固定内存
主机默认分配的主机内存是可分页的
固定内存是指页锁定的主机内存
当从可分页主机内存传输数据到设备内存时,CUDA驱动程序首先分配临时页锁定的固定内存,将主机内存上的数据先复制到固定内存中,然后从固定内存传输到设备内存。
cudaMallocHost
cudaFreeHost
零拷贝内存
零拷贝内存是固定内存,并且内存地址映射到设备地址空间,主机和设备都可以访问零拷贝内存。
优点:
cudaHostAlloc
cudaFreeHost
内存层次
内存层次化
Cuda内存模型包括主机内存和设备内存,因此需要考虑传输,除非共享同一块存储设备。实际编程中,需要管理主机内存指针和设备内存指针
数据局部性(认识和利用局部性,产生了内存层次架构,使用更快的更昂贵的存储来形成多级缓冲结构)
1)时间局部性—一个数据被引用后,很可能很快再次被引用;
2)空间局部性—一个数据被引用后,其附近的数据很可能很快被引用;
注:GPU和CPU的内存层次结构使用相似的设计,但是CUDA编程模型使得GPU内存层次结构更好地呈现给开发者,能让我们显示控制其行为(至少可以影响其行为,如L2缓冲无法显示控制,但可以控制其内存事务的颗粒度),提供了更多的可能性。
CUDA内存模型与分类(指的是GPU内的内存)
分类(1)设备端的存储分为可编程的与不可编程的
(1)可编程的(显示地控制数据存放的位置):
l 寄存器
l 共享内存(与一级缓存使用同一个存储设备,支持大小分配)
l 本地内存
l 常量内存
l 纹理内存
l 全局内存
(2)不可编程的(不能决定数据存放的位置):
l 一级缓存(在sm2.0才引入一级缓存;在sm3.2开始,可以利用一级缓存)
l 二级缓存(事务大小可变)
分类(2)设备端的存储分为片上的与片外的
| 注: 共享内存与一级缓存使用同一个存储设备(相同的物理内存实现),支持比例重新分配,可见一级缓存也可显示可控; 每个内存层次都有自己的作用域、生命周期和缓存行为。 因此,设备端的存储根据作用域分为线程本地的、线程块内线程共享的与核函数内线程全局共享的。 |
设备内存
寄存器
一个寄存器的大小为32位,只能装入一个整形或者单精度浮点数,在sm2.0之后,2个寄存器就可以装入64位的数据。
CUDA硬件还支持更宽的内存事务,如int2/float2和int4/float4的数据类型,它们由分别使用对齐2个或者4个寄存器装入。
在核函数中,声明一个没有任何其他修饰符的自变量,通常存储在寄存器中;在核函数中,声明的数组,如果用于引用该数组的索引是常量且能在编译时确定,那么该数组也存在寄存器中。
寄存器别名的使用
Cuda提供了一些内置函数可以强制编译器改变对变量的解释工作,例如将整形解释为单精度浮点数:__int_as_float。
| __int_as_float |
|
float __int_as_float(int i) |
| __float_as_int |
|
int __float_as_int(float f) |
| __double_as_longlong |
|
long long int __double_as_longlong(doulbe b) |
| __longlong_as_double |
|
double __longlong_as_double(long long int) |
| __double2loint |
|
__double2loint |
| __double2hiint |
|
__double2hiint |
| __hiloint2double |
|
__hiloint2double |
|
|
|
|
|
|
|
|
|
|
|
|
本地内存
本地内存(线程范围)
本地内存与全局内存都是由同一个内存设备支持,因此在sm2.0之后,本地内存可以利用L1、L2缓存,访问事务可以自动合并,从而改善性能,硬件用来加载和存储本地内存的指令是特殊的。寄存器溢出会导致2项开销:指令数增加和内存传输数量增加。
本地内存的作用:
实现应用程序二进制接口ABI
容纳寄存器溢出的数据(任何不满足核函数寄存器限定条件的变量,或者可能会占用大量寄存器空间的较大本地结构体和数组)
保存编译器不能解析其索引的数组
共享内存
共享内存(块级范围)
使用__shared__修饰的变量是存放在共享内存中。共享内存是片上内存,是可编程的,与L1缓存共用同一个内存设备,可配置划分分配大小。
全局内存
特点
变量修饰符 __global__
一个全局变量可以被静态声明或者动态声明:
(1)静态声明,不需要手动释放

symbol is a variable that resides in global or constant memory space.
(2)动态内存分配
float *dev_a = 0;
cudaMalloc((void **)&dev_a, sizeof(float));
printf("%d\n", dev_a);
cudaFree(dev_a);
常量内存
常量内存驻留在片外内存上,每个SM中有一个专用的常量缓存(片上)用来缓存,理解为通过常量缓存来访问全局内存。
纹理内存
纹理内存驻留在片外内存上,每个SM中有一个专用的只读缓存(片上)用来缓存
主机内存
固定内存(锁页主机内存pinned host memory)
主机默认分配的主机内存是可分页的,固定内存是指页锁定page-locked的主机内存。
cudaMemcpy的过程如下:
当从可分页主机内存传输数据到设备内存时,CUDA驱动程序首先分配临时页锁定的内存(固定内存),将主机内存上的数据先复制到固定内存中,然后从固定内存传输到设备内存。而固定内存则不需要使用临时的锁页内存。
使用cudaMallocHost在主机上分配固定内存,必须使用cudaFreeHost释放所分配的内存,仍旧需要分配设备内存并使用cudaMemcpy,使用流程如下:
//分配可分页主机内存
h_a = (float *)malloc(bytes);
//分配页锁定主机内存
cudaMallocHost((float **)&h_a, bytes);
//分配设备内存
cudaMalloc((float **)&d_a, bytes);
//将主机内存复制到设备内存上
cudaMemcpy(d_a, h_a, bytes, cudaMemcpyHostToDevice);
…执行核函数
//将设备内存复制到主机内存上
cudaMemcpy(h_a, d_a, bytes, cudaMemcpyDeviceToHost);
//释放固定内存
cudaFreeHost(h_a);
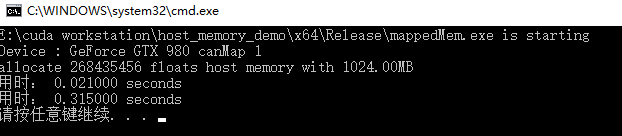
真的快很多!!!
零拷贝内存(映射锁页主机内存mapped host memory)
零拷贝内存是主机内存上分配的固定内存,并将主机内存映射到设备端内存地址,因此主机和设备都可以访问零拷贝内存。
由于受到PCIe总线的带宽等影响,核函数的性能将有较高的延迟;如果在主机和设备之间共享少量数据,零拷贝内存是一个不错的选择,可以简化编程,但是如果少量数据反复被使用,应该尽量考虑使用设备上的常量内存和共享内存。
没有(不需要)释放设备指针的操作,但是主机上的固定内存需要释放,使用流程如下:
//分配映射锁页内存,标志cudaHostAllocMapped指定分配映射锁页主机内存
cudaHostAlloc((void **)&h_A, nBytes, cudaHostAllocMapped);
//将锁页内存映射到设备地址空间,获得设备指针
cudaHostGetDevicePointer((void **)&d_A, (void *)h_A, 0);
…执行核函数
//释放锁页内存
cudaFreeHost(h_A);
慢
内存管理
内存分配与复制
cudaMalloc与malloc的区别(cudaFree vs free)
CUDA运行时负责分配与释放设备内存,并且在主机与设备之间传输数据。
将主机端的内存数据复制到设备端
// Copy input vectors from host memory to GPU buffers.
cudaStatus = cudaMemcpy(dev_a, a, size * sizeof(int), cudaMemcpyHostToDevice);
将设备端的内存数据复制到主机端
// Copy output vector from GPU buffer to host memory.
cudaStatus = cudaMemcpy(c, dev_c, size * sizeof(int), cudaMemcpyDeviceToHost);
下表列出了标准C以及对应CUDA C中的内存操作
| 标准C函数 |
CUDA C函数 |
| malloc |
cudaMalloc |
| memcpy |
cudaMemcpy |
| memset |
cudaMemset |
| free |
cudaFree |
|
|
cudaMemcpyToSymbol |
|
|
cudaMemcpyFromSymbol |
运行时API参考
cudaMalloc
此函数负责向设备分配一定字节的线性内存(全局内存),并返回所分配设备内存的设备指针,在已分配的全局内存中的值不会被清除(包含垃圾值),因此需要从主机上传输数据来填充,或者使用cudaMemset来初始化。
cudaMemcpy
cudaError_t cudaMemcpy(void *dst, const void *src, size_t count, enum cudaMemcpyKind kind)
此函数从源端的存储区复制一定数量的字节到目标端的存储区,复制方向由kind指定
该函数以同步方式在主机端执行,在完成操作前,主机端应用程序是阻塞的。
统一虚拟寻址(基于固定内存)
计算能力2.0开始,设备支持一种特殊的寻址方式--统一虚拟寻址UVA。UVA意味着主机和设备内存可以共享同一个虚拟地址空间;在UVA之前,需要明确管理哪些指针指向主机内存和哪些指针指向设备内存,但是UVA之后,指针指向哪里对于应用程序而言是透明的。
通过UVA,有cudaHostAlloc分配的的固定内存具有相同的主机和设备指针(内存地址一样),因此可以将返回的指针直接传递给核函数。
查询是否支持UVA
1、cuda运行时API(#include "cuda_runtime.h")
cudaDeviceProp deviceProp;
cudaGetDeviceProperties(&deviceProp, dev);
printf("unifiedAddressing status: %d\n",deviceProp.unifiedAddressing);
如果设备与主机共享一个统一的地址空间,则为1;否则为0;
2、Cuda驱动程序API(#include "cuda.h"并将库设置为链接器的输入)
统一内存寻址
在核函数中可以这两种类型的内存:
1)有系统控制的托管内存
2)由应用程序明确分配的和调用的未托管内存
所有在设备内存上有效的CUDA操作也同样适用于托管内存,但是托管内存能够被主机引用和访问。