1、Shuffle原理和运行机制回顾
2、Shuffle性能调优
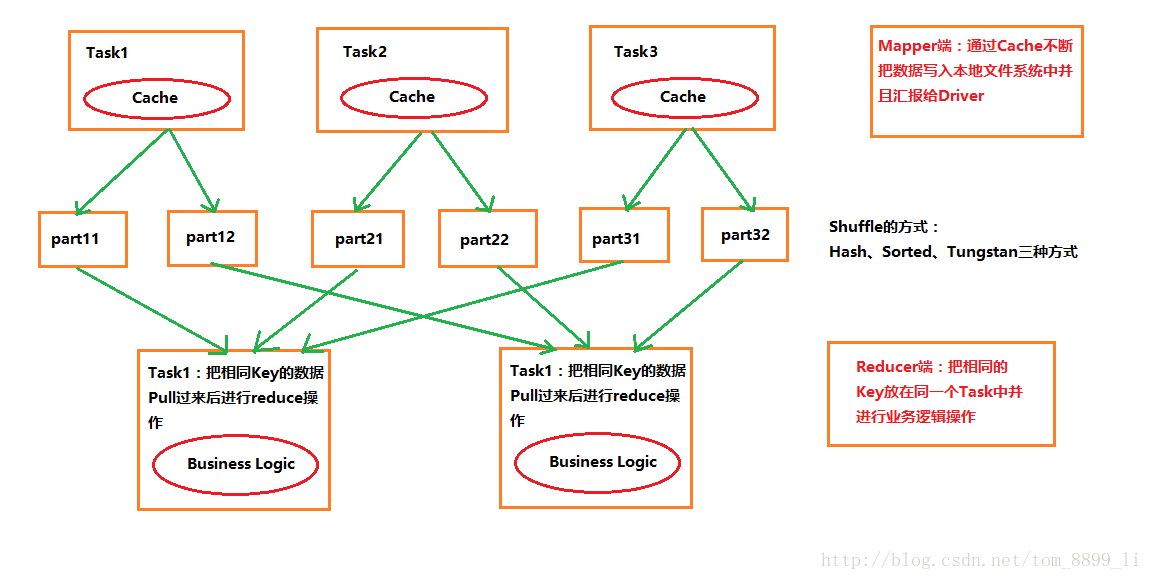
上面的流程中:
性能问题1:Mapper端的Cache:如果Cache设置的大小不恰当,可能产生大量磁盘的访问操作,因为要频繁地往本地磁盘写数据。
性能问题2:Reducer端的Business Logic运行的空间,如果说空间分配不够,业务逻辑运行的时候被迫把数据Spill到磁盘上面。一方面造成了业务逻辑处理的时候需要读写磁盘,另一方面也会造成不安全(数据读写故障)
看Log和Web UI上面的信息来判断是否需要调整上面的两个问题所涉及的参数。
针对问题1:Mapper端的性能调优参数是spark.shuffle.file.buffer,默认大小是32k,我们要根据数据量和并发量来适当调整该参数,尽量减少过于频繁的磁盘访问操作,开始是32k,后面可以调整成为64k,128k等等,需观察性能效果。
针对问题2:spark.shuffle.memoryFracton 默认大小是0.2,Reducer端的业务逻辑运行占用Executor内存大小的20%,一个额外的说明:很多公司的Executor中线程的并行度在5个左右,调整的时候可以从0.2调整为0.3,0.4等