目录
1D 相关
Matlab中的互相关
互相关实战
在某种意义上,这些过滤器的比例,乘法比例是相同的。
否则,相关性将按其差异进行缩放,在这里,我将介绍它,我们将规范化我们的过滤器。
比方说,通过使它们所有像素的标准偏差等于1,我们可以说:
这将是一种方法,因为当我上下调整过滤器时,其标准偏差会增大和缩小。
我将不再做出标准偏差,恰好是一个。如果你有一个常数,这是一个问题。不要担心这个问题。
我们将尝试使其标准偏差为1。
那么我们要做的另一件事是,假设我有两张实际上相同的图像。除了一个刚刚乘以某个常数。
那么如果我相关,即使是我的规范化内核,也就是那个乘以常量的内核,总值也会成倍增加。
所以当我们这样做时,称为归一化相关。我们做两件事。
正如我们所说,我们将过滤器标准化。
然后当我们将滤波器粘贴在一小块像素上时,我们会缩放该贴片,因此它的标准偏差也是一个,然后我们计算相关性,
当我们移动滤波器时,我们会改变图像比例,因为像素是不同的。这就是所谓的归一化相关性。
因此,对于我要向您展示的其余内容,我将进行标准化相关。
1D 相关
回到我们的计划。
我们将使用1D信号来介绍它,然后我们将转到2D。
所以这里我们有一个信号(Signal),它是一个1D信号,下面是一个滤波器(Filter)。如图:

那个过滤器,实际上这个过滤器看起来很像,信号红色圆圈的东西。如图:
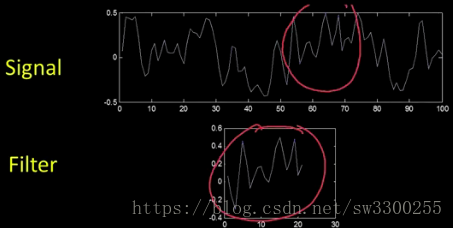
这是因为我做了这件事,实际上我把图像其中一小部分截取出来了,但是系统还不知道。
我们要做的是我们要对这个滤波器与该信号进行归一化互相关。
当你这样做时,你得到一个看起来像这样的结果。如图:

你会发现它的最大值是在这个峰值,这个峰值在这里是红色的。就在这里:

这就是这个过滤器从那个信号中出来的位置。如图:
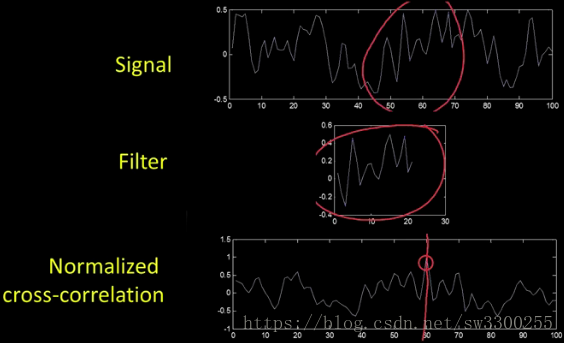
所以最高的价值恰恰是这两个图像匹配的时候出现。
有几个理由可以解释,这是我最喜欢的一个:
假设我们的两个信号都被归一化,或者有点移动,以便它们大约为零。它们有时是正的,有时是负的。
请记住我们得到的比例是近似相同的,因为标准差是1。
内部原理:如果我拿一个过滤器,我把它放在图像上,我要把它们相乘然后加起来,最后看最大值就是那小块图片。
但这里请记住一些细节,图像的一些值是正的,其中一些值可能是负的。
我意识到这是我们第一次谈论负信号。下面让我解释一下:
事实上,在这里的图纸上你会发现它在中间是零。如图:
但是,如果我得到正的和负的,并且我的滤波器中有正的和负的,如果我想进行乘法并使其尽可能高,那么何时会发生?
显而易见,只要我的图像中的像素为正,我希望我的滤波器中的系数为正。因为正正得正。
如果图像是负的,我还想要什么呢? 我希望滤波器系数也是负的。因为负负得正。
无论如何,如果你认为有一个过滤器,因为我们已经缩放了它,它就不能让它任意的高和任意的低。
如果你得到的信号准确地排列起来,那么无论它是正的,另一个都是正的,其中一个是负的,另一个是负的,你得到最大值。
有很多更复杂的方法来展示这种分布和类似事物的差异。
它们基本上都会向您展示您可以获得的最大价值。
它们的最后得出的图像匹配结果是完全相同的。
Matlab中的互相关
我们也可以在二维空间中做同样的事情。
这是一个不同的胡椒图像。右边这是胡椒图像的一小部分,碰巧也有一些大蒜。如图:
>> onion = rgb2gray(imread('onion.png'));
>> peppers = rgb2gray(imread('peppers.png'));
>> imshowpair(peppers, onion, 'montage');运行代码,结果为:
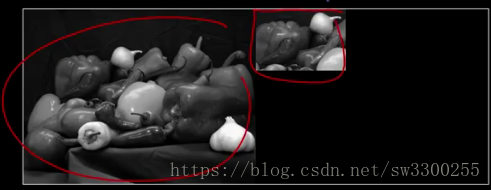
从这里开始截取的。如图:
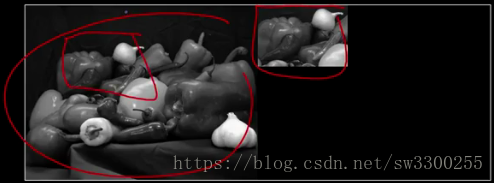
我可以在整个图像上对这个小块图片进行归一化相关。
我可以把它画出来。当你这样做时,你会得到这个。
>> c = normxcoor2(onion, peppers);
>> figure, surf(c), shading flat;运行结果,如图:

好的。你看到这里的小尖峰了吗?如图:
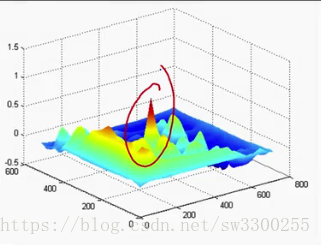
当滤波器在图像中正好落在现场时发生的这种情况。
你再一次得到这个:正面与正面对齐,负面与负面对齐。
互相关实战
让我们写一些代码。
我们将从一维数据开始。
给定一个离散信号 s 作为一个向量和一个模板 t,我们的工作是找到模板在信号中出现的位置。如下:
>> s = [-1 0 0 1 1 1 0 -1 -1 0 1 0 0 -1];
>> t = [1 1 0];这就像在较长的字符串中查找子字符串一样。
我们在这里玩的是数值,它有一些含义。
注意,这里我们希望找到模板出现的起始索引。
让我们打印出信号和模板,看看我们是什么意思。
这里,我们使用冒号来生成列号序列。大小是s,2是s中的列数。如下:
>> disp('Signal:'), disp([1:size(s, 2); s]);
>> disp('Template:'), disp([1:size(t, 2); t]);让我们看看输出是什么样子的:

最上面一行是列数索引。

你能找到模板吗? 是的。它位于这里。如图:
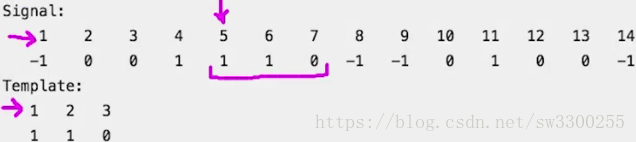
从信号的下标5开始。
这就是我想让你们做的。
我想让你们写一个函数find_template_1D。
它需要两个参数,t 和 s,模板和信号。它应该返回索引,在s中找到模板。
一旦找到索引,我们应该能够显示它。
你可以自己先不看答案做。
这里,我们可以一起来做,以下模版代码:
>> pkg load image;
>>
>> function index = find_template_1D(t, s)
c = normxcorr2(t, s);
endfunction
>>
>> s = [-1 0 0 1 1 1 0 -1 -1 - 1 0 0 -1];
>> t = [1 1 0];
>> disp('Signal'), disp([1:size(s, 2); s]);
>> disp('Template'), disp([1:size(t, 2); t]);
>>
>> index = find_Template_1D(t, s);
>> disp('Index'), disp('Index');正如你可能已经猜到的,我们想使用归一化互相关(Normalized Cross Correlation)。
normxcorr2函数:是将模板 t 与信号 s 相关联,并返回一组规范化值。
您可以使用max函数找到这个结果集中的最大值,这对应于最佳匹配位置。
当给定两个输出参数时,max实际上也可以返回最大值的索引。
(在函数find_templeat_1D添加代码:[maxVlaue, index] = max(c);)
>> pkg load image;
>>
>> function index = find_template_1D(t, s)
c = normxcorr2(t, s);
[maxVlaue, index] = max(c);
endfunction
>>
>> s = [-1 0 0 1 1 1 0 -1 -1 - 1 0 0 -1];
>> t = [1 1 0];
>> disp('Signal'), disp([1:size(s, 2); s]);
>> disp('Template'), disp([1:size(t, 2); t]);
>>
>> index = find_Template_1D(t, s);
>> disp('Index'), disp('Index');让我们看看结果:

返回的索引是7。
但正确答案应该是5。如图:

发生了什么事?
互相关函数(normxcorr2)实际上是从模板和信号重叠的第一个点开始比较的。
在这里,模板有三个元素。如图:

比较从模版的第三个元素 和 信号的第一个元素重叠开始。

窗口从那一点向前移动直到结束和超出。

操作在最后一个重叠点停止。
我们来看看c的值,看看是否真的是这样。
我们在这里使用相同的技巧来显示列号,为了清晰起见,我们将注释掉其他输出代码。
>> pkg load image;
>>
>> function index = find_template_1D(t, s)
c = normxcorr2(t, s);
disp([1:size(c, 2); c]);
[maxVlaue, index] = max(c);
endfunction
>>
>> s = [-1 0 0 1 1 1 0 -1 -1 - 1 0 0 -1];
>> t = [1 1 0];
>> %disp('Signal'), disp([1:size(s, 2); s]);
>> %disp('Template'), disp([1:size(t, 2); t]);
>>
>> index = find_Template_1D(t, s);
>> %disp('Index'), disp('Index');正如我们在这里看到的,我们有16个值。如图:
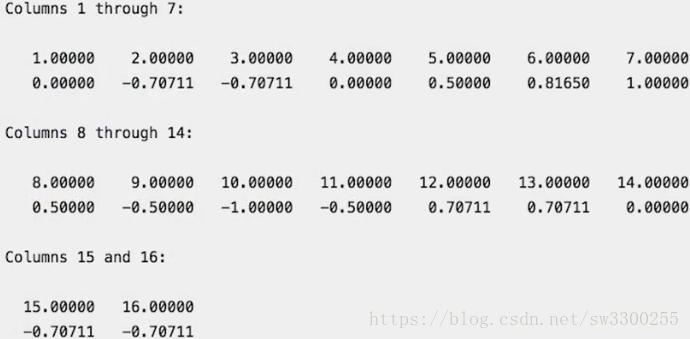
我们的信号是14。
前两个系数来自模板部分,在信号外的位置。如图:
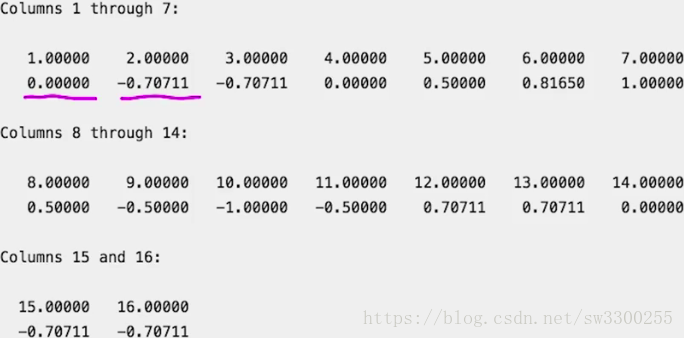
因此,索引3,即模板的长度对应于信号中的第一个位置。
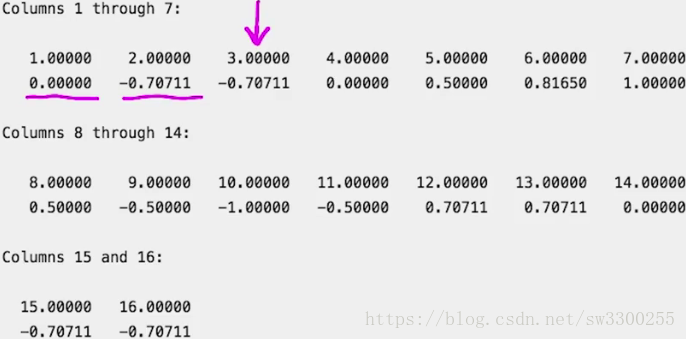
在返回索引值时,我们必须考虑到这个偏移量。
可以这样考虑,max返回的索引值是rawIndex。
为了得到正确的索引,我们需要减去模板的大小并添加一个。
>> pkg load image;
>>
>> function index = find_template_1D(t, s)
c = normxcorr2(t, s);
%disp([1:size(c, 2); c]);
[maxVlaue, rawIndex] = max(c);
index = rawIndex - size(t, 2) + 1;
endfunction
>>
>> s = [-1 0 0 1 1 1 0 -1 -1 - 1 0 0 -1];
>> t = [1 1 0];
>> disp('Signal'), disp([1:size(s, 2); s]);
>> disp('Template'), disp([1:size(t, 2); t]);
>>
>> index = find_Template_1D(t, s);
>> disp('Index'), disp('Index');让我们恢复原来的输出行并查看输出。

现在我们有了正确的索引:5。
这是在信号中找到的模板的起始位置。
让我们尝试一个不同的模板:t = [0 -1 -1 0]
>> pkg load image;
>>
>> function index = find_template_1D(t, s)
c = normxcorr2(t, s);
%disp([1:size(c, 2); c]);
[maxVlaue, rawIndex] = max(c);
index = rawIndex - size(t, 2) + 1;
endfunction
>>
>> s = [-1 0 0 1 1 1 0 -1 -1 - 1 0 0 -1];
>> t = [0 -1 -1 0];
>> disp('Signal'), disp([1:size(s, 2); s]);
>> disp('Template'), disp([1:size(t, 2); t]);
>>
>> index = find_Template_1D(t, s);
>> disp('Index'), disp('Index');运行代码,如下:

正如预期的那样,模板在位置7找到。
注意,我们不受具有精确匹配的模板的约束。
例如,我们可以尝试只在信号中部分出现的模板。t = [1 1 1 0 0]
>> pkg load image;
>>
>> function index = find_template_1D(t, s)
c = normxcorr2(t, s);
%disp([1:size(c, 2); c]);
[maxVlaue, rawIndex] = max(c);
index = rawIndex - size(t, 2) + 1;
endfunction
>>
>> s = [-1 0 0 1 1 1 0 -1 -1 - 1 0 0 -1];
>> t = [1 1 1 0 0];
>> disp('Signal'), disp([1:size(s, 2); s]);
>> disp('Template'), disp([1:size(t, 2); t]);
>>
>> index = find_Template_1D(t, s);
>> disp('Index'), disp('Index');运行代码,如下:
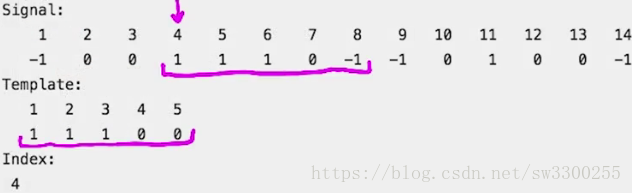
令人印象深刻。
模板被找到在正确的位置,即使有一个不匹配。如图:

部分失配会导致相关系数小于1。
但它可能仍然是所有其他元素的最大值。
——学会编写自己的代码,才能练出真功夫。