: haystack = "hello", needle = "ll"
Output: 2
Example 2:
Input: haystack = "aaaaa", needle = "bba"
Output: -1
Clarification:
What should we return when needle is an empty string? This is a great question to ask during an interview.
For the purpose of this problem, we will return 0 when needle is an empty string. This is consistent to C's strstr() and Java's indexOf().
方法一:Brute-Force
class Solution {
public:
int strStr(string haystack, string needle) {
if (needle.size() > haystack.size())
return -1;
int needle_len = needle.length();
int res = -1;
if (needle_len == 0)
return 0;
for (int i = 0; i < haystack.length() - needle_len + 1; ++i) {
if (haystack[i] == needle[0]) {
int j = 0;
for (; j < needle_len; ++j) {
if (haystack[i + j] != needle[j]) {
res = -1;
break;
}
}
if (j == needle_len) {
res = i;
return res;
}
}
}
return res;
}
};
时间复杂度:O(mn),m是主串的长度,n是子串的长度
方法二:KMP
时间复杂度:O(m+n),m是主串的长度,n是子串的长度.
构建next数组的时间复杂度和空间复杂度均是O(n)
搜索的时间复杂度为O(m)
视频教程:https://www.bilibili.com/video/av3246487?from=search&seid=16469755573504001954
参考资料:https://www.zhihu.com/question/21923021
https://github.com/mission-peace/interview/blob/master/src/com/interview/string/SubstringSearch.java
KMP算法的核心,是一个被称为部分匹配表(Partial Match Table)的数组。我觉得理解KMP的最大障碍就是很多人在看了很多关于KMP的文章之后,仍然搞不懂PMT中的值代表了什么意思。这里我们抛开所有的枝枝蔓蔓,先来解释一下这个数据到底是什么。
首先解释一下字符串的前缀和后缀。如果字符串A和B,存在A=BS,其中S是任意的非空字符串,那就称B为A的前缀。例如,”Harry”的前缀包括{”H”, ”Ha”, ”Har”, ”Harr”},我们把所有前缀组成的集合,称为字符串的前缀集合。同样可以定义后缀A=SB, 其中S是任意的非空字符串,那就称B为A的后缀,例如,”Potter”的后缀包括{”otter”, ”tter”, ”ter”, ”er”, ”r”},然后把所有后缀组成的集合,称为字符串的后缀集合。要注意的是,字符串本身并不是自己的后缀和前缀。
有了这个定义,就可以说明PMT中的值的意义了。PMT中的值是字符串的前缀集合与后缀集合的交集中最长元素的长度。例如,对于”aba”,它的前缀集合为{”a”, ”ab”},后缀 集合为{”ba”, ”a”}。两个集合的交集为{”a”},那么长度最长的元素就是字符串”a”了,长 度为1,所以对于”aba”而言,它在PMT表中对应的值就是1。再比如,对于字符串”ababa”,它的前缀集合为{”a”, ”ab”, ”aba”, ”abab”},它的后缀集合为{”baba”, ”aba”, ”ba”, ”a”}, 两个集合的交集为{”a”, ”aba”},其中最长的元素为”aba”,长度为3。
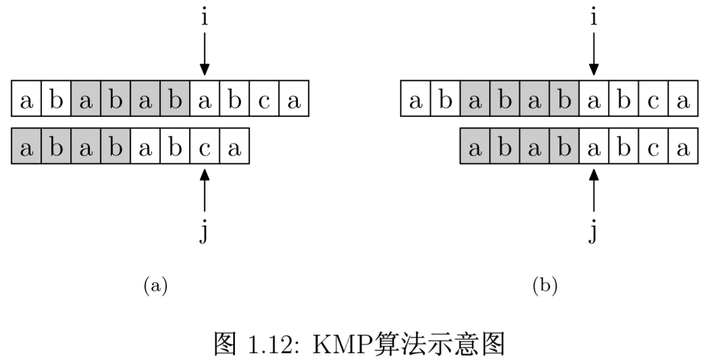
好了,解释清楚这个表是什么之后,我们再来看如何使用这个表来加速字符串的查找,以及这样用的道理是什么。如上图所示,要在主字符串"ababababca"中查找模式字符串"abababca"。如果在 j 处字符不匹配,那么由于前边所说的模式字符串 PMT 的性质,主字符串中 i 指针之前的 PMT[j −1] 位的字符串就一定与模式字符串的第 0 位至第 PMT[j−1] -1位是相同的。这是因为主字符串在 i 位失配,也就意味着主字符串从 i−j 到 i -1这一段是与模式字符串的 0 到 j -1这一段是完全相同的。而我们上面也解释了,模式字符串从 0 到 j−1 ,在这个例子中就是”ababab”,其前缀集合与后缀集合的交集的最长元素为”abab”, 长度为4。所以就可以断言,主字符串中i指针之前的 4 位一定与模式字符串的第0位至第 3位是相同的,即长度为 4 的后缀与前缀相同。这样一来,我们就可以将这些字符段的比较省略掉。具体的做法是,保持i指针不动,然后将j指针指向模式字符串的PMT[j −1]位即可。
简言之,以图中的例子来说,在 i 处失配,那么主字符串和模式字符串的前边6位就是相同的。又因为模式字符串的前6位,它的前4位前缀和后4位后缀是相同的,所以我们推知主字符串i之前的4位和模式字符串开头的4位是相同的。就是图中的灰色部分。那这部分就不用再比较了。
关于编程求PMT的逻辑思路,举一个例子如下:
对于字符串s=“aabaabaaa”,它的PMT如下表所示:
| 字符串 | a | a | b | a | a | b | a | a | a |
| 字符序号 | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
7 | 8 |
| pmt | 0 | 1 | 0 | 1 | 2 | 3 | 4 | 5 | 2 |
pmt[0] =0是默认值。
- 开始时令 j=0 i=1,由于s[j]=s[i],所以pmt[1] = j+1 = 1;接着同时移动j和i,于是j=1,i=2
- 对于j=1,i=2,s[j]!=s[i],于是j = pmt[j-1] = pmt[0] =0 , i不变; 同样比较s[j]和s[i],发现不相等,此时j已经为0了,无法继续=pmt[j-1],故pmt[i] =0(即pmt[2]=0),移动i,即i = i+1 = 3.
- 对于j =0 ,i = 3,s[j]=s[i] ,则pmt[i] = j+1 =1 (即pmt[3] =1)。接着同时移动j和i,于是j=1,i=4
- 对于j=1,i=4,s[j]=s[i] ,则pmt[i] = j+1 =2 (即pmt[4] =2)。接着同时移动j和i,于是j=2,i=5
- 对于j=2,i=5,s[j]=s[i] ,则pmt[i] = j+1 =3 (即pmt[5] =3)。接着同时移动j和i,于是j=3,i=6
- 对于j=3,i=6,s[j]=s[i] ,则pmt[i] = j+1 =4 (即pmt[6] =4)。接着同时移动j和i,于是j=4,i=7
- 对于j=4,i=7,s[j]=s[i] ,则pmt[i] = j+1 =5 (即pmt[7] =5)。接着同时移动j和i,于是j=5,i=8
- 对于j=5,i=8,s[j]!=s[i],则j = pmt[j-1] = pmt[4] = 2,i不变;同样比较s[j]和s[i],s[2] !=s [8] ;继续j=pmt[j-1]=pmt[1]=1,同样比较s[j]和s[i],s[1] = s[8] ,则pmt[i] = j+1 = 1+1 =2。
上面当s[j] != s[i] ,令j = pmt[j-1] 后再进行 s[j] 和s[i]的比较是因为s[j] != s[i] ,则计算第0位到第i位字符串的的前缀集合与后缀集合的交集中最长元素就不是第0位到第j位,我们之前已经存储过pmt[j-1],它表示的是第0位到第i-1位的字符串的前缀集合与后缀集合的交集中最长元素的长度(同样也是这个重复前缀的最后一个字符的下一位),那么我们令j=pmt[j-1],接着比较s[j]和s[i]就是比较这个重复前缀的最后一个字符的下一位与第i位是否相等,若相等,那么最长重复前缀和后缀的长度就在原有基础上加1,,若不等则继续同样的操作。
利用pmt数组进行子串与母串的匹配逻辑思路如下:
构建pmt数组后,当子串与母串进行匹配时,当子串的第m位与母串的第n位发生失配时,我们的下一次匹配只需要用子串的第pmt[m-1]位于母串的第n位进行匹配,这样迭代下去,直到出现子串的第0位于母串的第n位仍然失配的情况,这时候下一次比较就是用子串的第0位于母串的第n+1位进行匹配了,这样一直进行下去。
class Solution {
public:
int strStr(string haystack, string needle) {
int m = haystack.length(), n = needle.length();
if (!n) return 0;
vector<int> pmt = kmpProcess(needle);
for (int i = 0, j = 0; i < m;) {
if (haystack[i] == needle[j]) {
++i;
++j;
}
if (j == n) {
return i - j;
}
if ((i < m) && (haystack[i] != needle[j])) {
if (j) {
j = pmt[j - 1];
}
else {
++i;
}
}
}
return -1;
}
private:
vector<int> kmpProcess(string &needle) {
int n = needle.length();
vector<int> pmt(n, 0);//pmt[0]默认为0
int j = 0, i = 1;
while (i < n) {
if (needle[j] == needle[i]) {
pmt[i] = j + 1;
++j;
++i;
}
else {
if (j != 0) {
j = pmt[j - 1];
}
else {
pmt[i] = 0;
++i;
}
}
}
return pmt;
}
};