目录
上篇文章讲到了《Spring之数据库编程》,感兴趣的读者可以查看。本篇文章将讲解企业应用中最为重要的数据库事务。
互联网系统时时面对着高并发,在互联网系统中同时跑着成百上千条线程都是十分常见的,尤其是当一些热门网站将刚上市的廉价商品放在线上销售时,狂热的用户几乎在同一时刻打开手机、电脑、平板电脑等设备进行疯狂抢购。这样就会出现多线程的访问网站,进而导致数据库在一个多事务访问的环境中,从而引发数据库丢失更新(Lost Update)和数据一致性的问题,同时也会给服务器带来很大压力,甚至发生数据库系统死锁和瘫痪进而导致系统宕机。为了解决这些问题,互联网开发者需要先了解数据库的一些特性,进而规避一些存在的问题,避免数据的不一致,提高系统性能。
在大部分情况下,我们会认为数据库事务要么同时成功,要么同时失败,但是也存在着不同的要求。比如银行的信用卡还款,有个跑批量的事务,而这个批量事务又包含了对各个信用卡的还款业务的处理,我们不能因为其中一张卡的事务失败了,而把其他卡的事务也回滚,这样就会导致因为一个客户的异常,造成多个客户还款失败,即正常还款的用户,也被认为是不正常还款的,这样会引发严重的金融信誉问题,Spring事务的传播行为带来了比较方便的解决方案。
1 Spring数据库事务管理器的设计
在Spring中数据库事务是通过PlatformTransactionManager进行管理的,上篇文章中讨论了JdbcTemplate的源码,并且知道单凭它自身是不能支持事务的,而能够支持事务的是org.springframework.transaction.support.TransactionTemplate模板,它是Spring所提供的事务管理器的模板,先来阅读一段重要的源码,如下所示:
public class TransactionTemplate
extends DefaultTransactionDefinition
implements TransactionOperations, InitializingBean
{
//do something...
@Nullable
private PlatformTransactionManager transactionManager;
//do something...
@Nullable
public <T> T execute(TransactionCallback<T> action)
throws TransactionException
{
Assert.state(this.transactionManager != null, "No PlatformTransactionManager set");
if ((this.transactionManager instanceof CallbackPreferringPlatformTransactionManager)) {
return (T)((CallbackPreferringPlatformTransactionManager)this.transactionManager).execute(this, action);
}
TransactionStatus status = this.transactionManager.getTransaction(this);
try
{
result = action.doInTransaction(status);
}
catch (RuntimeException|Error ex)
{
T result;
rollbackOnException(status, ex);
throw ex;
}
catch (Throwable ex)
{
rollbackOnException(status, ex);
throw new UndeclaredThrowableException(ex, "TransactionCallback threw undeclared checked exception");
}
T result;
this.transactionManager.commit(status);
return result;
}
//do something...
}- 事务的创建、提交和回滚是通过PlatformTransactionManager接口来完成的。
- 当事务产生异常时会回滚事务,在默认的实现中所有的异常都会回滚。我们可以通过配置去修改在某些异常发生时回滚或者不回滚事务。
- 当无异常时,会提交事务。
这样我们的关注点就转入了事务管理器的实现上。在Spring中,有多种事务管理器,他们的设计如下图所示:
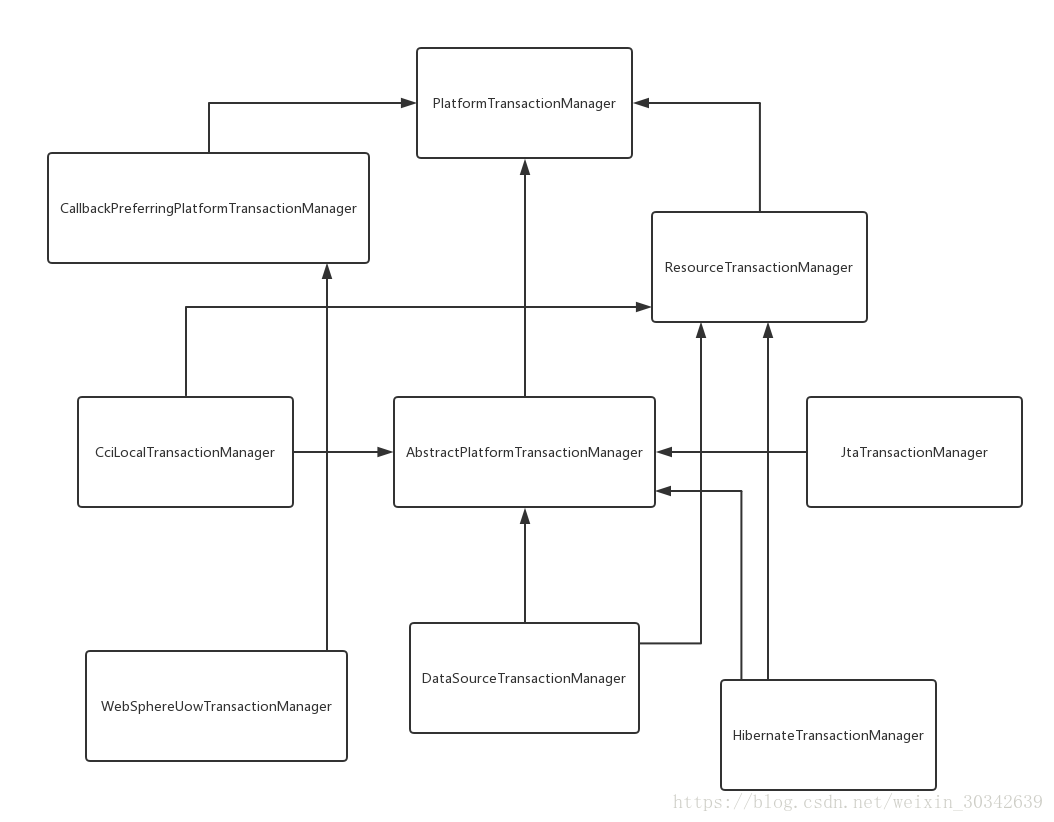
从图中可以看到多个数据库事务管理器,并且支持JTA事务,常用的是DataSourceTransactionManager,它继承抽象事务管理器AbstractPlatformTransactionManager,而AbstractPlatformTransactionManager又实现了PlatformTransactionManager。这样Spring就可以如同源码中看到的那样使用PlatformTransactionManager接口的方法,创建、提交或者回滚事务了。
PlatformTransactionManager接口的源码很简单,代码如下:
public abstract interface PlatformTransactionManager
{
public abstract TransactionStatus getTransaction(@Nullable TransactionDefinition paramTransactionDefinition)
throws TransactionException;
public abstract void commit(TransactionStatus paramTransactionStatus)
throws TransactionException;
public abstract void rollback(TransactionStatus paramTransactionStatus)
throws TransactionException;
}这样我们就掌握了其基本的用法。
1.1 配置事务管理器
一般而言我们在使用时,会加入XML的事务命名空间。下面配置一个事务管理器,代码如下:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:tx="http://www.springframework.org/schema/tx"
xmlns:aop="http://www.springframework.org/schema/aop"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-4.0.xsd http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx-4.0.xsd http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop-4.0.xsd">
<bean id="dataSource"
class="org.springframework.jdbc.datasource.SimpleDriverDataSource">
<property name="driverClass" value="com.mysql.cj.jdbc.Driver" />
<property name="url"
value="jdbc:mysql://localhost:3306/ssm?serverTimezone=UTC&useSSL=false" />
<property name="username" value="root" />
<property name="password" value="root" />
</bean>
<bean id="jdbcTemplate"
class="org.springframework.jdbc.core.JdbcTemplate">
<property name="dataSource" ref="dataSource" />
</bean>
<!-- 配置数据源事务管理器 -->
<bean id="transactionManager"
class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource" />
</bean>
</beans>这里先引入了XML的命名空间,然后定义了数据库连接池,于是使用了DataSourceTransactionManager来定义数据库事务管理器,并且注入了数据库连接池。这样Spring就知道你已经将数据库事务委托给事务管理器transactionManager管理了。在上篇文章JdbcTemplate源码分析时曾经说过,数据库资源的产生和释放如果没有委托给数据库管理器,那么就由JdbcTemplate管理,但是此时已经委托给了事务管理器,所以JdbcTemplate的数据库资源和事务已经由事务管理器处理了。
在Spring中可以使用声明式事务或者编程式事务,如今编程式事务几乎不用了,因为它会产生冗余,代码可读性较差,所以这里只简单交代其用法,而主要阐述的是声明式事务。声明式事务又可以分为XML配置和注解事务,但XML方式也已经不常用了,所以这里只简单交代它的用法,目前主流方式是注解@Transactional,因此本篇的内容主要就讲解它了。
1.2 用Java配置方式实现Spring数据库事务
用Java配置的方式来实现Spring数据库事务,需要在配置类中实现接口TransactionManagementConfigurer的annotationDrivenTransactionManager方法。Spring会把annotationDrivenTransactionManager方法返回的事务管理器作为程序中的事务管理器,比如下面的例子,就是使用Java配置方式实现Spring的数据库事务配置,代码如下:
@Configuration
@ComponentScan("com.hys.spring.example8.*")
//使用事务驱动管理器
@EnableTransactionManagement
public class JavaConfig implements TransactionManagementConfigurer {
/**
* 数据源
*/
private DataSource dataSource = null;
/**
*
* <p>Title: initDataSource </p>
* <p>Description: 配置数据源 </p>
* @return 数据源
* @author houyishuang
* @date 2018年9月5日
*/
@Bean(name = "dataSource")
public DataSource initDataSource() {
if (dataSource != null) {
return dataSource;
}
Properties props = new Properties();
props.setProperty("driverClassName", "com.mysql.jdbc.Driver");
props.setProperty("url", "jdbc:mysql://localhost:3306/ssm");
props.setProperty("username", "root");
props.setProperty("password", "root");
props.setProperty("maxActive", "200");
props.setProperty("maxIdle", "20");
props.setProperty("maxWait", "30000");
try {
dataSource = BasicDataSourceFactory.createDataSource(props);
} catch (Exception e) {
e.printStackTrace();
}
return dataSource;
}
/**
*
* <p>Title: initJdbcTemplate </p>
* <p>Description: 配置JdbcTemplate </p>
* @return JdbcTemplate
* @author houyishuang
* @date 2018年9月5日
*/
@Bean(name = "jdbcTemplate")
public JdbcTemplate initJdbcTemplate() {
JdbcTemplate jdbcTemplate = new JdbcTemplate();
jdbcTemplate.setDataSource(initDataSource());
return jdbcTemplate;
}
/**
*
* <p>Title: annotationDrivenTransactionManager</p>
* <p>Description: 实现接口方法,使得返回数据库事务管理器</p>
* @return
* @see org.springframework.transaction.annotation.TransactionManagementConfigurer#annotationDrivenTransactionManager()
* @author houyishuang
* @date 2018年9月5日
*/
@Override
@Bean(name = "transactionManager")
public PlatformTransactionManager annotationDrivenTransactionManager() {
DataSourceTransactionManager transactionManager = new DataSourceTransactionManager();
//设置事务管理器管理的数据源
transactionManager.setDataSource(initDataSource());
return transactionManager;
}
}
第三个方法实现了TransactionManagementConfigurer接口所定义的方法annotationDrivenTransactionManager,并且我们使用DataSourceTransactionManager来定义数据库事务管理器的实例,然后把数据源设置给它。注意,使用注解@EnableTransactionManagement后,在Spring上下文中使用事务注解@Transactional,Spring就会知道使用这个数据库事务管理器管理事务了。
2 编程式事务
编程式事务以代码的方式管理事务,换句话说,事务将由开发者通过自己的代码来实现,这里需要使用一个事务定义类接口——TransactionDefinition,暂时不进行深入的介绍,我们只要使用默认的实现类——DefaultTransactionDefinition就可以了。关于它的详细介绍在后面章节详谈,这里使用上述XML的配置,在创建Spring IoC容器的基础上,先给出其编程式事务的代码,如下:
ApplicationContext ctx = new ClassPathXmlApplicationContext("com/hys/spring/example8/config/spring-cfg.xml");
JdbcTemplate jdbcTemplate = ctx.getBean(JdbcTemplate.class);
//事务定义类
TransactionDefinition def = new DefaultTransactionDefinition();
PlatformTransactionManager transactionManager = ctx.getBean(PlatformTransactionManager.class);
TransactionStatus status = transactionManager.getTransaction(def);
try {
jdbcTemplate.update("insert into t_role(role,note) values('role_name_transactionManager','note_transactionManager')");
//提交事务
transactionManager.commit(status);
} catch (Exception e) {
//回滚事务
transactionManager.rollback(status);
}从代码中可以看到所有的事务都是由开发者自己进行控制的,由于事务已交由事务管理器管理,所以JdbcTemplate本身的数据库资源已经由事务管理器管理,因此当它执行完insert语句时不会自动提交事务,这个时候需要使用事务管理器的commit方法,回滚事务需要使用rollback方法。
当然这是最简单的使用方式,因为这个方式已经不是主流方式,甚至几乎是不被推荐使用的方式,之所以介绍是因为它的代码流程更为清晰,有助于未来对声明式事务的理解。
3 声明式事务
声明式事务是一种约定型的事务,在大部分情况下,当使用数据库事务时,大部分的场景是在代码中发生了异常时,需要回滚事务,而不发生异常时则提交事务,从而保证数据库数据的一致性。从这点出发,Spring给了一个约定(AOP开发也给了我们一个约定),如果使用的是声明式事务,那么当你的业务方法不发生异常(或者发生异常,但该异常也被配置信息允许提交事务)时,Spring就会让事务管理器提交事务,而发生异常(并且该异常不被你的配置信息所允许提交事务)时,则让事务管理器回滚事务。
首先声明式事务允许自定义事务接口——TransactionDefinition,它可以由XML或者注解@Transactional进行配置,到了这里我们先谈谈@Transactional的配置项。
3.1 @Transactional的配置项
如果你认为@Transactional的配置项很复杂,那么就大错特错了,这里探索一下它的源码,如下所示:
package org.springframework.transaction.annotation;
import java.lang.annotation.Annotation;
import java.lang.annotation.Documented;
import java.lang.annotation.Inherited;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
import org.springframework.core.annotation.AliasFor;
@Target({java.lang.annotation.ElementType.METHOD, java.lang.annotation.ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Inherited
@Documented
public @interface Transactional
{
@AliasFor("transactionManager")
String value() default "";
@AliasFor("value")
String transactionManager() default "";
Propagation propagation() default Propagation.REQUIRED;
Isolation isolation() default Isolation.DEFAULT;
int timeout() default -1;
boolean readOnly() default false;
Class<? extends Throwable>[] rollbackFor() default {};
String[] rollbackForClassName() default {};
Class<? extends Throwable>[] noRollbackFor() default {};
String[] noRollbackForClassName() default {};
}
显然@Transactional可配置的内容不算太多,不过由于它的重要性,这里给出它的配置项的含义,如下表所示:
| 配置项 | 含义 | 备注 |
|---|---|---|
| value | 定义事务管理器 | 它是Spring IoC容器里的一个Bean id,这个Bean需要实现接口PlatformTransactionManager |
| transactionManager | 同上 | 同上 |
| isolation | 隔离级别 | 这是一个数据库在多个事务同时存在时的概念,默认值取数据库默认隔离级别 |
| propagation | 传播行为 | 传播行为是方法之间调用的问题,默认值为Propagation.REQUIRED |
| timeout | 超时时间 | 单位为秒,当超时时,会引发异常,默认会导致事务回滚 |
| readOnly | 是否开启只读事务 | 默认值为false |
| rollbackFor | 回滚事务的异常类定义 | 也就是只有当方法产生所定义异常时,才回滚事务,否则就提交事务 |
| rollbackForClassName | 回滚事务的异常类名定义 | 同rollbackFor,只是使用类名称定义 |
| noRollbackFor | 当产生哪些异常不回滚事务 | 当产生所定义异常时,Spring将继续提交事务 |
| noRollbackForClassName | 同noRollbackFor | 同noRollbackFor,只是使用类的名称定义 |
value、transactionManager、timeout、readOnly、rollbackFor、rollbackForClassName、noRollbackFor和noRollbackForClassName都是十分容易理解的,isolation和propagation则不那么容易理解了,然而这两个配置项的内容确是为最为重要的内容。这些属性将会被Spring放到事务定义类TransactionDefinition中,事务声明器的配置内容也是以这些为主了。
注意,使用声明式事务需要配置注解驱动,只需要在上述XML配置中加入如下配置就可以使用@Transactional配置事务了:
<tx:annotation-driven
transaction-manager="transactionManager" />3.2 使用XML进行配置事务管理器
使用XML配置事务管理器的方法很多,但是也不常用,更多时我们会采用注解式的事务。为此这里只介绍一种通用的XML声明式事务配置,不过它却在一定流程上揭露了事务管理器的内部实现。它需要一个事物拦截器——TransactionInterceptor,可以把拦截器想象成AOP编程。让我们首先配置它,代码如下:
<bean id="transactionInterceptor"
class="org.springframework.transaction.interceptor.TransactionInterceptor">
<property name="transactionManager" ref="transactionManager"></property>
<!-- 配置事务属性 -->
<property name="transactionAttributes">
<props>
<!-- key代表的是业务方法的正则式匹配,而其内容可以配置各类事务定义参数 -->
<prop key="insert*">
PROPAGATION_REQUIRED,ISOLATION_READ_UNCOMMITTED
</prop>
<prop key="save*">
PROPAGATION_REQUIRED,ISOLATION_READ_UNCOMMITTED
</prop>
<prop key="add*">
PROPAGATION_REQUIRED,ISOLATION_READ_UNCOMMITTED
</prop>
<prop key="select*">
PROPAGATION_REQUIRED,readOnly
</prop>
<prop key="get*">
PROPAGATION_REQUIRED,readOnly
</prop>
<prop key="find*">
PROPAGATION_REQUIRED,readOnly
</prop>
<prop key="del*">
PROPAGATION_REQUIRED,ISOLATION_READ_UNCOMMITTED
</prop>
<prop key="remove*">
PROPAGATION_REQUIRED,ISOLATION_READ_UNCOMMITTED
</prop>
<prop key="update*">
PROPAGATION_REQUIRED,ISOLATION_READ_UNCOMMITTED
</prop>
</props>
</property>
</bean>配置transactionAttributes的内容是需要关注的重点,Spring IoC启动时会解析这些内容,放到事务定义类TransactionDefinition中,再运行时会根据正则式的匹配度决定方法采取哪种策略。显然这使用了拦截器和Spring AOP的编程技术,这也揭示了声明式事务的底层原理——Spring AOP技术。
上述代码只展示了Spring方法采取的事务策略,并没有告知Spring拦截哪些类,因此我们还需要告诉Spring哪些类要使用事务拦截器进行拦截,为此我们再配置一个类BeanNameAutoProxyCreator,代码如下:
<bean
class="org.springframework.aop.framework.autoproxy.BeanNameAutoProxyCreator">
<property name="beanNames">
<list>
<value>*ServiceImpl</value>
</list>
</property>
<property name="interceptorNames">
<list>
<value>transactionInterceptor</value>
</list>
</property>
</bean>BeanName属性告诉Spring如何拦截类。由于声明为*ServiceImpl,所有关于Service的实现类都会被其拦截,然后interceptorNames则是定义事务拦截器,这样对应的类和方法就会被事务管理器所拦截了。
3.3 事务定义器
从注解@Transactional或者XML中我们看到了事务定义器的身影,因此我们有必要讨论一下事务定义器TransactionDefinition的内容,源码如下:
package org.springframework.transaction;
import org.springframework.lang.Nullable;
public abstract interface TransactionDefinition
{
public static final int PROPAGATION_REQUIRED = 0;
public static final int PROPAGATION_SUPPORTS = 1;
public static final int PROPAGATION_MANDATORY = 2;
public static final int PROPAGATION_REQUIRES_NEW = 3;
public static final int PROPAGATION_NOT_SUPPORTED = 4;
public static final int PROPAGATION_NEVER = 5;
public static final int PROPAGATION_NESTED = 6;
public static final int ISOLATION_DEFAULT = -1;
public static final int ISOLATION_READ_UNCOMMITTED = 1;
public static final int ISOLATION_READ_COMMITTED = 2;
public static final int ISOLATION_REPEATABLE_READ = 4;
public static final int ISOLATION_SERIALIZABLE = 8;
public static final int TIMEOUT_DEFAULT = -1;
public abstract int getPropagationBehavior();
public abstract int getIsolationLevel();
public abstract int getTimeout();
public abstract boolean isReadOnly();
@Nullable
public abstract String getName();
}
以上就是关于事务定义器的内容,除了异常的定义,其他关于事务的定义都可以在这里完成,而对于事务的回滚内容,它会以RollbackRuleAttribute和NoRollbackRuleAttribute两个类进行保存,这样在事务拦截器中就可以根据我们所配置的内容来处理事务方面的内容了。
3.4 声明式事务的约定流程
这里的约定十分重要,我们首先要理解@Transactional注解或者XML配置。@Transactional注解可以使用在方法或者类上面,在Spring IoC容器初始化时,Spring会读入这个注解或者XML配置的事务信息,并且保存到一个事务定义类里面(TransactionDefinition接口的子类),以备将来使用。当运行时会让Spring拦截注解标注的某一个方法或者类的所有方法。谈到了拦截,可能会想到AOP,Spring也是如此。有了AOP的概念,那么它就会把你编写的代码织入到AOP的流程中,然后给出它的约定。
首先Spring通过事务管理器(PlatformTransactionManager的子类)创建事务,与此同时会把事务定义中的隔离级别、超时时间等属性根据配置内容往事务上设置。而根据传播行为配置采取一种特定的策略,这是Spring根据配置完成的内容,你只需要配置,无需编码。然后,启动开发者提供的业务代码,我们知道Spring会通过反射的方式调用开发者的业务代码,但是反射的结果可能是正常返回或者产生异常返回,那么它给的约定是只要发生异常,并且符合事务定义类回滚条件的,Spring就会将数据库事务回滚,否则将数据库事务提交,这也是Spring自己完成的。你会惊奇地发现,在整个开发过程中,只需要编写业务代码和对事务属性进行配置就可以了,并不需要使用代码干预,工作量比较少,代码逻辑也更为清晰,更有利于维护。声明式事务的流程如下图所示:
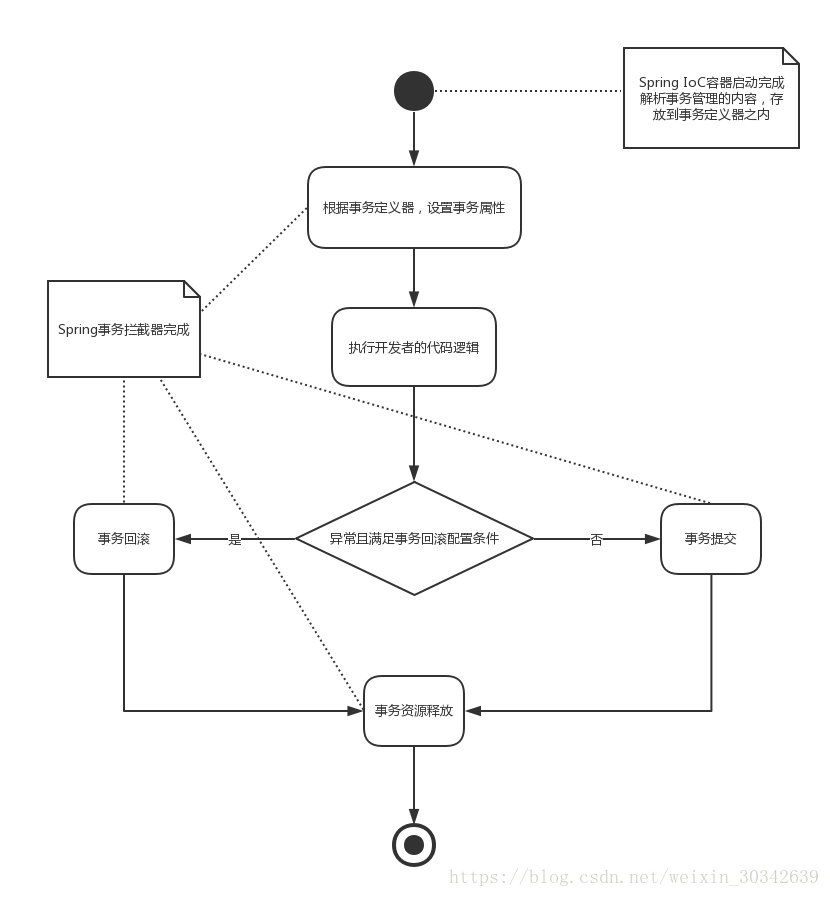
比如插入角色代码,代码如下:
@Autowired
private RoleDao roleDao = null;
@Transactional(propagation = Propagation.REQUIRED, isolation = Isolation.DEFAULT, timeout = 3)
public int insertRole(Role role) {
return roleDao.insert(role);
}这里没有数据库的资源打开和释放代码,也没看到数据库提交的代码,只看到了注解@Transactional。它配置了Propagation.REQUIRED的传播行为,这意味着当别的方法调用时,如果存在事务就沿用下来,如果不存在事务就开启新的事务,而隔离级别采用默认的隔离级别,并且设置超时时间为3秒。其他的开发人员只要知道当roleDao的insert方法抛出异常时,Spring就会回滚事务,如果成功,就提交事务。这样Spring就让开发人员主要的精力放在业务的开发上,而不是控制数据库的资源和事务上。但是我们必须清楚的是,这里的神奇原理是Spring AOP技术,而其底层的实现原理是动态代理。
下面需要讨论的是两个最难理解,也是最为重要的事务配置项,那就是隔离级别和传播行为。在此之前,我们要进一步深入讨论关于数据库的一些重要知识。
4 数据库的相关知识
为了更好地理解@Transactional的内容,本节先讨论一些数据库的特性。
4.1 数据库事务ACID特性
数据库事务正确执行的4个基础要素是原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持久性(Durability)。
- 原子性:整个事务中的所有操作,要么全部完成,要么全部不完成,不可能停滞在中间某个环节。事务在执行过程中发生错误,会被回滚到事务开始前的状态,就像这个事务从来没被执行过一样。
- 一致性:指一个事务可以改变封装状态(除非它是一个只读的)。事务必须始终保持系统处于一致的状态,不管在任何给定的时间并发事务有多少。
- 隔离性:它是指两个事务之间的隔离程度。
- 持久性:在事务完成以后,该事务对数据库所做的更改便持久保存在数据库之中,并不会被回滚。
这里的原子性、一致性和持久性都比较好理解,而隔离性就不一样了,它涉及了多个事务并发的状态。首先多个事务并发会产生数据库丢失更新的问题,其次隔离性又分为多个层级。
4.2 丢失更新
在互联网中存在着抢购、秒杀等高并发场景,使得数据库在一个多事务的场景中运行,多个事务的并发会产生一系列的问题,主要的问题之一就是丢失更新,一般而言存在两类丢失更新。
假设一个场景,一个账户存在互联网消费和刷卡消费两种形式,而一对夫妻共用这个账户。老公喜欢刷卡消费,老婆喜欢互联网消费,那么可能产生下表所示的场景:
| 时刻 | 事务一(老公) | 事务二(老婆) |
|---|---|---|
| T1 | 查询余额10000元 | — |
| T2 | — | 查询余额10000元 |
| T3 | — | 网购1000元 |
| T4 | 请客吃饭消费1000元 | — |
| T5 | 提交事务成功,余额9000元 | — |
| T6 | — | 不想买了,取消购买,回滚事务到T2时刻,余额10000元 |
整个过程中只有老公消费了1000元,而在最后的T6时刻,老婆回滚事务,却恢复了原来的初始值余额10000元,这显然不符合事实。这样的两个事务并发,一个回滚、一个提交成功导致不一致,我们称为第一类丢失更新。所幸的是大部分数据库(包括MySQL和Oracle)基本都已经消灭了这类丢失更新,所以这里就不对这类丢失更新展开讨论了。
第二类丢失更新则是我们真正需要关注的内容,还是以上面的例子来说明,如下表所示:
| 时刻 | 事务一(老公) | 事务二(老婆) |
|---|---|---|
| T1 | 查询余额10000元 | — |
| T2 | — | 查询余额10000元 |
| T3 | — | 网购1000元 |
| T4 | 请客吃饭消费1000元 | — |
| T5 | 提交事务成功,查询为10000元,消费1000元后,余额9000元 | — |
| T6 | — | 提交事务,根据之前余额10000元,扣减1000元后,余额为9000元 |
整个过程中存在两笔交易,一笔是老公的请客吃饭,一笔是老婆的网购,但是两者都提交了事务,由于在不同的事务中,无法探知其他事务的操作,导致两者提交后,余额都为9000元,而实际正确的应为8000元,这就是第二类丢失更新。为了克服事务之间协助的一致性,数据库标准规范中定义了事务之间的隔离级别,来在不同程度上减少出现丢失更新的可能性,这便是下节将要讨论的数据库隔离级别。
4.3 隔离级别
隔离级别可以在不同程度上减少丢失更新,那么对于隔离级别数据库标准是怎么定义的呢?按照SQL的标准规范(有些人认为这是Spring或者Java的规范,而事实是SQL的规范,Spring或者Java只是按照SQL的规范定义的而已),把隔离级别定义为4层,分别是:脏读(dirty read)、读/写提交(read commit)、可重复读(repeatable read)和序列化(Serializable)。
初看这4个隔离级别不是那么好理解,不过不要紧,下面将举例说明它们的区别。
脏读是最低的隔离级别,其含义是允许一个事务去读取另一个事务中未提交的数据。还是以丢失更新的夫妻消费为例进行说明,如下表所示:
| 时刻 | 事务一(老公) | 事务二(老婆) | 备注 |
|---|---|---|---|
| T1 | 查询余额10000元 | — | — |
| T2 | — | 查询余额10000元 | — |
| T3 | — | 网购1000元,余额9000元 | — |
| T4 | 请客吃饭1000元,余额8000元 | — | 读取到事务二,未提交余额为9000元,所以余额为8000元 |
| T5 | 提交事务 | — | 余额为8000元 |
| T6 | — | 回滚事务 | 由于第一类丢失更新数据库已经克服,所以余额为错误的8000元 |
由于在T3时刻老婆启动了消费,导致余额为9000元,老公在T4时刻消费,因为用了脏读,所以能够读取老婆消费的余额(注意,这个余额是事务二未提交的)为9000元,这样余额就为8000元了,于是T5时刻老公提交事务,余额变为了8000元,老婆在T6时刻回滚事务,由于数据库克服了第一类丢失更新,所以余额依旧为8000元,显然这是一个错误的余额,产生这个错误的根源来自于T4时刻,也就是事务一可以读取事务二未提交的事务,这样的场景被称为脏读。
为了克服脏读,SQL标注提出了第二个隔离级别——读/写提交。所谓读/写提交,就是说一个事物只能读取另一个事务已经提交的数据。依旧以丢失更新的夫妻消费为例,如下表所示:
| 时刻 | 事务一(老公) | 事务二(老婆) | 备注 |
|---|---|---|---|
| T1 | 查询余额10000元 | — | — |
| T2 | — | 查询余额10000元 | — |
| T3 | — | 网购1000元,余额9000元 | — |
| T4 | 请客吃饭1000元,余额9000元 | — | 由于事务二的余额未提交,采取读/写提交时不能读出,所以余额为9000元 |
| T5 | 提交事务 | — | 余额为9000元 |
| T6 | — | 回滚事务 | 由于第一类丢失更新数据库已经克服,所以余额依旧为正确的9000元 |
在T3时刻,由于事务采取读/写提交的隔离级别,所以老公无法读取老婆未提交的9000元余额,他只能读到余额为10000元,所以在消费后余额依旧为9000元。在T5时刻提交事务,而T6时刻老婆回滚事务,所以结果为正确的9000元,这样就消除了脏读带来的问题,但是也会引发其他的问题,如下表所示:
| 时刻 | 事务一(老公) | 事务二(老婆) | 备注 |
|---|---|---|---|
| T1 | 查询余额10000元 | — | — |
| T2 | — | 查询余额10000元 | — |
| T3 | — | 网购1000元,余额9000元 | — |
| T4 | 请客吃饭2000元,余额8000元 | — | 由于采取读/写提交,不能读取事务二中未提交的余额9000元 |
| T5 | — | 继续购物8000元,余额1000元 | 由于采取读/写提交,不能读取事务一中的未提交余额8000元 |
| T6 | — | 提交事务,余额为1000元 | 老婆提交事务,余额更新为1000元 |
| T7 | 提交事务发现余额为1000元,不足以买单 | — | 由于采取读/写提交,因此此时事务一可以知道余额不足 |
由于T7时刻事务一知道事务二提交的结果——余额为1000元,导致老公无钱买单的尴尬。对于老公而言,他并不知道老婆做了什么事情,但是账户余额却莫名其妙地从10000元变为了1000,对他来说账户余额是不能重复读取的,而是一个会变化的值,这样的场景我们称为不可重复读(unrepeatable read),这是读/写提交存在的问题。
为了克服不可重复读带来的错误,SQL标准又提出了一个可重复读的隔离级别来解决问题。注意,可重复读这个概念是针对数据库同一条记录而言的,换句话说,可重复读会使得同一条数据库记录的读/写按照一个序列化进行操作,不会产生交叉情况,这样就能保证同一条数据的一致性,进而保证上述场景的正确性。但是由于数据库并不是只能针对一条数据进行读/写操作,在很多场景,数据库需要同时对多条记录进行读/写,这个时候就会产生下面的情况,如下表所示:
| 时刻 | 事务一(老公) | 事务二(老婆) | 备注 |
|---|---|---|---|
| T1 | — | 查询消费记录为10条,准备打印 | 初始状态 |
| T2 | 启用消费1笔 | — | — |
| T3 | 提交事务 | — | — |
| T4 | — | 打印消费记录得到11条 | 老婆发现打印了11条消费记录,比查询的10条多了一条。她会认为这条是多余不存在的,这样的场景称为幻读 |
老婆在T1查询到10条记录,到T4打印记录时,并不知道老公在T2和T3时刻进行了消费,导致多一条(可重复读是针对同一条记录而言的,而这里不是同一条记录)消费记录的产生,她会质疑这条多出来的记录是不是幻读出来的,这样的场景我们称为幻读(phantom read)。
为了克服幻读,SQL标准又提出了序列化的隔离级别。它是一种让SQL按照顺序读/写的方式,能够消除数据库事务之间并发产生数据不一致的问题。关于各类的隔离级别和产生的现象如下表所示:
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 脏读 | √ | √ | √ |
| 读/写提交 | × | √ | √ |
| 可重复读 | × | × | √ |
| 序列化 | × | × | × |
这里需要着重讲解一下这三者的区别:
脏读:同时操作都没提交的读取。脏读又称无效数据读出。一个事务读取另外一个事务还没有提交的数据叫脏读。
不可重复读:指的是同时操作,事务一分别读取事务二操作时和提交后的数据,读取的记录内容不一致。不可重复读是指在同一个事务内,两个相同的查询返回了不同的结果。
幻读:和可重复读类似,但是事务二的数据操作仅仅是插入和删除,不是修改数据,读取的记录数量前后不一致。
至此关于数据库的知识就介绍完了,下面讨论如何选择的问题。
5 选择隔离级别和传播行为
选择隔离级别的出发点在于两点:性能和数据一致性,下面展开论述。
5.1 选择隔离级别
在互联网应用中,不但要考虑数据库数据的一致性,而且要考虑系统的性能。一般而言,从脏读到序列化,系统性能直线下降。因此设置高的级别,比如序列化,会严重压制并发,从而引发大量的线程挂起,直到获得锁才能进一步操作,而恢复时又需要大量的等待时间。因此在购物类的应用中,通过隔离级别控制数据一致性的方式被排除了,而对于脏读风险又过大。在大部分场景下,企业会选择读/写提交的方式设置事务。这样既有助于提高并发,又压制了脏读,但是对于数据一致性问题并没有解决,该问题可以使用悲观锁或乐观锁来解决,具体使用可以参考笔者的另一篇博客《乐观锁&悲观锁》。对于一般的应用都可以使用@Transactional方法进行配置,代码如下:
@Autowired
private RoleDao roleDao = null;
//设置方法为读/写提交的隔离级别
@Transactional(propagation = Propagation.REQUIRED, isolation = Isolation.READ_COMMITTED)
public int insertRole(Role role) {
return roleDao.insert(role);
}当然也会有例外,并不是说所有的业务都在高并发下完成,当业务并发量不是很大或者根本不需要考虑的情况下,使用序列化隔离级别用以保证数据的一致性,也是一个不错的选择。总之,隔离级别需要根据并发的大小和性能来做出决定,对于并发不大又要保证数据安全性的可以使用序列化的隔离级别,这样就能够保证数据库在多事务环境中的一致性,代码如下:
@Autowired
private RoleDao roleDao = null;
//设置方法为序列化提交的隔离级别
@Transactional(propagation = Propagation.REQUIRED, isolation = Isolation.SERIALIZABLE)
public int insertRole(Role role) {
return roleDao.insert(role);
}只是这样的代码会使得数据库的并发能力低下,在抢购商品的场景下出现卡顿的情况,所以在高并发的场景下这段代码并不适用。
在实际工作中,注解@Transactional隔离级别的默认值为Isolation.DEFAULT,其含义是默认的,随数据库默认值的变化而变化。因为对于不同的数据库而言,隔离级别的支持是不一样的。比如MySQL可以支持4种隔离级别,而默认的是可重复读的隔离级别。而Oracle只能支持读/写提交和序列化两种隔离级别,默认为读/写提交,这些是在工作中需要注意的问题。
5.2 传播行为
传播行为是指方法之间的调用事务策略的问题。在大部分的情况下,我们都希望事务能够同时成功或者同时失败。但是也会有例外,假设现在需要实现信用卡的还款功能,有一个总的调用代码逻辑——RepaymentBatchService的batch方法,那么它要实现的是记录还款成功的总卡数和对应完成的信息,而每一张卡的还款则是通过RepaymentService的repay方法完成的。
首先来分析业务。如果只有一条事务,那么当调用RepaymentService的repay方法对某一张信用卡进行还款时,不幸的事情发生了,它发生了异常。如果将这条事务回滚,就会造成所有的数据操作都会被回滚,那些已经正常还款的用户也会还款失败,这将是一个糟糕的结果。当batch方法调用repay方法时,它为repay方法创建一条新的事务。当这个方法产生异常时,只会回滚它自身的事务,而不会影响主事务和其他事务,这样就能避免上面遇到的问题了,如下图所示:

上图展示了当我们希望通过batch方法去调度repay方法时能产生一条新事务,去处理一个信用卡还款。如果这张卡还款异常,那么只会回滚这条新事务,而不是回滚主事务。类似这样的一个方法调用另外一个方法时,可以对事务的特性进行传播配置,我们称为传播行为。
在Spring中传播行为的类型,是通过一个枚举类型来定义的,这个枚举类是org.springframework.transaction.annotation.Propagation,它定义了如下表所列举的7种传播行为:
| 传播行为 | 含义 | 备注 |
|---|---|---|
| REQUIRED | 当方法调用时,如果不存在当前事务,那么就创建事务;如果之前的方法已经存在事务了,那么就沿用之前的事务 | 这是Spring默认的传播行为 |
| SUPPORTS | 当方法调用时,如果不存在当前事务,那么不启用事务;如果存在当前事务,那么就沿用当前事务 | — |
| MANDATORY | 方法必须在事务内运行 | 如果不存在当前事务,那么就抛出异常 |
| REQUIRES_NEW | 无论是否存在当前事务,方法都会在新的事务中运行 | 也就是事务管理器会打开新的事务运行该方法 |
| NOT_SUPPORTED | 不支持事务,如果不存在当前事务也不会创建事务;如果存在当前事务,则挂起它,直至该方法结束后才恢复当前事务 | 适用于那些不需要事务的SQL |
| NEVER | 不支持事务,只有在没有事务的环境中才能运行它 | 如果方法存在当前事务,则抛出异常 |
| NESTED | 嵌套事务,也就是调用方法如果抛出异常只回滚自己内部执行的SQL,而不回滚主方法的SQL | 它的实现存在两种情况,如果当前数据库支持保存点(savepoint),那么它就会在当前事务上使用保存点技术;如果发生异常则将方法内执行的SQL回滚到保存点上,而不是全部回滚,否则就等同于REQUIRES_NEW创建新的事务运行方法代码 |
在上表的7种传播行为中,最常用的是REQUIRED,也是默认的传播行为。它比较简单,即当前如果不存在事务,就启用事务;如果存在,就沿用下来,所以并不需要深入研究。对于那些不支持事务的方法我们使用得不多,一般而言,企业比较关注的是REQUIRES_NEW和NESTED。
参考资料:[1]杨开振 周吉文 梁华辉 谭茂华.Java EE 互联网轻量级框架整合开发:SSM框架(Spring MVC+Spring+MyBatis)和Redis实现.北京:电子工业出版社,2017.7