原因:为了方便自己查书,不想每一次都打开百度去找自己学校图书馆的网址,然后再查,所以就打算用php中的curl的方法来做一个这样的功能。
当时的思路:先找到学校图书馆查询页面的网址 http://121.33.188.47:22995/opac_two/search2/search.jsp。。这个是我们学校的,然后用fiddler抓取要post的数据,取得返回值之后用处理数组,再放进表格。。不过测试之后,发现post的地址不是上面那个,而是这个 http://121.33.188.47:22995/opac_two/search2/searchout.jsp 。。
先上张图。。。
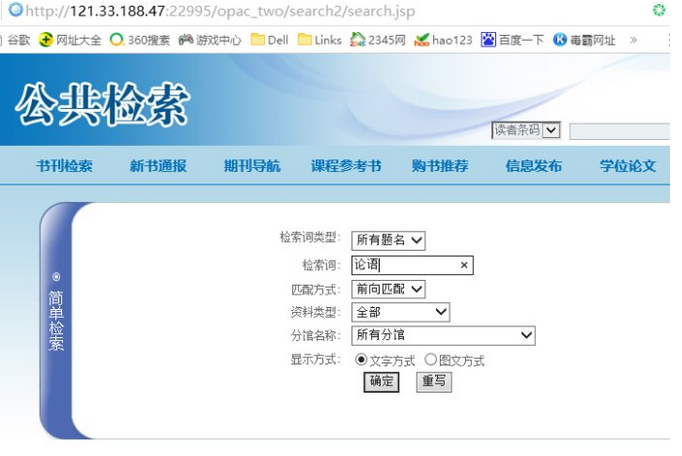
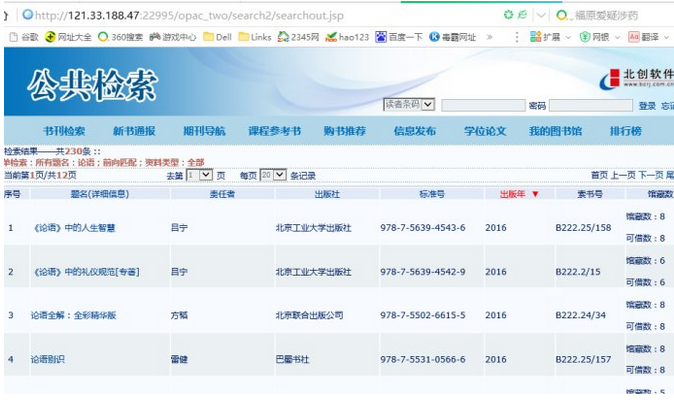
分析完之后就开始用fiddler抓数据了。。。

图中的那一串东西就是我们要抓的数据。。。
search_no_type=Y&snumber_type=Y&suchen_type=1&suchen_word=%C2%DB%D3%EF&suchen_match=qx&recordtype=all&library_id=all&show_type=wenzi&B1=%C8%B7%B6%A8
在查看过源代码之后发现,suchen_word这个就是检索词,而后面那一堆东西就是中文字符经过了url编码的。。
所以代码就这样。。
$ch1 = curl_init();
$url = "http://121.33.188.47:22995/opac_two/search2/searchout.jsp";
$data1="search_no_type=Y&snumber_type=Y&suchen_type=1&suchen_word=%C2%DB%D3%EF&suchen_match=qx&recordtype=all&library_id=all&show_type=wenzi&B1=%C8%B7%B6%A8";
curl_setopt($ch1, CURLOPT_URL,$url);
curl_setopt($ch1, CURLOPT_POST, 1);
curl_setopt($ch1, CURLOPT_POSTFIELDS, $data1);
curl_setopt($ch1, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch1, CURLOPT_HEADER, 0);
curl_setopt($ch1, CURLOPT_USERAGENT, 'Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9.1.5) Gecko/20091102 Firefox/3.5.5');
$result=curl_exec($ch1);
curl_close($ch1);
prin_r($result);然后返回了这样。。。
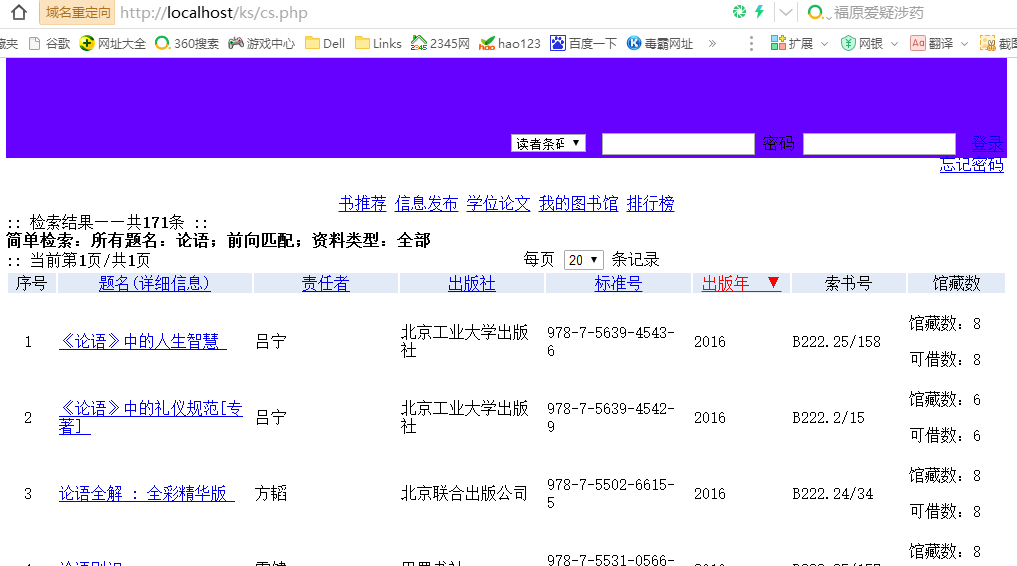
额。。这页面。。实在有点丑。。不过已经得到了想要的数据了。。接下来就是用正则匹配想要的信息了。。
$res=mb_convert_encoding($result, "utf-8", "gb2312"); //转换编码
$str1 = preg_replace("/]*>/","", $res);
$str2 = preg_replace("/<\/a>/","", $str1); //过滤掉网页中的a标签并取得里面的值
$pattern='#<td.+?>(.+?)</td>#'; //匹配表格里的内容
preg_match_all($pattern, $str2, $n);
foreach ($n as $k => $v) { //遍历数组
$cs=array_slice($v, 11); //将数组的前11个元素去除
}然后结果是这样。。

得到想要的数据之后,就用bootstrap写了个表格,将数组循环出来。并做了个前端的页面。最后的效果是这样的。。。
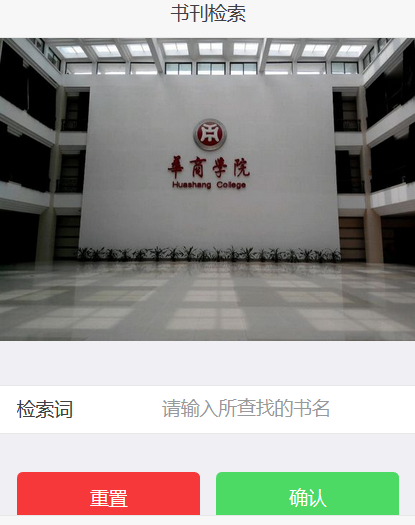

由于用了bootstrap的响应式表格,屏幕宽度小于756px的会出现水平滚动条
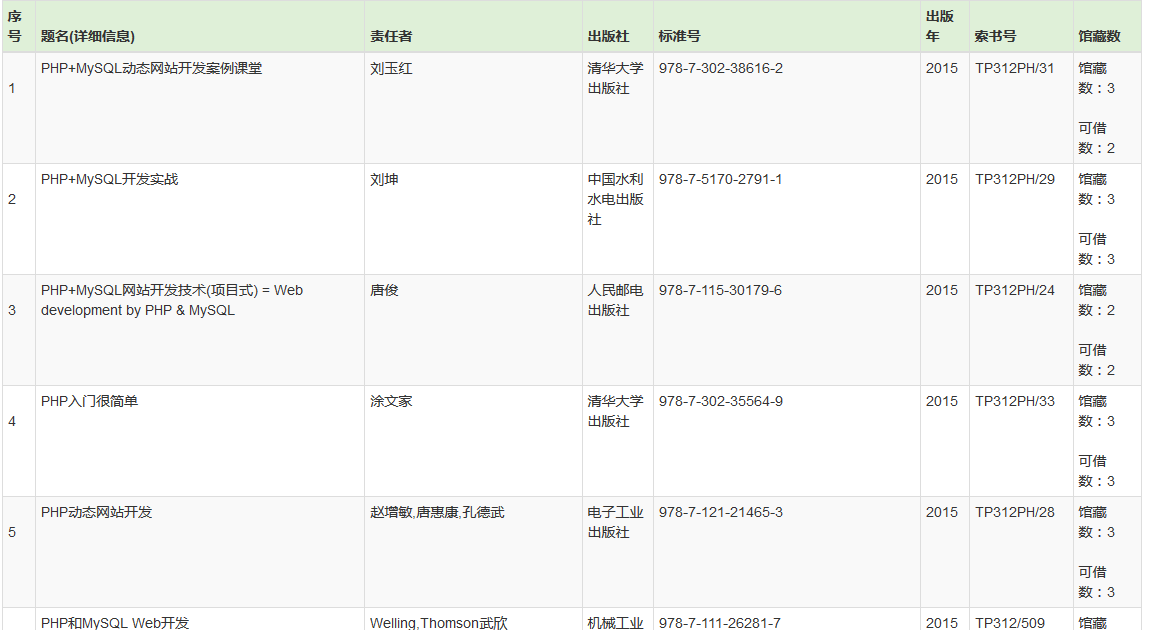
这个是PC端上看到的效果。。
这是查询结果的源代码
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8" />
<title>查询结果</title>
<meta name="viewport" content="width=device-width,initial-scale=1.0,user-scalable=no">
<link rel="stylesheet" href="css/bootstrap.min.css" />
<script type="text/javascript" src="js/jquery.min.js" ></script>
<script type="text/javascript" src="js/bootstrap.min.js" ></script>
</head>
<body>
<div class="container">
<table class="table table-bordered table-striped">
<thead>
<tr class="success">
<th>序号</th>
<th>题名(详细信息)</th>
<th>责任者</th>
<th>出版社</th>
<th>标准号</th>
<th>出版年</th>
<th>索书号</th>
<th>馆藏数</th>
</tr>
</thead>
<tbody>
<?php
$book=$_GET['book'];
$book_name=urlencode(mb_convert_encoding($book,'gb2312','utf-8' ));
$cs=book($book_name);
for ($j=0; $j<count($cs)-1; $j++) {
if($j%8==0){
echo "<tr>";
}
echo "<td>".$cs[$j]."</td>";
if($j%8==8){
echo "</tr>";
}
}
function book($book_name){
$ch1 = curl_init();
$url = "http://121.33.188.47:22995/opac_two/search2/searchout.jsp";
$data1="library_id=A&recordtype=all&kind=simple&suchen_word={$book_name}&suchen_type=1&suchen_match=qx&kind=simple&show_type=wenzi&snumber_type=Y&search_no_type=Y&searchtimes=1&size=2000&curpage=1&orderby=pubdate_date&ordersc=desc&page=1&pagesize=2000";
curl_setopt($ch1, CURLOPT_URL,$url);
curl_setopt($ch1, CURLOPT_POST, 1);
curl_setopt($ch1, CURLOPT_POSTFIELDS, $data1);
curl_setopt($ch1, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch1, CURLOPT_HEADER, 0);
curl_setopt($ch1, CURLOPT_USERAGENT, 'Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9.1.5) Gecko/20091102 Firefox/3.5.5');
$result=curl_exec($ch1);
curl_close($ch1);
$res=mb_convert_encoding($result, "utf-8", "gb2312");
$str1 = preg_replace("/<a[^>]*>/","", $res);
$str2 = preg_replace("/<\/a>/","", $str1);
$pattern='#<td.+?>(.+?)</td>#';
preg_match_all($pattern, $str2, $n);
foreach ($n as $k => $v) {
$cs=array_slice($v, 11);
}
return $cs;
}
?>
</tbody>
</table>
</div>
</body>
</html>