无人驾驶汽车系统入门(二十三)——迁移学习和端到端无人驾驶
前面我们介绍了神经网络和深度学习的基础知识,在本文中我们将介绍迁移学习的概念,并将迁移学习应用于端到端无人驾驶模型。一般来说,大型深层神经网络的训练对计算资源要求较高。然而,很多普通开发者只拥有简单的深度学习计算环境,这成为阻碍深度学习广泛应用的瓶颈之一。例如,为了训练一个深度为50层的残差神经网络,利用NVIDIA M40 GPU需要大约14天才能完成模型训练。如果换做普通PC机可能需要几十年的时间才能完成训练。对于此类问题,采用迁移学习是一种比较好的策略。
端到端无人驾驶,是无人驾驶中的一项基本技术,在实施过程中仅利用无人车上装载的摄像头获取路况的图像数据来训练深层神经网络模型,之后将摄像头采集到的实时路况图像数据输入到训练好的深度模型,并输出控制参数来决定无人车的驾驶策略。本质上端到端无人驾驶是一个简化的无人车模型,而实际路况的处理可能非常复杂,但它可以很直观地帮助我们理解深度学习在无人驾驶中的应用。
创作不易,转载请私信本人并注明出处:https://blog.csdn.net/AdamShan/article/details/82414275
系列博客已整编至机械工业出版社《无人驾驶原理与实践》一书,书籍对博客内容进行了大量的勘误和扩充,预计年底出版,感谢关注!
迁移学习
深度学习在工业界得到越来越广泛地应用。但是,从头搭建并训练深度学习模型是一件耗时耗力的事,工程师需要重新设计网络架构,并进行大量训练和测试实验才能得到合适的模型。一个好的策略是采用一个现有的深度学习模型,在原始模型的基础上进行微调来适应新的应用场景,这就是迁移学习(Transfer Learning)[1]。
因此,在开发深度学习应用时,并不一定需要从头开始训练模型。目前很多常见的应用场景都已经有相关的研究团队训练出了高精度的深度学习模型。ImageNet[2]数据集是一个拥有1600万张图片的大规模数据集,这些图片数据已经由网上的大量志愿者进行了标记,该数据集涵盖了生活中很多重要的图像应用,因此是一个非常有价值的公开数据集。针对ImageNet数据集的识别分类等问题,最著名的是ImageNet挑战赛(ImageNet Large Scale Visual Recognition Challenge, ILSVRC)。ImageNet挑战赛虽然已经于2017年终止,但是其中涌现出了很多针对ImageNet数据集的优秀识别模型,例如AlexNet、VGGNet、Google Inception Net和ResNet等。迁移学习可以方便地将这些经典模型移植到新的应用场景,这主要取决于两个因素:新应用的数据量大小,新应用和原始模型的相似度。一般来说,迁移学习主要适用于四种应用场景,如下表所示。
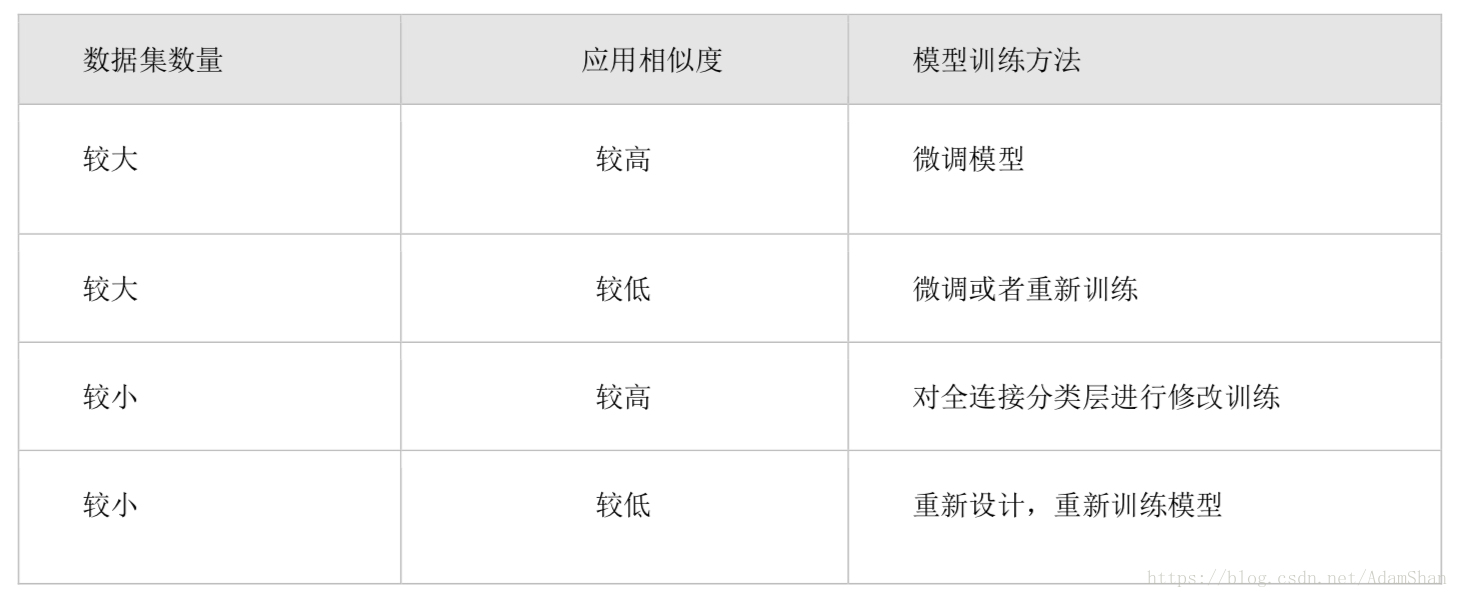
第一种情况,如果要开发一个常见且数据量大的物体识别应用,就可以直接借鉴这些成熟的优秀模型。实际操作中,我们只需要下载这些模型的权值并载入模型,之后将新的数据集输入网络进行微调即可得到理想的模型。
第二种情况是新的应用数据集比较大,但是并没有合适的预训练模型。这种情况下,数据集多采集于专用的应用场景,例如医学图像识别。处理这种情况可以先选择一个深度学习模型,利用新数据进行微调,如果效果不理想就需要采用新数据重新训练该模型。
第三种情况是新的数据量比较小,但是已经有相似的识别模型。例如,要基于一个部门的几十名员工做一个人脸识别应用,可以简单的从网上下载训练好的基于卷积神经网络的人脸识别分类模型,然后将新数据输入该模型进行前向传播,在得到全连接层之前的数据输出以后,停止前向传播并将这些输出数据当作全连接层的输入、原始输出作为全连接层的输出进行训练。换句话说,在整个训练过程中,我们保持卷积和池化这些层的参数不变,同时也保持了原网络的特征提取能力。全连接层实际上是对卷积和池化层提取的人脸特征进行分类工作,因此,对全连接层的重新训练可以使得新模型能够适应新数据的分类情况。用于图像识别的深度卷积神经网络可能非常复杂,需要较长的训练时间,但是在该情况下整个训练过程实际的计算只有样本数据的一次前向传播过程和针对全连接层(通常不超过两层)的反向传播训练。因此,可以极大减少模型的训练时间,提高开发效率。
最差的情况是新的训练数据集比较少,同时也没有现成的相似模型可用。此种情况下,一般可以考虑重新设计网络模型,并对新设计的网络模型进行训练,以求得最好的预测效果。因为没有成功模型的借鉴,无论网络设计还是模型训练都需要花费很多时间,但也因此使得重新设计训练的模型在本领域具有更高的学术和工程价值。
端到端无人驾驶
深度学习在无人驾驶领域扮演着重要角色,其中,基于深层神经网络的端到端无人驾驶技术就是很重要的一环。在实践中,一般先采用模拟器模拟端到端无人驾驶的效果。端到端无人驾驶的基本思路非常简单:首先通过人为操作车辆(模拟器)行驶来采集控制数据。在该过程中,需要记录下当前车辆前方的道路场景图像,这些图像通常由摄像头采集。在实践中,为了提高模型的泛化能力可以使用多个(例如三个)摄像头同时采集不同角度的路况图像。在采集不同路况场景的同时,需要记录下人在驾驶车辆(正确操作)时的控制参数,例如方向盘的转角、刹车和油门等。在训练深层神经网络模型的时候,采集到的路况图像数据作为模型的输入参数,汽车的控制参数作为模型的输出数据。基于这些路况图像和控制参数训练完神经网络模型之后,该模型就具有一定的能力对当前摄像头采集到的路况场景进行预测,进一步可以给出车辆的控制参数,这些参数被输入到汽车线控单元(或者作为模拟器输入参数),从而达到控制车辆自动行驶的目的。
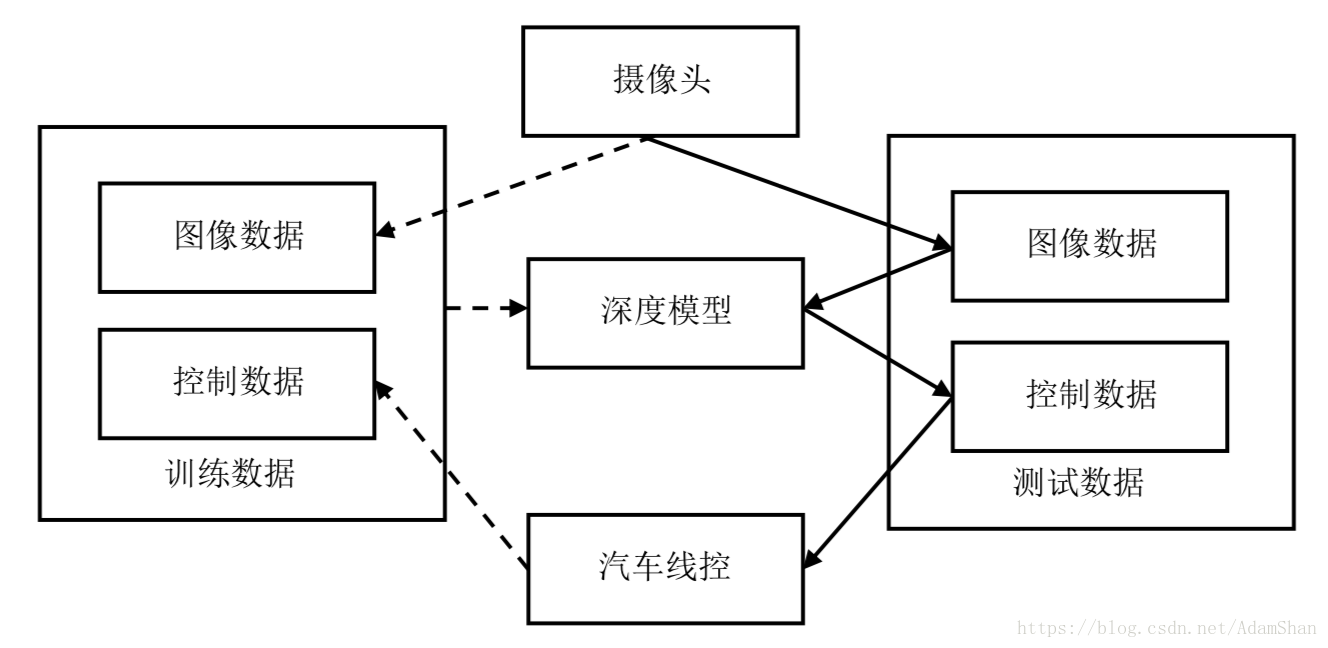
如上图所示,端到端无人驾驶的核心为深度学习模型。通过实时驾驶过程采集到不同路况场景的图像数据,同时记录不同路况下人类对汽车的控制参数。这些数据作为训练数据被输入到深度学习模型进行训练。在利用深度学习模型控制汽车自动驾驶时,通过摄像头采集实时路况图像,并将图像输入深度学习模型得到汽车线控参数,这些参数可以控制汽车自动驾驶。因此,端到端无人驾驶实际上是一个非常简洁的无人驾驶模型,它忽略掉除摄像头以外的其它传感器采集的数据信息,仅仅根据摄像数据进行操作决策。这在实际无人驾驶中肯定是不合适的,但作为研究,我们可以测试深度学习模型对无人汽车的控制能力。
端到端无人驾驶模拟
在模拟端到端无人驾驶的时候,需要几个组件,包括模拟器、图像处理、深度学习框架等。
模拟器的选择
为了模拟深度学习模型对无人车的控制,可以在PC上通过无人车模拟器来实现。Udacity[3]是一个在线教育机构(非常适合于自学者),它也提供了无人驾驶汽车模拟器,有关该模拟器的细节我们可以在GitHub上找到详细说明[4]。GitHub上还有很多开源的无人车模拟器供我们研究使用,在实验的时候可以灵活地选择,但重要的是模拟器要能够实时采集路况图像数据和控制数据。在训练自动驾驶模型之前,需要先采集一遍训练数据,该训练数据由图像数据作为模型输入,相应的控制数据作为模型输出。为了简化问题,可以将模拟器的运行速度设置为固定值,这种情况下,我们只需要方向盘的控制参数就可以控制汽车模拟器进行无人驾驶。整体而言,构建这种深度学习模型最常见的就是卷积神经网络模型,输入为图片数据,输出为单个控制参数。
数据采集和处理
(1) 对于数据采集操作,有如下几个基本原则:
- 需要不断控制汽车回到道路中心位置。端对端无人驾驶就是让模型学习如何控制汽车行驶在道路中央,所以在采集数据时,需要稳定地控制汽车行驶在道路中心,并尽量保持平稳行驶,这样更符合人类对汽车的实际操控。
- 除了平稳的环境,还要让汽车尽量多在弯曲道路行驶,从而使得模型可以对需要转弯的路况做出正确的控制操作。
- 应该尽可能让汽车尝试在更多路况下的驾驶操作。实际上我们需要采集更多的驾驶数据来泛化模型的操作能力,使得模型对更多的未知状况做出正确的控制预测,甚至可以采集倒车等情况下汽车的控制数据,使得模型在极端情况下也能做出正确反应。对于采用模拟器的情况,建议至少采集十圈以上的无人驾驶正确行驶状况下的操作数据来训练端到端模型,从而提高模型泛化能力。
- 可以采用多个摄像头搜集不同角度的路况信息,例如从汽车的左、中、右三个角度同时搜集路况图像数据,一方面,增加了数据量,从而提高模型泛化能力;另一方面,不同角度的路况可以为模型提供更合适的决策判断。
- 图像采集帧率不宜太高,否则会采集到很多内容重复或者相似的路况数据。这种情况下部分测试集里的样本已经出现在了训练集里,这将导致模型的测试精度虚高。另外,这不但会造成计算资源的浪费,还会使得训练好的模型频繁对模拟器发出相似的控制信号。一般情况下,路况图像的采集帧率应控制在10帧/秒左右。
(2) 对采集到的数据,应该执行如下预处理操作:
- 所有图像应该裁剪成合适大小,例如NVIDIA无人驾驶模型标准为66像素高,200像素宽。还应该裁剪掉一部分对模型决策不起作用的图像区域,例如摄像头拍摄到图像下端的汽车底盘和上端的天空云彩等图像内容。一些深度学习库(例如Keras)已经自带了图像裁剪函数,而使用GPU会使得操作效率更高。
- 对图像像素值采用归一化操作,实际上,像素值范围为0到255,因此可以按照下式将像素值x变换到[-1, 1]的范围内。在该范围里,神经网络的激活函数可以更好地工作。在Python语言里,可以定义如下操作归一化图像像素值:
lambda x: x / 127.5 - 1.0深度神经网络模型构建
在构建端到端神经网络控制模型时,可以尝试多种神经网络结构。最常见的神经网络结构是全连接神经网络,我们开始可以尝试一个四层全连接神经网络模型(含两个隐藏层),利用采集到的数据训练好模型以后,就可以利用训练好的模型输出控制参数到汽车模拟器。有些开源模拟器已经自带了无人驾驶模式,这种情况下,只需要模拟器打开自动驾驶模式,就可以利用训练好的深度学习模型控制汽车执行自动驾驶操作。
实际操作中,四层全连接神经网络的效果并不好,我们需要设计合适的深度神经网络模型。根据之前的迁移学习理论,我们可以将一些经典图像识别模型迁移到该任务上,该任务属于数据集较大,但是应用相似度较低的任务。因此,我们可以借鉴经典模型的结构,然后利用新采集的数据重新训练模型或者微调模型。
前面章节,我们已经介绍了一些卷积神经网络相关的内容。实际上,卷积神经网络特别适合处理二维图像问题。端到端无人驾驶模型的输入为路况图像,因此可以尝试采用卷积神经网络来构建模型。实际上,我们可以借鉴很多经典深度模型的设计经验,迁移到端到端无人驾驶的深度模型构建中。
LeNet深度无人驾驶模型
很多经典的用于图像的神经网络模型都是基于卷积神经网络模型,LeNet[5]是最早用于商业手写数字识别的卷积神经网络模型,现在重构的LeNet和原来的结构有一些差别,但是一般仍保留两个卷积层和两个池化层的结构。需要注意的是,现在的LeNet一般采用ReLu系列激活函数取代原始的Sigmoid函数,ReLu函数对图像特征提取具有更好的效果,同时可以极大地节省训练网络和激活网络的计算量。需要注意的另一点是,原生LeNet接收的输入为32×32的灰度(单通道)图像,而我们的模型输入为66×200(高66,宽200)的彩色图象(三通道),因此模型的输入和原生LeNet并不相同。为了方便,在构建模型时卷积操作对输入特征图的填充方式(padding)采用same填充且步长(stride)为1,这种情况下经卷积得到的特征图大小和输入特征图大小一致。池化层采用常见的宽高均为2的池化方式且步长为2,因此池化层可以起到降维的作用(输出特征图为输入特征图大小的四分之一)。在经过两层卷积和两层池化以后,模型连接两个节点数为1024的全连接层,紧接着是模型的输出节点。模型的实际输出不再是原始LeNet的分类函数,而是控制参数。在模拟端到端无人驾驶时,我们只输出一个控制汽车转向的参数(为了方便,我们固定汽车行驶速度),因此整个模型只有一个输出节点。经过改造以后的LeNet无人驾驶模型如下图所示:
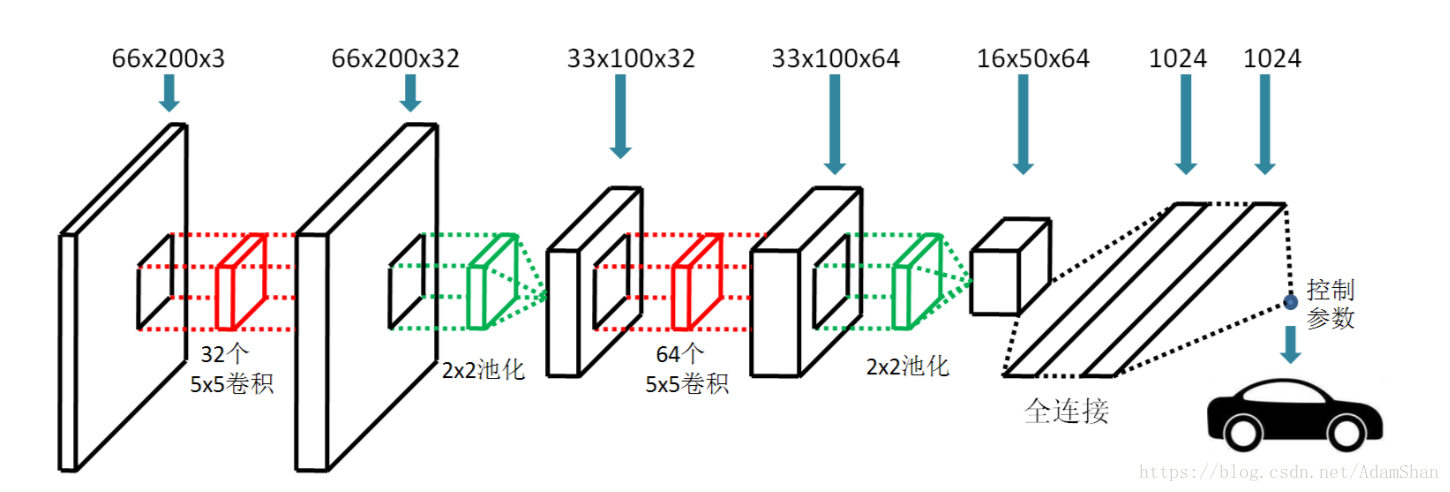
目前有很多深度学习框架可以用来构建深度学习模型,例如TensorFlow、TFLearn、Theano、Caffe、PyTorch、MXNet和Keras等等。其中Keras是一个非常简洁的框架,其后端多采用TensorFlow或Theano,目前Keras已经被Google官方支持。本章节通过Keras库来构建端到端无人驾驶模型。利用Keras深度学习框架(后台采用TensorFlow),我们仅仅需要十几行代码就可以构建并训练上述LeNet模型,代码如下:
model = Sequential()
model.add(Conv2D(32, (5,5), padding='same', activation='relu',
input_shape=(32,32,3)))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(64, (5,5), padding='same', activation='relu',
input_shape=input_shape))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(1024, activation='relu'))
model.add(Dense(1024, activation='relu'))
model.add(Dense(1))
model.compile(loss='mse', optimizer='adam')
model.fit(x_train, y_train, batch_size = 128, epochs = 10,
verbose=1, validation_data=(x_val, y_val))
model.save('selfdriver.h5')其中模型的损失函数loss设置为 均方误差(Mean Squared Error, MSE),其含义为模型对当前输入的路况图像x给出的控制参数与人类(正确)操作汽车时的控制参数之间的差值。优化算法采用自适应矩估计(Adaptive moment estimation,Adam [6])算法,该算法为 随机梯度下降算法(Stochastic Gradient Descent,SGD) 的优化版本。因为Keras和TensorFlow已经对此进行了封装,我们在此也无需深究细节。模型的具体训练只需要调用fit函数并传入训练数据即可,fit函数会执行具体的Adam算法完成自动微分等优化操作。模型训练好以后被保存到’selfdriver.h5’文件,该文件会在模拟器执行无人驾驶时被调用。
在利用上述LeNet训练的模型执行无人驾驶模拟时,可以看出采用LeNet模型的端到端无人驾驶表现要优于采用四层全连接神经网络,车辆的整个行驶过程也基本平稳。但是,从整个驾驶过程可以看出汽车并非如采集的训练数据那样总是行驶在道路中央的最优位置,因此还需要对模型改进。
NVIDIA深度无人驾驶模型
实际上,NVIDIA公司发布了一种端到端无人驾驶模型[7],如下图所示:
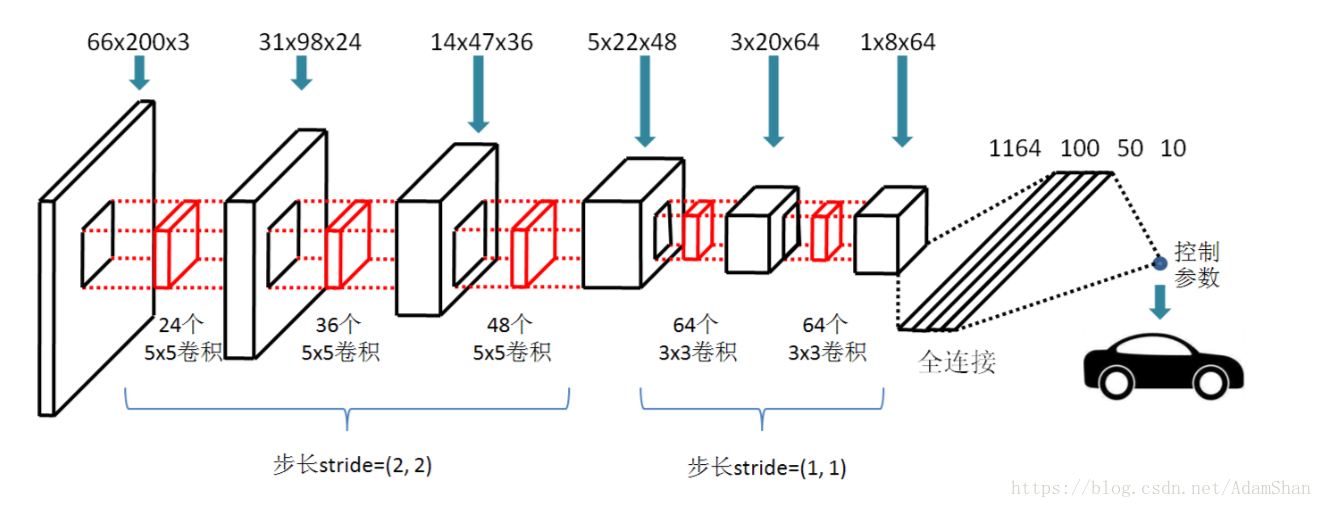
该模型依然采用66×200(高66像素,宽200像素)的三通道彩色输入图像,不同的是,整个模型里不再出现池化操作。输入图像首先经过三次卷积操作,前三次卷积操作的卷积核固定为5×5,卷积核的个数分别为24、36、48依次递增。因为前三次卷积操作均采用2×2的步长,这相当于同时执行了池化操作,且特征图的维度从66×200降到5×22。此后,卷积核的大小降为3×3,卷积核个数设为64,经过两次卷积操作之后特征图的维度降为1×8,至此完成了输入图像的特征提取操作。为了输出合适的控制参数,最后的64个1×8的特征图被拉平(Flatten)以后,连接了4个全连接层,每一层的隐含层节点数分别为1164、100、50和10个,之后是一个输出控制节点。在实践中,为了提升模型的泛化能力,我们在每一个全连接层都使用了丢弃技术(Dropout ),且丢弃率设为0.5。模型的优化依然采用均方误差和Adam优化算法。利用Keras提供的卷积API,我们依然可以非常简洁地实现该模型,其代码如下:
model = Sequential()
model.add(Conv2D(24, (5, 5), strides=(2, 2), activation='relu',
input_shape=(66,200,3)))
model.add(Conv2D(36, (5, 5), strides=(2, 2),activation='relu'))
model.add(Conv2D(48, (5, 5), strides=(2, 2), activation='relu'))
model.add(Conv2D(64, (3, 3), strides=(1, 1), activation='relu'))
model.add(Conv2D(64, (3, 3), strides=(1, 1), activation='relu'))
model.add(Flatten())
model.add(Dense(1164, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(50, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1))
model.compile(loss='mse', optimizer='adam')
model.fit(x_train, y_train, batch_size = 128, epochs = 10,
verbose=1, validation_data=(x_val, y_val))
model.save('selfdriver.h5')在实践中,我们发现NVIDIA提供的无人驾驶模型具有很好的预测性能:经过充分地迭代训练以后,在模拟器里,汽车可以比较平稳地行驶在道路中央。但是,在一些非常崎岖的盘山公路上,长时间的无人驾驶模拟可能会出现操作失误的情况。此时,一方面我们需要采集更多无人驾驶路况场景来增加模型训练样本的数量,另一方面可以通过控制车的行驶速度来保持平稳。控制车的运行速度时,我们可以人为将模拟器中的行驶速度设置为一个较低值,或者将车速当作一个控制参数由深度学习模型学习其规律。这种情况下,深度学习模型的输出有两个节点,分别为转向控制和速度控制。
实际上,我们还可以将很多其它经典深度学习模型迁移到端到端无人驾驶模型的构建中。长短期记忆网络(Long Short Term Memory, LSTM)[8]因为可以记忆历史数据信息而被越来越多的学者研究。目前来看,将LSTM应用到端到端无人驾驶中是一种比较热门的研究方法。LSTM一个很好的特性是可以基于之前的场景来对后续的场景进行决策,从理论上讲也是一种非常适合于端到端模型构建的深度学习模型。一种更好的策略是结合CNN模型的图像特征提取功能和LSTM模型的时序记忆功能,组成混合深度学习模型应用到端到端无人驾驶。利用Keras这种简洁的深度学习库,读者可以很容易构建自己的端到端无人驾驶模型,具体本章不再赘述。
小结
本文主要讲述了迁移学习和端到端无人驾驶的内容。为了更快地开发新的深度学习应用,迁移学习策略经常被应用到工程实践中。虽然很多深度学习应用场景均具有较大的差异性,但是多数情况下我们可以通过微调或者重新训练模型达到新场景的应用目的。最差的情况下,我们依然可以参考一些经典的深度学习模型来设计自己的深度学习应用模型。
端到端无人驾驶是一种非常直观的无人驾驶模型,它忽略了无人车的多种传感器数据,仅仅通过摄像头采集到的路况数据来模拟无人驾驶,从而简化了整个过程,可以作为无人驾驶研究的基础。在探讨端到端无人驾驶模型的时候,我们主要提到了三种深度学习模型:浅层神经网络模型、类LeNet卷积神经网络模型和NVIDIA端到端无人驾驶模型。但是需要明确的是,在真实的无人驾驶环境中,仅仅依靠摄像头采集到的路况图像信息进行驾驶决策显然是不安全的。因此,我们还需要综合考虑多种传感器采集到的数据共同决策。
参考文献
[1] Pan S J, Yang Q. A Survey on Transfer Learning[J]. IEEE Transactions on Knowledge & Data Engineering, 2010, 22(10):1345-1359.
[2] Deng J, Dong W, Socher R, et al. ImageNet: A large-scale hierarchical image database[C]. Computer Vision and Pattern Recognition, 2009. CVPR 2009. IEEE Conference on. IEEE, 2009:248-255.
[3] https://cn.udacity.com/
[4] https://github.com/udacity/self-driving-car-sim
[5] Lecun Y, Bengio Y. Convolutional networks for images, speech, and time series[M].The handbook of brain theory and neural networks. MIT Press, 1998.
[6] Kingma D P, Ba J. Adam: A Method for Stochastic Optimization[J]. Computer Science, 2014.
[7] Bojarski M, Del Testa D, Dworakowski D, et al. End to End Learning for Self-Driving Cars[J]. 2016.
[8] Graves A. Long Short-Term Memory[M].Supervised Sequence Labelling with Recurrent Neural Networks. Springer Berlin Heidelberg, 2012:1735-1780