一 序:
在整理InnoDB存储引擎的索引的时候,发现B+树是离不开页面page的。所以先整理InnoDB的数据存储结构。
关键词:Pages, Extents, Segments, and Tablespaces
如何存储表
MySQL 使用 InnoDB 存储表时,会将表的定义和数据索引等信息分开存储,其中前者存储在 .frm 文件中,后者存储在 .ibd 文件中,这一节就会对这两种不同的文件分别进行介绍。
.frm
无论在 MySQL 中选择了哪个存储引擎,所有的 MySQL 表都会在硬盘上创建一个 .frm 文件用来描述表的格式或者说定义; .frm 文件的格式在不同的平台上都是相同的。
.ibd 文件
InnoDB 中用于存储数据的文件总共有两个部分,一是系统表空间文件,包括 ibdata1、 ibdata2 等文件,其中存储了 InnoDB 系统信息和用户数据库表数据和索引,是所有表公用的。
当打开 innodb_file_per_table 选项时, .ibd 文件就是每一个表独有的表空间,文件存储了当前表的数据和相关的索引数据。
表空间
innodb存储引擎在存储设计上模仿了Oracle的存储结构,其数据是按照表空间进行管理的。新建一个数据库时,innodb存储引擎会初始化一个名为ibdata1 的表空间文件,默认情况下,这个文件会存储所有表的数据,以及我们所熟知但看不到的系统表sys_tables、sys_columns、sys_indexes 、sys_fields等。此外,还会存储用来保证数据完整性的回滚段数据,当然这部分数据在新版本的MySQL中,已经可以通过参数来设置回滚段的存储位置了;
看下官网的介绍:
A data file that can hold data for one or more InnoDB tables and associated indexes.
The system tablespace contains the InnoDB data dictionary, and prior to MySQL 5.6 holds all other InnoDB tables by default.
The innodb_file_per_table option, enabled by default in MySQL 5.6 and higher, allows tables to be created in their own tablespaces. File-per-table tablespaces support features such as efficient storage of off-page columns, table compression, and transportable tablespaces. See Section 14.7.4, “InnoDB File-Per-Table Tablespaces” for details.innodb存储引擎的设计很灵活,可以通过参数innodb_file_per_table来设置,使得每一个表都对应一个自己的独立表空间文件,而不是存储到公共的ibdata1文件中。独立的表空间文件之存储对应表的B+树数据、索引和插入缓冲等信息,其余信息还是存储在默认表空间中。
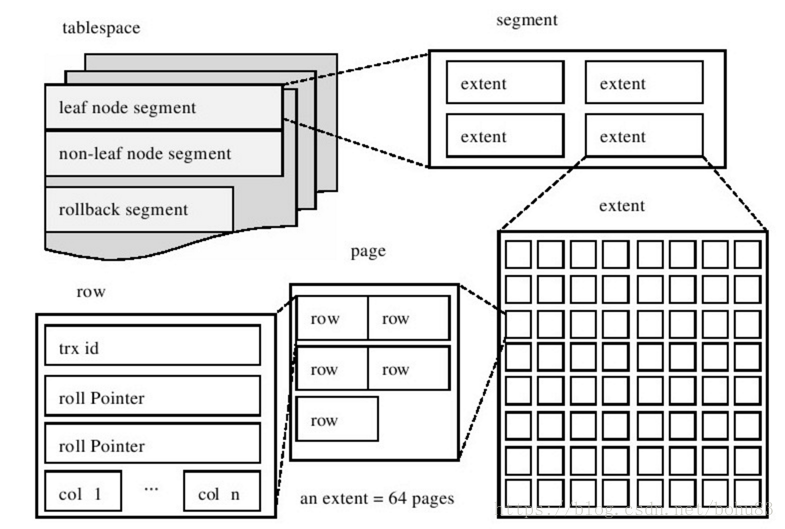
这个文件所存储的内容主要就是B+树(索引),一个表可以有多个索引,也就是在一个文件中,可以存储多个索引,而如果一个表没有索引的话,用来存储数据的被称为聚簇索引,也就是说这也是一个索引。最终的结论是,ibd文件存储的就是一个表的所有索引数据。 索引文件有段(segment),簇(extends)(有的文章翻译为区),页面(page)组成。
关于行记录格式,单独整理一篇。
二 段(segment)
段是表空间文件中的主要组织结构,它是一个逻辑概念,用来管理物理文件,是构成索引、表、回滚段的基本元素。
上图中显示了表空间是由各个段组成的,常见的段有数据段、索引段、回滚段等。InnoDB存储引擎表是索引组织的(index organized),因此数据即索引,索引即数据。那么数据段即为B+树的页节点(上图的leaf node segment),索引段即为B+树的非索引节点(上图的non-leaf node segment)。
创建一个索引(B+树)时会同时创建两个段,分别是内节点段和叶子段,内节点段用来管理(存储)B+树非叶子(页面)的数据,叶子段用来管理(存储)B+树叶子节点的数据;也就是说,在索引数据量一直增长的过程中,所有新的存储空间的申请,都是从“段”这个概念中申请的。
为了介绍索引为目的,所以不展开介绍回滚段等内容。
三 区/簇(extents)
段是个逻辑概念,innodb引入了簇的概念,在代码中被称为extent;
簇是由64个连续的页组成的,每个页大小为16KB,即每个簇的大小为1MB。簇是构成段的基本元素,一个段由若干个簇构成。一个簇是物理上连续分配的一个段空间,每一个段至少会有一个簇,在创建一个段时会创建一个默认的簇。如果存储数据时,一个簇已经不足以放下更多的数据,此时需要从这个段中分配一个新的簇来存放新的数据。一个段所管理的空间大小是无限的,可以一直扩展下去,但是扩展的最小单位就是簇。
四 页(page)
InnoDB有页(page)的概念,可以理解为簇的细化。页是InnoDB磁盘管理的最小单位。
常见的页类型有:
数据页(B-tree Node)。
Undo页(Undo Log Page)。
系统页(System Page)。
事务数据页(Transaction system Page)。
插入缓冲位图页(Insert Buffer Bitmap)。
插入缓冲空闲列表页(Insert Buffer Free List)。
未压缩的二进制大对象页(Uncompressed BLOB Page)。
压缩的二进制大对象页(Compressed BLOB Page)。
在逻辑上(页面号都是从小到大连续的)及物理上都是连续的。在向表中插入数据时,如果一个页面已经被写完,系统会从当前簇中分配一个新的空闲页面处理使用,如果当前簇中的64个页面都被分配完,系统会从当前页面所在段中分配一个新的簇,然后再从这个簇中分配一个新的页面来使用;
看下官网的介绍:
Pages, Extents, Segments, and Tablespaces
Each tablespace consists of database pages. Every tablespace in a MySQL instance has the same page size. By default, all tablespaces have a page size of 16KB; you can reduce the page size to 8KB or 4KB by specifying the innodb_page_size option when you create the MySQL instance. You can also increase the page size to 32KB or 64KB. For more information, refer to the innodb_page_sizedocumentation.
The pages are grouped into extents of size 1MB for pages up to 16KB in size (64 consecutive 16KB pages, or 128 8KB pages, or 256 4KB pages). For a page size of 32KB, extent size is 2MB. For page size of 64KB, extent size is 4MB. The “files” inside a tablespace are called segments in InnoDB. (These segments are different from the rollback segment, which actually contains many tablespace segments.)
When a segment grows inside the tablespace, InnoDB allocates the first 32 pages to it one at a time. After that, InnoDB starts to allocate whole extents to the segment. InnoDB can add up to 4 extents at a time to a large segment to ensure good sequentiality of data.
Two segments are allocated for each index in InnoDB. One is for nonleaf nodes of the B-tree, the other is for the leaf nodes. Keeping the leaf nodes contiguous on disk enables better sequential I/O operations, because these leaf nodes contain the actual table data.
Some pages in the tablespace contain bitmaps of other pages, and therefore a few extents in an InnoDB tablespace cannot be allocated to segments as a whole, but only as individual pages.
五 组织结构
这里在《MySQL运维内参》说的不是特别细: 一个表空间可以有多个文件,每个文件都有各自的编号,创建一个表空间时,至少有一个文件,这个文件被称为“0号文件”。一个文件是被切割为等长“默认16KB”的块,这个块通常被称为页面,那么在“0号文件”的第一个页面(page_no为0)中,存储了这个表空间中所有段簇也管理的入口,那么在这个页面存储的数据就是16KB,但通常会有页面头信息会占用一些空间,真正的管理信息数据是从页面偏移为fil_page_data(38)的位置开始的,这个位置存储了表空间的描述信息;
淘宝的mysql给出了更详细:先看这个图,有个大概概念,再往下看。

5.1 FSP_HDR PAGE
数据文件的第一个Page类型为FIL_PAGE_TYPE_FSP_HDR,在创建一个新的表空间时进行初始化(fsp_header_init),该page同时用于跟踪随后的256个Extent(约256MB文件大小)的空间管理,所以每隔256MB就要创建一个类似的数据页,类型为FIL_PAGE_TYPE_XDES ,XDES Page除了文件头部外,其他都和FSP_HDR页具有相同的数据结构,可以称之为Extent描述页,每个Extent占用40个字节,一个XDES Page最多描述256个Extent。
FSP_HDR页的头部使用FSP_HEADER_SIZE个字节来记录文件的相关信息,具体的包括:
| Macro | bytes | Desc |
|---|---|---|
| FSP_SPACE_ID | 4 | 该文件对应的space id |
| FSP_NOT_USED | 4 | 如其名,保留字节,当前未使用 |
| FSP_SIZE | 4 | 当前表空间总的PAGE个数,扩展文件时需要更新该值(fsp_try_extend_data_file_with_pages) |
| FSP_FREE_LIMIT | 4 | 当前尚未初始化的最小Page No。从该Page往后的都尚未加入到表空间的FREE LIST上。 |
| FSP_SPACE_FLAGS | 4 | 当前表空间的FLAG信息,见下文 |
| FSP_FRAG_N_USED | 4 | FSP_FREE_FRAG链表上已被使用的Page数,用于快速计算该链表上可用空闲Page数 |
| FSP_FREE | 16 | 当一个Extent中所有page都未被使用时,放到该链表上,可以用于随后的分配 |
| FSP_FREE_FRAG | 16 | FREE_FRAG链表的Base Node,通常这样的Extent中的Page可能归属于不同的segment,用于segment frag array page的分配(见下文) |
| FSP_FULL_FRAG | 16 | Extent中所有的page都被使用掉时,会放到该链表上,当有Page从该Extent释放时,则移回FREE_FRAG链表 |
| FSP_SEG_ID | 8 | 当前文件中最大Segment ID + 1,用于段分配时的seg id计数器 |
| FSP_SEG_INODES_FULL | 16 | 已被完全用满的Inode Page链表 |
| FSP_SEG_INODES_FREE | 16 | 至少存在一个空闲Inode Entry的Inode Page被放到该链表上 |
簇或者分区(extent)是段的组成元素,在文件头使用FLAG描述了创建表信息,除此之外其他部分的数据结构和XDES PAGE都是相同的,使用连续数组的方式,每个XDES PAGE最多存储256个XDES Entry,每个Entry占用40个字节,描述64个Page(即一个Extent)。格式如下:
| Macro | bytes | Desc |
|---|---|---|
| XDES_ID | 8 | 如果该Extent归属某个segment的话,则记录其ID |
| XDES_FLST_NODE | 12(FLST_NODE_SIZE) | 维持Extent链表的双向指针节点 |
| XDES_STATE | 4 | 该Extent的状态信息,包括:XDES_FREE,XDES_FREE_FRAG,XDES_FULL_FRAG,XDES_FSEG,详解见下文 |
| XDES_BITMAP | 16 | 总共16*8= 128个bit,用2个bit表示Extent中的一个page,一个bit表示该page是否是空闲的(XDES_FREE_BIT),另一个保留位,尚未使用(XDES_CLEAN_BIT) |
XDES_STATE表示该Extent的四种不同状态:
| Macro | Desc |
|---|---|
| XDES_FREE(1) | 存在于FREE链表上 |
| XDES_FREE_FRAG(2) | 存在于FREE_FRAG链表上 |
| XDES_FULL_FRAG(3) | 存在于FULL_FRAG链表上 |
| XDES_FSEG(4) | 该Extent归属于ID为XDES_ID记录的值的SEGMENT。 |
通过XDES_STATE信息,我们只需要一个FLIST_NODE节点就可以维护每个Extent的信息,是处于全局表空间的链表上,还是某个btree segment的链表上。
IBUF BITMAP PAGE 也就是page类型为FIL_PAGE_IBUF_BITMAP不展开,待单独整理。再看段的。
5.2 INODE PAGE
数据文件的第3个page的类型为FIL_PAGE_INODE,用于管理数据文件中的segement,每个索引占用2个segment,分别用于管理叶子节点和非叶子节点。每个inode页可以存储FSP_SEG_INODES_PER_PAGE(默认为85)个记录。
| Macro | bits | Desc |
|---|---|---|
| FSEG_INODE_PAGE_NODE | 12 | INODE页的链表节点,记录前后Inode Page的位置,BaseNode记录在头Page的FSP_SEG_INODES_FULL或者FSP_SEG_INODES_FREE字段。 |
| Inode Entry 0 | 192 | Inode记录 |
| Inode Entry 1 | ||
| …… | ||
| Inode Entry 84 |
每个Inode Entry的结构如下表所示:
| Macro | bits | Desc |
|---|---|---|
| FSEG_ID | 8 | 该Inode归属的Segment ID,若值为0表示该slot未被使用 |
| FSEG_NOT_FULL_N_USED | 8 | FSEG_NOT_FULL链表上被使用的Page数量 |
| FSEG_FREE | 16 | 完全没有被使用并分配给该Segment的Extent链表 |
| FSEG_NOT_FULL | 16 | 至少有一个page分配给当前Segment的Extent链表,全部用完时,转移到FSEG_FULL上,全部释放时,则归还给当前表空间FSP_FREE链表 |
| FSEG_FULL | 16 | 分配给当前segment且Page完全使用完的Extent链表 |
| FSEG_MAGIC_N | 4 | Magic Number |
| FSEG_FRAG_ARR 0 | 4 | 属于该Segment的独立Page。总是先从全局分配独立的Page,当填满32个数组项时,就在每次分配时都分配一个完整的Extent,并在XDES PAGE中将其Segment ID设置为当前值 |
| …… | …… | |
| FSEG_FRAG_ARR 31 | 4 | 总共存储32个记录项 |
看到这里,上面的图应该是理解了,当然书上还是给了一个简化的图:

5.3 文件维护
从上文我们可以看到,InnoDB通过Inode Entry来管理每个Segment占用的数据页,每个segment可以看做一个文件页维护单元。Inode Entry所在的inode page有可能存放满,因此又通过头Page维护了Inode Page链表。
在ibd的第一个Page中还维护了表空间内Extent的FREE、FREE_FRAG、FULL_FRAG三个Extent链表;而每个Inode Entry也维护了对应的FREE、NOT_FULL、FULL三个Extent链表。这些链表之间存在着转换关系,以高效的利用数据文件空间。注意区别:表空间中的链表管理的是整个表空间中所有的簇,包括满簇、半满簇及空闲簇,而段的iNode信息中管理的是属于自己段中的满簇、半满簇及空闲簇。
当创建一个新的索引时,实际上构建一个新的btree(btr_create),先为非叶子节点Segment分配一个inode entry,再创建root page,并将该segment的位置记录到root page中,然后再分配leaf segment的Inode entry,并记录到root page中。当删除某个索引后,该索引占用的空间需要能被重新利用起来。
创建一个segment:
函数入口:fseg_create_general,后面贴一下代码,主要是书上的解释。
1.根据空间id得到表空间头信息。
2. 从得到的表空间头信息分配Inode:具体实现为读取文件头Page并加锁(fsp_get_space_header),然后开始为其分配Inode Entry(fsp_alloc_seg_inode)。
为了管理Inode Page,在文件头存储了两个Inode Page链表,一个链接已经用满的inode page,一个链接尚未用满的inode page。如果当前Inode Page的空间使用完了,就需要再分配一个inode page,并加入到FSP_SEG_INODES_FREE链表上(fsp_alloc_seg_inode_page)。对于独立表空间,通常一个inode page就足够了。
下面看具体查找inode Page过程:首先判断FSP_SEG_INODES_FREE链表是否还有空闲页面,如果有,则从页面的数据存储位置开始扫描,没找一个Inode,先判断是否空闲(空闲表示其不归属任何segment,即FSEG_ID置为0)。找到则返回。找到这个且这个Inode为这个页最后一个Inode.则该inode page中的记录用满了,就从FSP_SEG_INODES_FREE链表上转移到FSP_SEG_INODES_FULL链表。如果FSP_SEG_INODES_FREE没有空闲的Inode页面,则重新分配一个inode页面,分配后把所有描述符里面的FSEG_ID置为0,重复上面过程。
3.给新分配的Inode设置SEG_ID. 这个ID号要从表空间头信息的FSP_SEG_ID作为当前segment的seg id写入到inode entry中。同时更新FSP_SEG_ID的值为ID+1,作为下一个段的ID号。
4.在完成inode entry的提取后,初始化这个Inode信息。把FSEG_NOT_FULL_N_USED置为0,初始化FSEG_FREE、FSEG_NOT_FULL,FSEG_FULL。
5. 从这个段分配出一个页面。(这块逻辑不太懂)
6.分配好页面后,通过缓存找到段的首页面(页面号为page+index)。就将该inode entry所在inode page的位置及页内偏移量存储到段首页,10个字节的inode信息包括:
| Macro | bytes | Desc |
|---|---|---|
| FSEG_HDR_SPACE | 4 | 描述该segment的inode page所在的space id (目前的实现来看,感觉有点多余…) |
| FSEG_HDR_PAGE_NO | 4 | 描述该segment的inode page的page no |
| FSEG_HDR_OFFSET | 2 | inode page内的页内偏移量 |
至此段就分配完成了,以后如果需要在这个段中分配空间,只需要找到其首页,然后根据对应的Inode分配空间。
Creates a new segment.
@return the block where the segment header is placed, x-latched, NULL
if could not create segment because of lack of space */
UNIV_INTERN
buf_block_t*
fseg_create_general(
/*================*/
ulint space, /*!< in: space id */
ulint page, /*!< in: page where the segment header is placed: if
this is != 0, the page must belong to another segment,
if this is 0, a new page will be allocated and it
will belong to the created segment */
ulint byte_offset, /*!< in: byte offset of the created segment header
on the page */
ibool has_done_reservation, /*!< in: TRUE if the caller has already
done the reservation for the pages with
fsp_reserve_free_extents (at least 2 extents: one for
the inode and the other for the segment) then there is
no need to do the check for this individual
operation */
mtr_t* mtr) /*!< in: mtr */
{
ulint flags;
ulint zip_size;
fsp_header_t* space_header;
fseg_inode_t* inode; //typedef byte fseg_inode_t;
ib_id_t seg_id;
buf_block_t* block = 0; /* remove warning */
fseg_header_t* header = 0; /* remove warning */
rw_lock_t* latch;
ibool success;
ulint n_reserved;
ulint i;
ut_ad(mtr);
ut_ad(byte_offset + FSEG_HEADER_SIZE
<= UNIV_PAGE_SIZE - FIL_PAGE_DATA_END);
latch = fil_space_get_latch(space, &flags);
zip_size = dict_table_flags_to_zip_size(flags);
if (page != 0) {
block = buf_page_get(space, zip_size, page, RW_X_LATCH, mtr);
header = byte_offset + buf_block_get_frame(block);
}
ut_ad(!mutex_own(&kernel_mutex)
|| mtr_memo_contains(mtr, latch, MTR_MEMO_X_LOCK));
mtr_x_lock(latch, mtr);
if (rw_lock_get_x_lock_count(latch) == 1) {
/* This thread did not own the latch before this call: free
excess pages from the insert buffer free list */
if (space == IBUF_SPACE_ID) {
ibuf_free_excess_pages();
}
}
if (!has_done_reservation) {
success = fsp_reserve_free_extents(&n_reserved, space, 2,
FSP_NORMAL, mtr);
if (!success) {
return(NULL);
}
}
space_header = fsp_get_space_header(space, zip_size, mtr);//详见
inode = fsp_alloc_seg_inode(space_header, mtr);//申请inode entry 详见 if (inode == NULL) {
goto funct_exit;
}
/* Read the next segment id from space header and increment the
value in space header */
seg_id = mach_read_from_8(space_header + FSP_SEG_ID);//设置下一下seg id
mlog_write_ull(space_header + FSP_SEG_ID, seg_id + 1, mtr);
/**
*#define FSEG_ID 0
*#define FSEG_NOT_FULL_N_USED 8
*#define FSEG_FREE 12
*#define FSEG_NOT_FULL (12 + FLST_BASE_NODE_SIZE)
*#define FLST_BASE_NODE_SIZE (4 + 2 * FIL_ADDR_SIZE)
*#define FIL_ADDR_SIZE 6
*
*#define FSEG_FULL (12 + 2 * FLST_BASE_NODE_SIZE)
*
*/
mlog_write_ull(inode + FSEG_ID, seg_id, mtr);
mlog_write_ulint(inode + FSEG_NOT_FULL_N_USED, 0, MLOG_4BYTES, mtr);
flst_init(inode + FSEG_FREE, mtr); //初始化inode中的seg list 详见
flst_init(inode + FSEG_NOT_FULL, mtr);
flst_init(inode + FSEG_FULL, mtr);
mlog_write_ulint(inode + FSEG_MAGIC_N, FSEG_MAGIC_N_VALUE,
MLOG_4BYTES, mtr);
//#define FSEG_FRAG_ARR_N_SLOTS (FSP_EXTENT_SIZE / 2) 64/2=32 for (i = 0; i < FSEG_FRAG_ARR_N_SLOTS; i++) {
fseg_set_nth_frag_page_no(inode, i, FIL_NULL, mtr); //设置frag 碎片 详见
}
if (page == 0) {
block = fseg_alloc_free_page_low(space, zip_size,
inode, 0, FSP_UP, mtr, mtr);
if (block == NULL) {
fsp_free_seg_inode(space, zip_size, inode, mtr);
goto funct_exit;
}
ut_ad(rw_lock_get_x_lock_count(&block->lock) == 1);
header = byte_offset + buf_block_get_frame(block);
mlog_write_ulint(buf_block_get_frame(block) + FIL_PAGE_TYPE,
FIL_PAGE_TYPE_SYS, MLOG_2BYTES, mtr);
}
//设置fset_header信息
mlog_write_ulint(header + FSEG_HDR_OFFSET,page_offset(inode), MLOG_2BYTES, mtr);
mlog_write_ulint(header + FSEG_HDR_PAGE_NO,page_get_page_no(page_align(inode)),MLOG_4BYTES, mtr);
mlog_write_ulint(header + FSEG_HDR_SPACE, space, MLOG_4BYTES, mtr);
funct_exit:
if (!has_done_reservation) {
fil_space_release_free_extents(space, n_reserved);
}
return(block);
}分配数据页函数 fsp_alloc_free_page
表空间Extent的分配函数fsp_alloc_free_extent ,不在此展开。
对应的还有释放Segment 当我们删除索引或者表时,需要删除btree(btr_free_if_exists),先删除除了root节点外的其他部分(btr_free_but_not_root),再删除root节点(btr_free_root)
由于数据操作都需要记录redo,为了避免产生非常大的redo log,leaf segment通过反复调用函数fseg_free_step来释放其占用的数据页。
六 创建B+索引
上面我们已经大概了解了innodb的文件管理方式,核心目的是为了管理好B+索引。
ibd文件中真正构建起用户数据的结构是BTREE,在你创建一个表时,已经基于显式或隐式定义的主键构建了一个btree,其叶子节点上记录了行的全部列数据(加上事务id列及回滚段指针列);如果你在表上创建了二级索引,其叶子节点存储了键值加上聚集索引键值。所以书上贴一段创建B+索引的代码。网上找了5.6.15版本的。这个函数就是创建一个B+树,只是概念上的,还没有真正的数据写入。
相关知识点:B+树,索引,段,区/簇(extent),页 已经串起来了。下一篇可以继续整理索引了。
Creates the root node for a new index tree.
@return page number of the created root, FIL_NULL if did not succeed */
UNIV_INTERN
ulint
btr_create(
/*=======*/
ulint type, /*!< in: type of the index */
ulint space, /*!< in: space where created */
ulint zip_size,/*!< in: compressed page size in bytes
or 0 for uncompressed pages */
index_id_t index_id,/*!< in: index id */
dict_index_t* index, /*!< in: index */
mtr_t* mtr) /*!< in: mini-transaction handle */
{
ulint page_no;
buf_block_t* block;
buf_frame_t* frame;
page_t* page;
page_zip_des_t* page_zip;
/* Create the two new segments (one, in the case of an ibuf tree) for
the index tree; the segment headers are put on the allocated root page
(for an ibuf tree, not in the root, but on a separate ibuf header
page) */
if (type & DICT_IBUF) {
/* Allocate first the ibuf header page */
buf_block_t* ibuf_hdr_block = fseg_create(
space, 0,
IBUF_HEADER + IBUF_TREE_SEG_HEADER, mtr);
buf_block_dbg_add_level(
ibuf_hdr_block, SYNC_IBUF_TREE_NODE_NEW);
ut_ad(buf_block_get_page_no(ibuf_hdr_block)
== IBUF_HEADER_PAGE_NO);
/* Allocate then the next page to the segment: it will be the
tree root page */
block = fseg_alloc_free_page(
buf_block_get_frame(ibuf_hdr_block)
+ IBUF_HEADER + IBUF_TREE_SEG_HEADER,
IBUF_TREE_ROOT_PAGE_NO,
FSP_UP, mtr);
ut_ad(buf_block_get_page_no(block) == IBUF_TREE_ROOT_PAGE_NO);
} else {
#ifdef UNIV_BLOB_DEBUG
if ((type & DICT_CLUSTERED) && !index->blobs) {
mutex_create(PFS_NOT_INSTRUMENTED,
&index->blobs_mutex, SYNC_ANY_LATCH);
index->blobs = rbt_create(sizeof(btr_blob_dbg_t),
btr_blob_dbg_cmp);
}
#endif /* UNIV_BLOB_DEBUG */
block = fseg_create(space, 0,
PAGE_HEADER + PAGE_BTR_SEG_TOP, mtr);
}
if (block == NULL) {
return(FIL_NULL);
}
page_no = buf_block_get_page_no(block);
frame = buf_block_get_frame(block);
if (type & DICT_IBUF) {
/* It is an insert buffer tree: initialize the free list */
buf_block_dbg_add_level(block, SYNC_IBUF_TREE_NODE_NEW);
ut_ad(page_no == IBUF_TREE_ROOT_PAGE_NO);
flst_init(frame + PAGE_HEADER + PAGE_BTR_IBUF_FREE_LIST, mtr);
} else {
/* It is a non-ibuf tree: create a file segment for leaf
pages */
buf_block_dbg_add_level(block, SYNC_TREE_NODE_NEW);
if (!fseg_create(space, page_no,
PAGE_HEADER + PAGE_BTR_SEG_LEAF, mtr)) {
/* Not enough space for new segment, free root
segment before return. */
btr_free_root(space, zip_size, page_no, mtr);
return(FIL_NULL);
}
/* The fseg create acquires a second latch on the page,
therefore we must declare it: */
buf_block_dbg_add_level(block, SYNC_TREE_NODE_NEW);
}
/* Create a new index page on the allocated segment page */
page_zip = buf_block_get_page_zip(block);
if (page_zip) {
page = page_create_zip(block, index, 0, 0, mtr);
} else {
page = page_create(block, mtr,
dict_table_is_comp(index->table));
/* Set the level of the new index page */
btr_page_set_level(page, NULL, 0, mtr);
}
block->check_index_page_at_flush = TRUE;
/* Set the index id of the page */
btr_page_set_index_id(page, page_zip, index_id, mtr);
/* Set the next node and previous node fields */
btr_page_set_next(page, page_zip, FIL_NULL, mtr);
btr_page_set_prev(page, page_zip, FIL_NULL, mtr);
/* We reset the free bits for the page to allow creation of several
trees in the same mtr, otherwise the latch on a bitmap page would
prevent it because of the latching order */
if (!(type & DICT_CLUSTERED)) {
ibuf_reset_free_bits(block);
}
/* In the following assertion we test that two records of maximum
allowed size fit on the root page: this fact is needed to ensure
correctness of split algorithms */
ut_ad(page_get_max_insert_size(page, 2) > 2 * BTR_PAGE_MAX_REC_SIZE);
return(page_no);
}
************************************************
真是博大精深,看了书不太懂,C++源码的也是头大。当然对于开发来说,多了解知识更有助于高效率使用。
参考:
http://mysql.taobao.org/monthly/2016/02/01/
《MYSQL运维内参》
https://dev.mysql.com/doc/refman/5.7/en/innodb-file-space.html