最近公司用MongoDB,整合一下网上的优缺点,学习下MongoDB
没有找到原作者一:MongoDB的优点和缺点
优点
- 面向文档存储(类JSON数据模式简单而强大)
-
动态查询
-
全索引支持,扩展到内部对象和内嵌数组
-
查询记录分析
-
快速,就地更新
-
高效存储二进制大对象 (比如照片和视频)
-
复制和故障切换支持
-
Auto- Sharding自动分片支持云级扩展性
-
MapReduce 支持复杂聚合
-
商业支持,培训和咨询
缺点
- 不支持事务(进行开发时需要注意,哪些功能需要使用数据库提供的事务支持)
- MongoDB占用空间过大 (不过这个确定对于目前快速下跌的硬盘价格来说,也不算什么缺点了)
- MongoDB没有如MySQL那样成熟的维护工具,这对于开发和IT运营都是个值得注意的地方
- 在32位系统上,不支持大于2.5G的数据(很多操作系统都已经抛弃了32位版本,所以这个也算不上什么缺点了,3.4版本已经放弃支持32 位 x86平台)
没有找到原作者你究竟在什么时候更需要MongoDB
你期望一个更高的写负载
默认情况下,对比事务安全,MongoDB更关注高的插入速度。如果你需要加载大量低价值的业务数据,那么MongoDB将很适合你的用例。但是必须避免在要求高事务安全的情景下使用MongoDB,比如一个1000万美元的交易。
不可靠环境保证高可用性
设置副本集(主-从服务器设置)不仅方便而且很快,此外,使用MongoDB还可以快速、安全及自动化的实现节点(或数据中心)故障转移。
未来会有一个很大的规模
数据库扩展是非常有挑战性的,当单表格大小达到5-10GB时,MySQL表格性能会毫无疑问的降低。如果你需要分片并且分割你的数据库,MongoDB将很容易实现这一点。
使用基于位置的数据查询
MongoDB支持二维空间索引,因此可以快速及精确的从指定位置获取数据。
非结构化数据的爆发增长
给RDBMS增加列在有些情况下可能锁定整个数据库,或者增加负载从而导致性能下降,这个问题通常发生在表格大于1GB(更是下文提到BillRun系统中的痛点——单表格动辄几GB)的情况下。鉴于MongoDB的弱数据结构模式,添加1个新字段不会对旧表格有任何影响,整个过程会非常快速;因此,在应用程序发生改变时,你不需要专门的1个DBA去修改数据库模式。
缺少专业的数据库管理员
如果你没有专业的DBA,同时你也不需要结构化你的数据及做join查询,MongoDB将会是你的首选。MongoDB非常适合类的持久化,类可以被序列化成JSON并储存在MongoDB。需要注意的是,如果期望获得一个更大的规模,你必须要了解一些最佳实践来避免走入误区。
作者:姜健
链接:https://www.zhihu.com/question/20059632/answer/110863218
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
MongoDB的特点和适用场景
实用性
MongoDB是一个面向文档的数据库,它并不是关系型数据库,直接存取BSON,这意味着MongoDB更加灵活,因为可以在文档中直接插入数组之类的复杂数据类型,并且文档的key和value不是固定的数据类型和大小,所以开发者在使用MongoDB时无须预定义关系型数据库中的”表”等数据库对象,设计数据库将变得非常方便,可以大大地提升开发进度。
可用性和负载均衡
MongoDB在高可用和读负载均衡上的实现非常简洁和友好,MongoDB自带了副本集的概念,通过设计适合自己业务的副本集和驱动程序,可以非常有效和方便地实现高可用,读负载均衡。而在其他数据库产品中想实现以上功能,往往需要额外安装复杂的中间件,大大提升了系统复杂度,故障排查难度和运维成本。
扩展性
在扩展性方面,假设应用数据增长非常迅猛的话,通过不断地添加磁盘容量和内存容量往往是不现实的,而手工的分库分表又会带来非常繁重的工作量和技术复杂度。在扩展性上,MongoDB有非常有效的,现成的解决方案。通过自带的Mongos集群,只需要在适当的时候继续添加Mongo分片,就可以实现程序段自动水平扩展和路由,一方面缓解单个节点的读写压力,另外一方面可有效地均衡磁盘容量的使用情况。整个mongos集群对应用层完全透明,并可完美地做到各个Mongos集群组件的高可用性。
数据压缩
自从MongoDB 3.0推出以后,MongoDB引入了一个高性能的存储引擎WiredTiger,并且它在数据压缩性能上得到了极大的提升,跟之前的MMAP引擎相比,压缩比至少可增加5倍以上,可以极大地改善磁盘空间使用率。
其他特性
相比其他关系型数据库,MongoDB引入了”固定集合”的概念。所谓固定集合,就是指整个集合的大小是预先定义并固定的,内部就是一个循环队列,假如集合满了,MongoDB后台会自动去清理旧数据,并且由于每次都是写入固定空间,可大大地提升写入速度。这个特性就非常适用于日志型应用,不用再去纠结日志疯狂增长的清理措施和写入效率问题。另外需要更加精细的淘汰策略设置,还可以使用TTL索引(time-to-live index),即具有生命周期的索引,它允许为每条记录设置一个过期时间,当某条记录达到它的设置条件时可被自动删除。
在某些LBS的应用中,使用MongoDB也有非常巨大的优势。MongoDB支持多种类型的地理空间索引,支持多种不同类型的地理空间查询,比如intersection,within和nearness等。
MongoDB不适用的应用场景
在某些场景下,MongoDB作为一个非关系型数据库有其局限性。MongoDB不支持事务操作,所以需要用到事务的应用建议不用MongoDB,另外MongoDB目前不支持join操作,需要复杂查询的应用也不建议使用MongoDB。
MongoDB云数据库的优势
通常使用MongodB一般有个方案,一是在主机上自己搭建,另外一个就是使用云计算厂商提供的MongoDB云数据库产品。相对自建MongoDB而言,以公有云UCloud的云MongoDB举例,使用MongoDB云数据库主要有以下优势
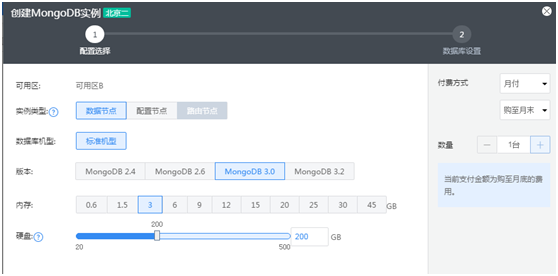
1 部署流程
UCloud是最早提供云MongoDB产品的云计算厂商,相对其他云计算厂商而言,配置也是最为灵活的。UCloud云MongoDB提供了2.4,2.6,3.0和3.2四个最为常用的版本,除了可自定义磁盘容量和内存上限外,客户可根据自身业务需求创建单实例MongoDB,任意节点数量的副本集,任意节点数量的configsvr和mongos,以及选择创建普通磁盘和SSD磁盘的MongoDB。
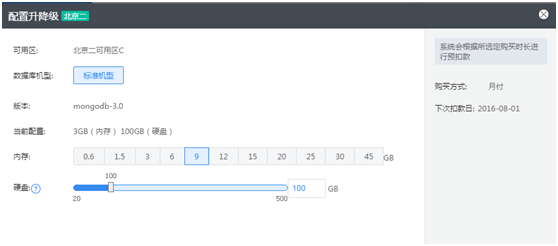
2 弹性扩容和统一管理
弹性扩容是云计算的一个非常巨大的优势,在MongoDB云数据库中,可以非常方便地实现内存在线升降级和磁盘升降级,已经资源的申请和释放,从而最高效地实现了容量规划。另外在自建DB中如果实例达到一定的规模,集中化的管理往往会成为一个较大的运维成本,MongoDB在云数据库中可以根据项目和业务种类进行分组,比如相同的业务使用统一的配置文件,从而有效地减少了运维成本。

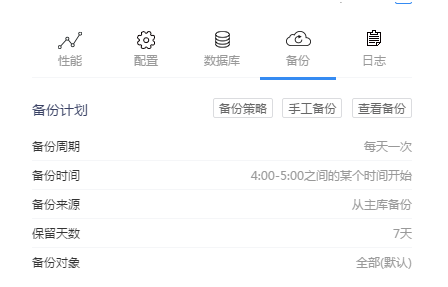
3 备份管理
在自建的MongoDB中,备份的管理往往也较为混乱,另外还需要额外的磁盘空间去存取备份文件。在MongoDB云数据库中,基本上各个云服务商都提供有成熟的备份策略,同样以UCloud举例,它可保存7次自动备份,3次手工备份,并根据自己的业务低峰期设置每天的定时备份时间段,还可以设置是否从secondary节点进行备份
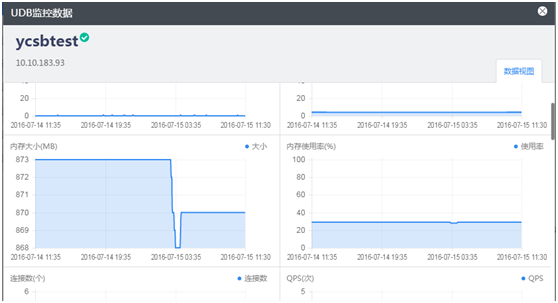
4 监控和告警
自建MongoDB中,数据库本身的监控项一般通过脚本获取mongostat的结果实现,CPU,内存,磁盘使用率等监控项还需要额外再写脚本,并配置好相应的告警策略。使用MongoDB云数据库,可提供非常丰富的监控项和告警策略,及时地发现和处理性能瓶颈。
5 故障处理
使用MongoDB云数据库,当DB所在的物理机出现硬件故障或者DB本身出现性能问题,云计算厂商往往具备非常丰富的故障处理经验,可保障在最短的时间内恢复服务。另外,虽然云数据库虽然禁止客户登陆DB所在的物理机,不过一般云计算厂商比如UCloud可以提供错误日志下载等功能,方便客户去定位故障原因。
迁移到云数据库
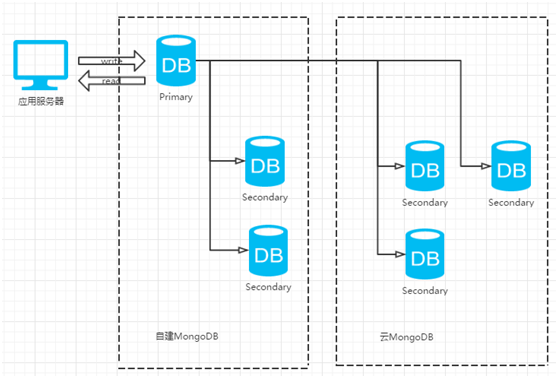
一般MongoDB的迁移上云的策略都是通过副本集的高可用性来实现,不过需要首先保证网络的连通性(这一点一般云计算厂商都会负责或协助打通)。通过将云DB作为自建DB的Secondary节点,当两边的数据达到完成一致,确认数据正常后,手工做一次高可用的切换,使得服务整理从自建DB切换到云DB。当切换完成后,云DB可成功选举成为新的Primary节点,这时即可在新的Primary节点上rs.remove移除自建DB节点,从而实现了MongoDB上云的平滑迁移。下面已自建的MongoDB是三个节点组成的副本集为例,现在想迁移到云上,方案图如下
当数据完全一致后,人为地将旧主库关闭,并将Mongodb云数据库中的一个Secondary节点提升为新的Primary节点
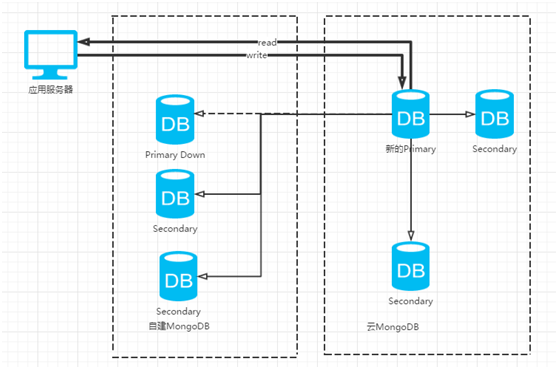
确认业务正常,数据没有问题后,在MongoDB云数据库的Primary节点中挨个删除自建DB的数据节点即可。
另外,部分云计算厂商,比如UCloud已经推出完整的MongoDB数据库上云工具,用户可自行调用API即可实现MongoDB迁移到云数据库。