python爬虫常用库之bs4
bs4全名BeautifulSoup,是编写python爬虫常用库之一,主要用来解析html标签。
1.安装
pip install beautifulsoup4
或
python -m pip install beautifulsoup4安装 Requests
这部分文档包含了 Requests 的安装过程,使用任何软件的第一步就是正确地安装它。
pip install requests
要安装 Requests,只要在你的终端中运行这个简单命令即可:
$ pip install requests
如果你没有安装 pip (啧啧),这个 Python installation guide 可以带你完成这一流程。
获得源码
Requests 一直在 Github 上积极地开发,你可以一直从这里获取到代码。
你可以克隆公共版本库:
git clone git://github.com/kennethreitz/requests.git
也可以下载 tarball:
$ curl -OL https://github.com/requests/requests/tarball/master
# Windows 用户也可选择 zip 包
获得代码之后,你就可以轻松的将它嵌入到你的 python 包里,或者安装到你的 site-packages:
$ cd requests
$ pip install 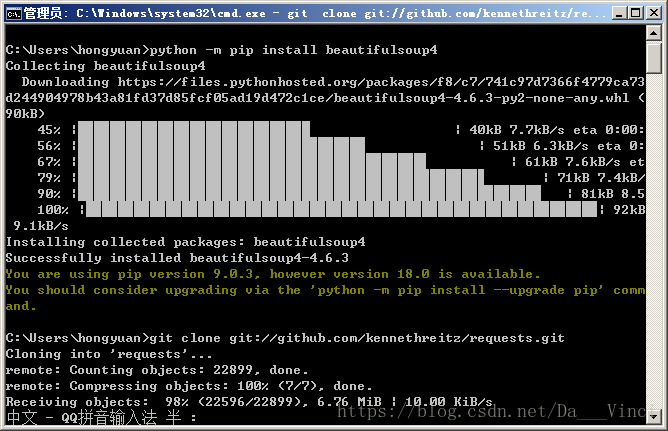
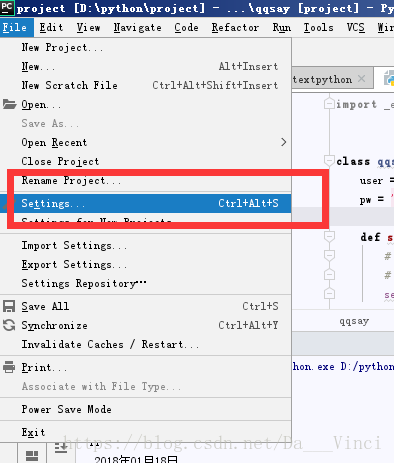
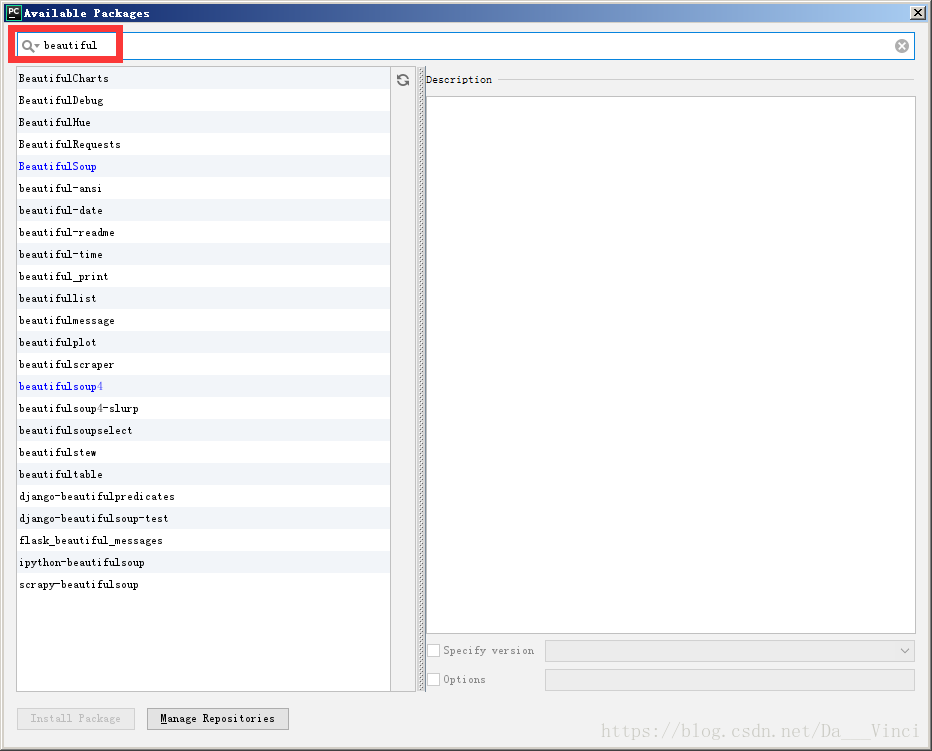
包安装:

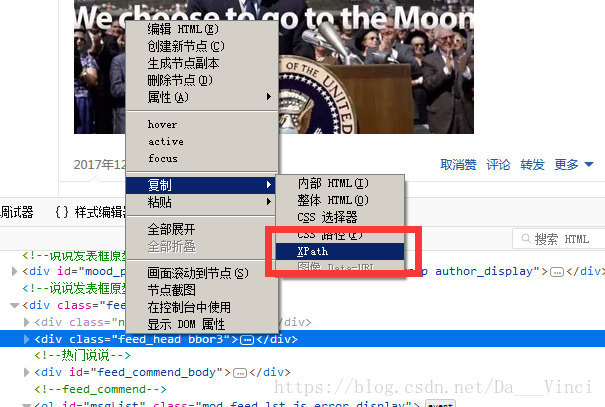
XPATH和元素节点获取获取:
右键查看元素:左边是节点选择器
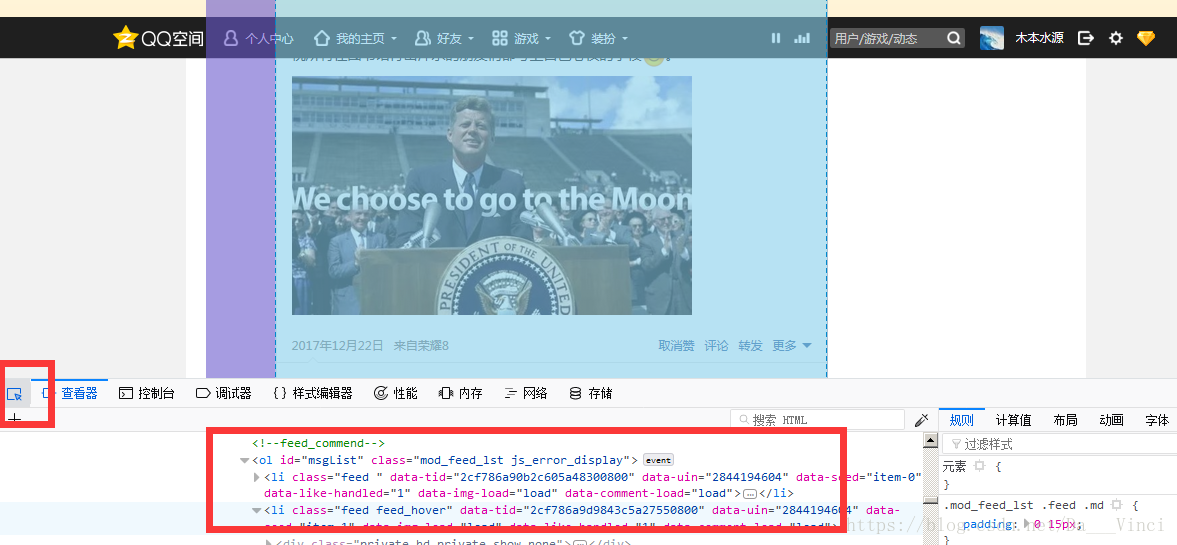
选择一个节点,可获得XPATH
代码和注释:
#coding:utf-8
import unittest
import time
from selenium import webdriver
from bs4 import BeautifulSoup
import _elementtree
class qqsay:
user = '***' # 你的QQ号
pw = '***' # 你的QQ密码
def setUp(self):
# 调试的时候用firefox比较直观
# self.driver = webdriver.PhantomJS()
self.driver = webdriver.Firefox()
def testEle(self):
driver = self.driver
# 浏览器窗口最大化
driver.maximize_window()
# 浏览器地址定向为qq登陆页面
driver.get("http://i.qq.com")
# 很多时候网页由多个<frame>或<iframe>组成,webdriver默认定位的是最外层的frame,
# 所以这里需要选中一下frame,否则找不到下面需要的网页元素
driver.switch_to.frame("login_frame")
# 自动点击账号登陆方式
driver.find_element_by_id("switcher_plogin").click()
# 账号输入框输入已知qq账号
driver.find_element_by_id("u").send_keys(self.user)
# 密码框输入已知密码
driver.find_element_by_id("p").send_keys(self.pw)
# 自动点击登陆按钮
driver.find_element_by_id("login_button").click()
# 如果登录比较频繁或者服务器繁忙的时候,一次模拟点击可能失败,所以想到可以尝试多次,
# 但是像QQ空间这种比较知名的社区在多次登录后都会出现验证码,验证码自动处理又是一个
# 大问题,本例不赘述。本例采用手动确认的方式。即如果观察到自动登陆失败,手动登录后
# 再执行下列操作。
r = ''
while r != 'y':
print "Login seccessful?[y]"
r = raw_input()
#手动确认一下
# 让webdriver操纵当前页
driver.switch_to.default_content()
# 跳到说说的url
#driver.get("http://user.qzone.qq.com/" + self.user + "/311")
driver.find_element_by_link_text("说说").click()
# 访问全部说说需要访问所有分页,需要获取本页数据后点击“下一页”按钮,经分析,“下一页”
# 按钮的id会随着点击的次数发生变化,规律就是每点一下加一,所以需要在程序中动态的构造
# 它的id。(或者不用id改用xpath)
next_num = 0 # 初始“下一页”的id
while True:
# 下拉滚动条,使浏览器加载出动态加载的内容,可能像这样要拉很多次,中间要适当的延时(跟网速也有关系)。
# 如果说说内容都很长,就增大下拉的长度。
driver.execute_script("window.scrollBy(0,10000)")
time.sleep(3)
driver.execute_script("window.scrollBy(0,20000)")
time.sleep(3)
driver.execute_script("window.scrollBy(0,30000)")
time.sleep(3)
driver.execute_script("window.scrollBy(0,40000)")
time.sleep(5)
# 很多时候网页由多个<frame>或<iframe>组成,webdriver默认定位的是最外层的frame,
# 所以这里需要选中一下说说所在的frame,否则找不到下面需要的网页元素
# 让webdriver操纵当前页
frame = driver.find_element_by_class_name("app_canvas_frame")
#也可以通过XPATH查找ifeame
driver.switch_to.frame(frame)
soup = BeautifulSoup(driver.page_source, 'lxml') #xml,html亦可
contents = soup.find_all('pre', {'class': 'content'}) # 内容
times = soup.find_all('a', {'class': 'c_tx c_tx3 goDetail'}) # 发表时间
print contents.__len__()
print times.__len__()
for content, _time in zip(contents, times): # 这里_time的下划线是为了与time模块区分开
print content.get_text(), _time.get_text()
# 当已经到了尾页,“下一页”这个按钮就没有id了,可以结束了
if driver.page_source.find('pager_next_' + str(next_num)) == -1:
break
# 找到“下一页”的按钮
elem = driver.find_element_by_id('pager_next_' + str(next_num))
# 点击“下一页”
elem.click()
# 下一次的“下一页”的id
next_num += 1
# 因为在下一个循环里首先还要把页面下拉,所以要跳到外层的frame上
driver.switch_to.parent_frame()
def tearDown(self):
print 'down'
if __name__ == "__main__":
q = qqsay()
q.setUp()
q.testEle()
测试结果:
D:\python\project\venv\Scripts\python.exe D:/python/project/qqsay
Login seccessful?[y]
y
9
11
2018年01月18日
我们选择登月, 我们选择在这个十年登月以及选择实现其他目标,不是因为它们容易,而是因为它们困难---约翰•肯尼迪
祝所有在图书馆付出汗水的朋友们都考上自己心仪的学校。 2018年1月18日
转 2017年12月22日
古色古香 2017年11月18日
发表图片 2017年11月18日
挺好>>查看我的兵种 2017年7月15日
发表图片 2016年7月31日
博大精深 源远流长 2016年7月30日
五一劳动节,劳动人民美丽 2016年7月24日
Process finished with exit code 0