1.Map/Reduce是什么
大数据并行编程框架,由两个基本的步骤Map(映射)和Reduce(化简)组成,它隐藏了分布式计算中并行化、容错、数据分布、负载均衡等内部细节,实际的使用中普通编程人员/应用人员只需关系map/reduce两个过程的实现
2.Map/Reduce的框架原理
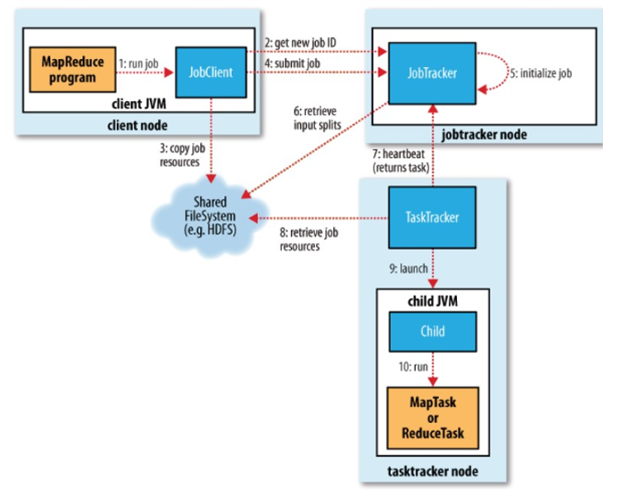
整个Map/Reduce框架包括3部分:JobClient、JobTracker、TaskTracker三部分组成,同时出入数据和输出数据是存储在HDFS中的。
TaskTracker:负责具体的map、Reduce任务的执行,并与JobTracker通信汇报自己的工作进展。
三、hadoop中Map/Reduce的任务的执行过程:
hdfs-->block--> map-->memory-->shuffle-->disk-->combine-->merge-->输出文件-->reduce-->hdfs
hadoop中一个Map/Reduce任务拆解为两个过程:Map过程和Reduce过程,两个过程可能在不同的计算节点上完成,以下是一个经典的Map/Reduce过程图:
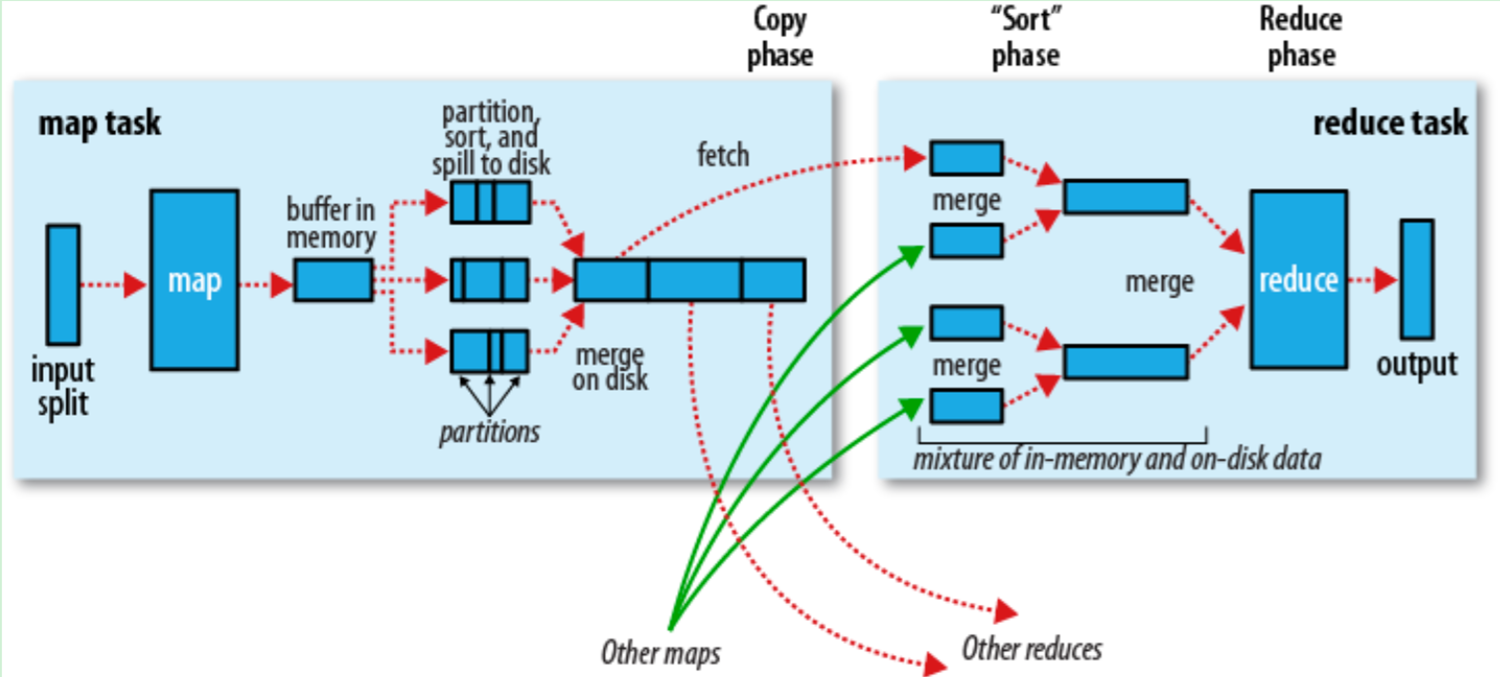
3.1 map
我们从图的左边开始看,input split为从HDFS中读取过来的数据,由于HDFS中文件是按照block来组织的,在这里读取的时候,也是按照block读取进来开始计算的,一般来说,数据是边读取边计算的一个流式的过程。一个maptask会读取多个块的数据,数据读进来之后数据通过map映射,会转换会一些基本<key,value>的形式,这个时候并不是直接把map后的数据发送给reduce端,因为第一直接map后的数据是无序的、第二直送发送会占用大量的网络IO资源。因此在中间会经过一个shuffle的过程。
shuffle,其实就是将数据打乱再整理的一个过程,这样出来的数据就是干净有序的了。shuffle过程包括partition、sort、spill三个过程。
partition:分区,分区数量就是 reduce 任务数量,即上图中 partitions ,默认情况下,只有一个分区,即只有一个 reduce 任务。线程根据处理数据需要的 reducetask总数量 把数据划分成相应的partition。具体划分:partition计算key的hash值,将hash对reducetask的数量求模 来确定要发送的reducetask的ID (实际上,由于key值得非均衡分布 这种算法可能会导致发送给某台reducetask的数据过多 而另外的reducetask收到的数据过程,hadoop允许我们自己实现partition接口来实现数据的均衡)。
sort: 每个 partition 中,后台进程按键进行内排序.
partition和sort都是在内存上操作
spill: 分区和排序后就生成溢出文件并保存到磁盘上,生成规则如下
每个 map 都有一个环形的内存缓冲区用于存储任务的输出,即上图中的 buffer in memory 。缓冲区默认大小为 100MB,可以通过改变 io.sort.mb 属性来调整。一旦缓冲内容达到阈值(io.sort.spill.percent,默认为 80%),一个后台线程就开始把内容溢出到(spill)磁盘。上图中,buffer in memory 后边的三个箭头分别对应三个溢出文件,每个文件上又有分区。在溢出写磁盘的过程中,map 输出继续写到缓冲区,但如果在此期间缓冲区被填满了,map 会被阻塞直到写磁盘过程完成。
溢出写磁盘时的位置:mapred.local.dir 属性指定的作业特定子目录中的目录中。
combine:在磁盘上分别对这三个溢出文件中具有相同key的key-value对,将其组合到一起并合并为1个key-value.(在单个溢出文件中和并),运行 combiner 使得每个 map 的输出结果更紧凑,可以减少写到磁盘的数据和传递给 reducer 的数据,因此减少的是在网络中传输的数据量。
注: combiner 这个过程不是都可以存在,在某些时候错误的使用 combiner 有可能会影响最后 reducer 的结果。
merge: 将这三个文件合并成一个已分区且已排序的输出文件(和并3个溢出文件并根据key-value对的key排序,不进行combine操作)。属性 io.sort.factor 控制一次最多能合并多少流,默认为10;
map 的输出是可以进行压缩后再写磁盘的,可以节约磁盘空间以及加快磁盘写的速度。mapred.compress.map.output 设置为 true ,就可以开启压缩功能。使用的压缩库由 mapred.map.output.compression.codec 指定。
最后,要知道的是,map 的最后输出经常写到 map 任务的本地磁盘,但是,reduce 的输出并不是这样的。
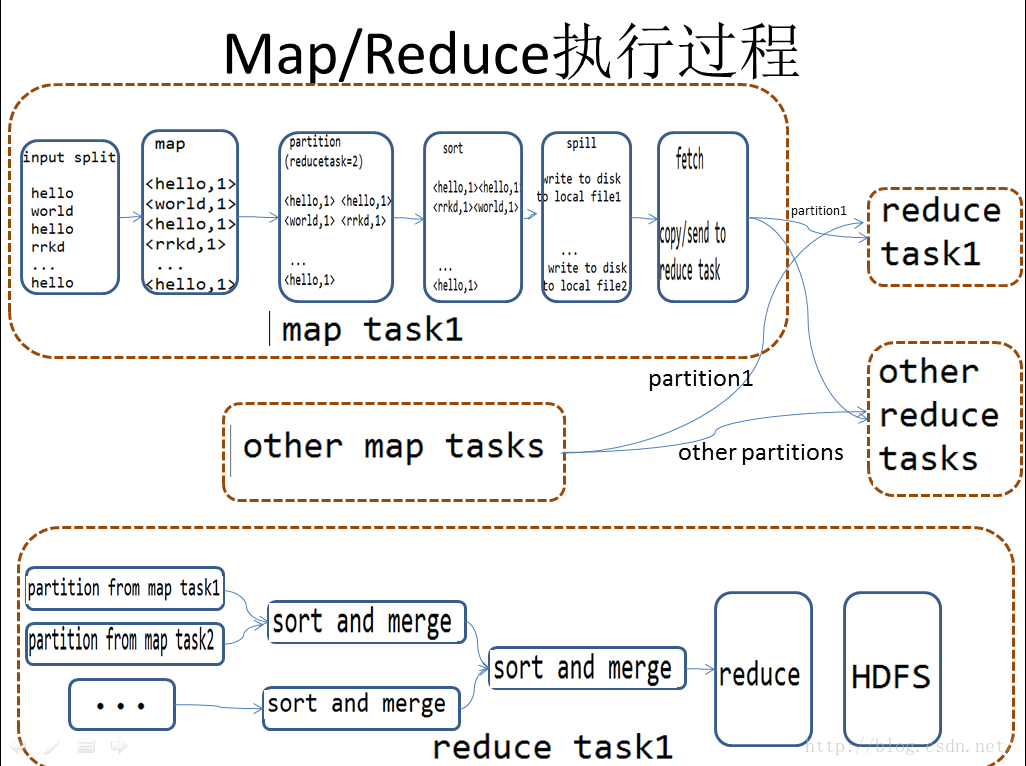
1.根据reducetask1分析reduce :
从map输出的所有文件中分别同时拉取都在partition1中的数据--->sort and merge(两两maptask输出文件合并,并根据Key将key-value对排序)---->.......---->直到剩下一个集合且所有Key-value对都排好序时,进行reduce操作(combine操作) --->将化简后的结果存入hdfs