一 序
上一篇我们整理了INNODB的索引的原理,再加上之前介绍的段、簇(extent),页管理,应该是能串起来了。还有单个的页面管理没有介绍。本文基于《MYSQL运维内参》第八章部分整理。
背景知识:
数据库采用数据页的形式组织数据。MySQL默认的非压缩数据页为16KB。在ibd中间中,0-16KB偏移量即为0号数据页,16KB-32KB的为1号数据页,依次类推。数据页的头尾除了一些元信息外,还有Checksum校验值,这些校验值在写入磁盘前计算得到,当从磁盘中读取时,重新计算校验值并与数据页中存储的对比,如果发现不同,则会导致MySQL crash。遇到这种情况,往往需要从备份集中恢复数据,如果备份不可用,只能使用innodb_force_recovery强行启动,然后尽可能多的导出数据。
InnoDB的数据页有很多种,比如,索引页,Undo页,Inode页,系统页,BloB页等,格式也是各不相同。本文主要介绍最常见的索引页。
/** File page types (values of FIL_PAGE_TYPE) @{ */
#define FIL_PAGE_INDEX 17855 /*!< B-tree node */
#define FIL_PAGE_RTREE 17854 /*!< B-tree node */
#define FIL_PAGE_UNDO_LOG 2 /*!< Undo log page */
#define FIL_PAGE_INODE 3 /*!< Index node */
#define FIL_PAGE_IBUF_FREE_LIST 4 /*!< Insert buffer free list */
/* File page types introduced in MySQL/InnoDB 5.1.7 */
#define FIL_PAGE_TYPE_ALLOCATED 0 /*!< Freshly allocated page */
#define FIL_PAGE_IBUF_BITMAP 5 /*!< Insert buffer bitmap */
#define FIL_PAGE_TYPE_SYS 6 /*!< System page */
#define FIL_PAGE_TYPE_TRX_SYS 7 /*!< Transaction system data */
#define FIL_PAGE_TYPE_FSP_HDR 8 /*!< File space header */
#define FIL_PAGE_TYPE_XDES 9 /*!< Extent descriptor page */
#define FIL_PAGE_TYPE_BLOB 10 /*!< Uncompressed BLOB page */
#define FIL_PAGE_TYPE_ZBLOB 11 /*!< First compressed BLOB page */
#define FIL_PAGE_TYPE_ZBLOB2 12 /*!< Subsequent compressed BLOB page */
#define FIL_PAGE_TYPE_UNKNOWN 13 /*!< In old tablespaces, garbage
in FIL_PAGE_TYPE is replaced with this
value when flushing pages. */
#define FIL_PAGE_COMPRESSED 14 /*!< Compressed page */
#define FIL_PAGE_ENCRYPTED 15 /*!< Encrypted page */
#define FIL_PAGE_COMPRESSED_AND_ENCRYPTED 16
/*!< Compressed and Encrypted page */
#define FIL_PAGE_ENCRYPTED_RTREE 17 /*!< Encrypted R-tree page */二 文件管理头信息(Fil Header)
先看一个图
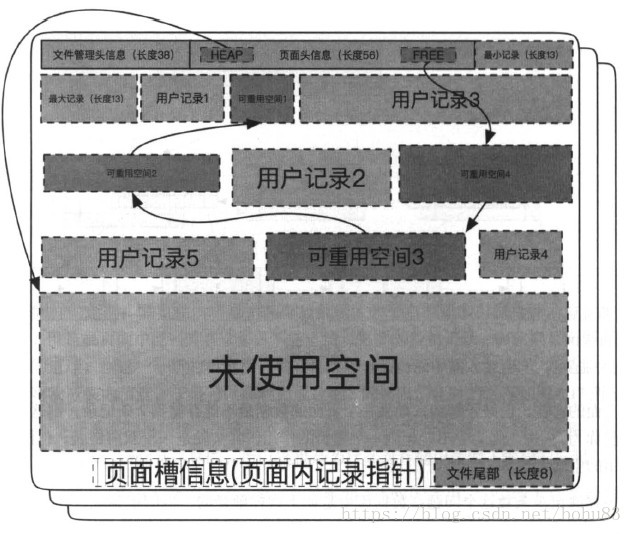
数据页包括七个部分,数据页文件管理头信息,数据页面头信息,最大最小记录,用户记录,空闲空间,数据目录(槽),数据页尾部。
先看文件管理头信息:
这个部分主要用来存储表空间相关的信息。主要在include/fil0fil.h这个文件中。
/** The byte offsets on a file page for various variables @{ */
#define FIL_PAGE_SPACE_OR_CHKSUM 0 /*!< in < MySQL-4.0.14 space id the
page belongs to (== 0) but in later
versions the 'new' checksum of the
page */
#define FIL_PAGE_OFFSET 4 /*!< page offset inside space */
#define FIL_PAGE_PREV 8 /*!< if there is a 'natural'
predecessor of the page, its
offset. Otherwise FIL_NULL.
This field is not set on BLOB
pages, which are stored as a
singly-linked list. See also
FIL_PAGE_NEXT. */
#define FIL_PAGE_NEXT 12 /*!< if there is a 'natural' successor
of the page, its offset.
Otherwise FIL_NULL.
B-tree index pages
(FIL_PAGE_TYPE contains FIL_PAGE_INDEX)
on the same PAGE_LEVEL are maintained
as a doubly linked list via
FIL_PAGE_PREV and FIL_PAGE_NEXT
in the collation order of the
smallest user record on each page. */
#define FIL_PAGE_LSN 16 /*!< lsn of the end of the newest
modification log record to the page */
#define FIL_PAGE_TYPE 24 /*!< file page type: FIL_PAGE_INDEX,...,
2 bytes.
The contents of this field can only
be trusted in the following case:
if the page is an uncompressed
B-tree index page, then it is
guaranteed that the value is
FIL_PAGE_INDEX.
The opposite does not hold.
In tablespaces created by
MySQL/InnoDB 5.1.7 or later, the
contents of this field is valid
for all uncompressed pages. */
#define FIL_PAGE_FILE_FLUSH_LSN 26 /*!< this is only defined for the
first page of the system tablespace:
the file has been flushed to disk
at least up to this LSN. For
FIL_PAGE_COMPRESSED pages, we store
the compressed page control information
in these 8 bytes. */
/** If page type is FIL_PAGE_COMPRESSED then the 8 bytes starting at
FIL_PAGE_FILE_FLUSH_LSN are broken down as follows: */
/** Control information version format (u8) */
static const ulint FIL_PAGE_VERSION = FIL_PAGE_FILE_FLUSH_LSN;
/** Compression algorithm (u8) */
static const ulint FIL_PAGE_ALGORITHM_V1 = FIL_PAGE_VERSION + 1;
/** Original page type (u16) */
static const ulint FIL_PAGE_ORIGINAL_TYPE_V1 = FIL_PAGE_ALGORITHM_V1 + 1;
/** Original data size in bytes (u16)*/
static const ulint FIL_PAGE_ORIGINAL_SIZE_V1 = FIL_PAGE_ORIGINAL_TYPE_V1 + 2;
/** Size after compression (u16) */
static const ulint FIL_PAGE_COMPRESS_SIZE_V1 = FIL_PAGE_ORIGINAL_SIZE_V1 + 2;
/** This overloads FIL_PAGE_FILE_FLUSH_LSN for RTREE Split Sequence Number */
#define FIL_RTREE_SPLIT_SEQ_NUM FIL_PAGE_FILE_FLUSH_LSN
/** starting from 4.1.x this contains the space id of the page */
#define FIL_PAGE_ARCH_LOG_NO_OR_SPACE_ID 34
#define FIL_PAGE_SPACE_ID FIL_PAGE_ARCH_LOG_NO_OR_SPACE_ID
#define FIL_PAGE_DATA 38U /*!< start of the data on the page */| Macro | bytes | Desc |
|---|---|---|
| FIL_PAGE_SPACE_OR_CHKSUM | 4 | 在MySQL4.0之前存储space id,之后的版本用于存储checksum |
| FIL_PAGE_OFFSET | 4 | 当前页的page no,每个表空间从0开始,即这个值乘以数据页的大小就可以得到数据页在文件中的起始偏移量。fio_io函数读取以及写入数据页的时候依赖这个规则。 |
| FIL_PAGE_PREV | 4 | 通常用于维护btree同一level的双向链表,指向链表的前一个page,没有的话则值为FIL_NULL |
| FIL_PAGE_NEXT | 4 | 和FIL_PAGE_PREV类似,记录链表的下一个Page的Page No |
| FIL_PAGE_LSN | 8 | 最近一次修改该page的LSN:这个字段非常重要,InnoDB redolog幂等的特性就依赖此字段。在奔溃恢复应用日志阶段,如果发现redolog的lsn小于等于这个值,就不需要再次应用redolog了。 |
| FIL_PAGE_TYPE | 2 | Page类型 |
| FIL_PAGE_FILE_FLUSH_LSN | 8 | 只用于系统表空间的第一个Page,记录在正常shutdown时安全checkpoint到的点,对于用户表空间,这个字段通常是空闲的,但在5.7里,FIL_PAGE_COMPRESSED类型的数据页则另有用途。 |
| FIL_PAGE_SPACE_ID | 4 | 存储page所在的space id |
三 页面头信息(page header)
要是按照书上说的,接下来就是页面头信息。其实在上面页面是找不到的。
搜了下,是在page0page.h里面。
#define PAGE_HEADER FSEG_PAGE_DATA /* index page header starts at this
offset */
/*-----------------------------*/
#define PAGE_N_DIR_SLOTS 0 /* number of slots in page directory */
#define PAGE_HEAP_TOP 2 /* pointer to record heap top */
#define PAGE_N_HEAP 4 /* number of records in the heap,
bit 15=flag: new-style compact page format */
#define PAGE_FREE 6 /* pointer to start of page free record list */
#define PAGE_GARBAGE 8 /* number of bytes in deleted records */
#define PAGE_LAST_INSERT 10 /* pointer to the last inserted record, or
NULL if this info has been reset by a delete,
for example */
#define PAGE_DIRECTION 12 /* last insert direction: PAGE_LEFT, ... */
#define PAGE_N_DIRECTION 14 /* number of consecutive inserts to the same
direction */
#define PAGE_N_RECS 16 /* number of user records on the page */
#define PAGE_MAX_TRX_ID 18 /* highest id of a trx which may have modified
a record on the page; trx_id_t; defined only
in secondary indexes and in the insert buffer
tree */
#define PAGE_HEADER_PRIV_END 26 /* end of private data structure of the page
header which are set in a page create */
/*----*/
#define PAGE_LEVEL 26 /* level of the node in an index tree; the
leaf level is the level 0. This field should
not be written to after page creation. */
#define PAGE_INDEX_ID 28 /* index id where the page belongs.
This field should not be written to after
page creation. */
#ifndef UNIV_INNOCHECKSUM
#define PAGE_BTR_SEG_LEAF 36 /* file segment header for the leaf pages in
a B-tree: defined only on the root page of a
B-tree, but not in the root of an ibuf tree */
#define PAGE_BTR_IBUF_FREE_LIST PAGE_BTR_SEG_LEAF
#define PAGE_BTR_IBUF_FREE_LIST_NODE PAGE_BTR_SEG_LEAF
/* in the place of PAGE_BTR_SEG_LEAF and _TOP
there is a free list base node if the page is
the root page of an ibuf tree, and at the same
place is the free list node if the page is in
a free list */
#define PAGE_BTR_SEG_TOP (36 + FSEG_HEADER_SIZE)
/* file segment header for the non-leaf pages
in a B-tree: defined only on the root page of
a B-tree, but not in the root of an ibuf
tree */
/*----*/我们先看第一行,PAGE_HEADER等于FSEG_PAGE_DATA,而FSEG_PAGE_DATA等于 FIL_PAGE_DATA,我们上面看过FIL_PAGE_DATA=38. 所以页面头信息就是从38行位置开始的。
| Macro | bytes | Desc |
|---|---|---|
| PAGE_N_DIR_SLOTS | 2 | Page directory中的slot个数 (见下文关于Page directory的描述)一个新建的空数据页,就有2个目录,分别指向最大记录和最小记录。 |
| PAGE_HEAP_TOP | 2 | 指向当前Page内已使用的空间的末尾便宜位置,即free space的开始位置(空闲空间的起始地址)。大于这个地址的且小于数据目录的空间都是未分配的,可以被后续使用。 |
| PAGE_N_HEAP | 2 | Page内所有记录个数,包含用户记录,系统记录以及标记删除的记录,在创建新的空页时候,默认被置为2,即最大和最小记录。此外当第一个bit(最高位)设置为1时,表示这个page内是以新格式Compact格式存储的 |
| PAGE_FREE | 2 | 指向标记删除的记录链表的第一个记录 |
| PAGE_GARBAGE | 2 | 被删除的记录链表上占用的总的字节数,属于可回收的垃圾碎片空间 |
| PAGE_LAST_INSERT | 2 | 指向最近一次插入的记录偏移量,主要用于优化顺序插入操作 |
| PAGE_DIRECTION | 2 | 用于指示当前记录的插入顺序以及是否正在进行顺序插入,每次插入时,PAGE_LAST_INSERT会和当前记录进行比较,以确认插入方向,据此进行插入优化 |
| PAGE_N_DIRECTION | 2 | 当前以相同方向的顺序插入记录个数 |
| PAGE_N_RECS | 2 | Page上有效的未被标记删除的用户记录个数 |
| PAGE_MAX_TRX_ID | 8 | 最近一次修改该page记录的事务ID,主要用于辅助判断二级索引记录的可见性。 |
| PAGE_LEVEL | 2 | 该Page所在的btree level,根节点的level最大,叶子节点的level为0 |
| PAGE_INDEX_ID | 8 | 该Page归属的索引ID |
Segment Info 随后20个字节描述段信息,仅在Btree的root Page中被设置,其他Page都是未使用的。
| Macro | bytes | Desc |
|---|---|---|
| PAGE_BTR_SEG_LEAF | 10(FSEG_HEADER_SIZE) | 叶子段leaf segment在(段头页)inode page中的位置 |
| PAGE_BTR_SEG_TOP | 10(FSEG_HEADER_SIZE) | 内节点段non-leaf segment在(段头页)inode page中的位置 |
之前介绍过一颗B+树有两个段,它们的首地址在存在每个B+根页面,就是这里。不过这个信息只有在根页面才有意义。
四 最大最小记录(Infimum and Supremum Records)
最大记录是这个数据页中逻辑上最大的记录,所有用户的记录都小于它。最小记录是数据页上最小的记录,所有用户记录都大于它。他们在数据页被创建的时候创建,而且不能被删除。是固定大小(13)固定位置的, 引入他们主要是方便页内操作。
我们知道索引的内节点中,每一层最左侧的页面的记录,就是起索引作用的。它指向孩子节点中的数据,在索引本身的排序属性下,比本节点的数据都小。INNODB中就是使用最小记录来承担这个责任。
还有一个作用就是在遍历数据的时候,通过槽slot从前往后找到数据的过程中,只要找到最小或者最大记录,就意味着已经到了本页面的边界,数据已经遍历完了。
具体实现根据行格式有所不同:这里存在两种存储方式,分别对应旧的InnoDB文件系统,及新的文件系统(compact page)
| Macro | bytes | Desc |
|---|---|---|
| REC_N_OLD_EXTRA_BYTES + 1 | 7 | 固定值,见infimum_supremum_redundant的注释 |
| PAGE_OLD_INFIMUM | 8 | “infimum\0” |
| REC_N_OLD_EXTRA_BYTES + 1 | 7 | 固定值,见infimum_supremum_redundant的注释 |
| PAGE_OLD_SUPREMUM | 9 | “supremum\0” |
Compact的系统记录存储方式为:
| Macro | bytes | Desc |
|---|---|---|
| REC_N_NEW_EXTRA_BYTES | 5 | 固定值,见infimum_supremum_compact的注释 |
| PAGE_NEW_INFIMUM | 8 | “infimum\0” |
| REC_N_NEW_EXTRA_BYTES | 5 | 固定值,见infimum_supremum_compact的注释 |
| PAGE_NEW_SUPREMUM | 8 | “supremum”,这里不带字符0 |
两种格式的主要差异在于不同行存储模式下,单个记录的描述信息不同。在实际创建page时,系统记录的值已经初始化好了,对于老的格式(REDUNDANT),对应代码里的infimum_supremum_redundant,对于新的格式(compact),对应infimum_supremum_compact。infimum记录的固定heap no为0,supremum记录的固定Heap no 为1。page上最小的用户记录前节点总是指向infimum,page上最大的记录后节点总是指向supremum记录。
具体参考索引页创建函数:page_create_low
用户记录(User Records)
系统记录之后就是用户记录了,一个没有任何插入数据的B+树页面来说,系统已经占用了38(文件头)+56(页头)+13(最大记录)+13(最小记录)=120字节。除了页尾的8字节页尾信息,剩下就是用户空间了。
用户所有插入的记录都存放在这里,默认情况下记录跟记录之间没有间隙,但是如果重用了已删除记录的空间,就会导致空间碎片。每个记录都有指向下一个记录的指针,但是没有指向上一个记录的指针。记录按照主键顺序排序。即,用户可以从数据页最小记录开始遍历,直到最大的记录,这包括了所有正常的记录和所有被delete-marked记录,但是不会访问到被删除的记录(PAGE_FREE)。
根据不同的类型,用户记录可以是非叶子节点的Node指针信息,也可以是只包含有效数据的叶子节点记录。而不同的行格式存储的行记录也不同,因为redundant属于渐渐被抛弃的格式,本文的讨论中我们默认使用Compact格式。在文件rem/rem0rec.cc的头部注释描述了记录的物理结构。
/* PHYSICAL RECORD (NEW STYLE)
===========================
The physical record, which is the data type of all the records
found in index pages of the database, has the following format
(lower addresses and more significant bits inside a byte are below
represented on a higher text line):
| length of the last non-null variable-length field of data:
if the maximum length is 255, one byte; otherwise,
0xxxxxxx (one byte, length=0..127), or 1exxxxxxxxxxxxxx (two bytes,
length=128..16383, extern storage flag) |
...
| length of first variable-length field of data |
| SQL-null flags (1 bit per nullable field), padded to full bytes |
| 4 bits used to delete mark a record, and mark a predefined
minimum record in alphabetical order |
| 4 bits giving the number of records owned by this record
(this term is explained in page0page.h) |
| 13 bits giving the order number of this record in the
heap of the index page |
| 3 bits record type: 000=conventional, 001=node pointer (inside B-tree),
010=infimum, 011=supremum, 1xx=reserved |
| two bytes giving a relative pointer to the next record in the page |
ORIGIN of the record
| first field of data |
...
| last field of data |
The origin of the record is the start address of the first field
of data. The offsets are given relative to the origin.
The offsets of the data fields are stored in an inverted
order because then the offset of the first fields are near the
origin, giving maybe a better processor cache hit rate in searches.
The offsets of the data fields are given as one-byte
(if there are less than 127 bytes of data in the record)
or two-byte unsigned integers. The most significant bit
is not part of the offset, instead it indicates the SQL-null
if the bit is set to 1. */| bytes | Desc |
|---|---|
| 变长列长度数组 | 如果列的最大长度为255字节,使用1byte;否则,0xxxxxxx (one byte, length=0..127), or 1exxxxxxxxxxxxxx (two bytes, length=128..16383, extern storage flag) |
| SQL-NULL flag | 标示值为NULL的列的bitmap,每个位标示一个列,bitmap的长度取决于索引上可为NULL的列的个数(dict_index_t::n_nullable),这两个数组的解析可以参阅函数rec_init_offsets |
| 下面5个字节(REC_N_NEW_EXTRA_BYTES)描述记录的额外信息 | …. |
| REC_NEW_INFO_BITS (4 bits) | 目前只使用了两个bit,一个用于表示该记录是否被标记删除(REC_INFO_DELETED_FLAG),另一个bit(REC_INFO_MIN_REC_FLAG)如果被设置,表示这个记录是当前level最左边的page的第一个用户记录 |
| REC_NEW_N_OWNED (4 bits) | 当该值为非0时,表示当前记录占用page directory里一个slot,并和前一个slot之间存在这么多个记录 |
| REC_NEW_HEAP_NO (13 bits) | 该记录的heap no |
| REC_NEW_STATUS (3 bits) | 记录的类型,包括四种:REC_STATUS_ORDINARY(叶子节点记录), REC_STATUS_NODE_PTR(非叶子节点记录),REC_STATUS_INFIMUM(infimum系统记录)以及REC_STATUS_SUPREMUM(supremum系统记录) |
| REC_NEXT (2bytes) | 指向按照键值排序的page内下一条记录数据起点,这里存储的是和当前记录的相对位置偏移量(函数rec_set_next_offs_new) |
在记录头信息之后的数据视具体情况有所不同:
- 对于聚集索引记录,数据包含了事务id,回滚段指针;
- 对于二级索引记录,数据包含了二级索引键值以及聚集索引键值。如果二级索引键和聚集索引有重合,则只保留一份重合的,例如pk (col1, col2),sec key(col2, col3),在二级索引记录中就只包含(col2, col3, col1);
- 对于非叶子节点页的记录,聚集索引上包含了其子节点的最小记录键值及对应的page no;二级索引上有所不同,除了二级索引键值外,还包含了聚集索引键值,再加上page no三部分构成。
空闲空间(Free Space)
从PAGE_HEAP_TOP开始,到最后一个数据目录,这之间的空间就是空闲空间,都被重置为0,插入数据的过程中,如果需要插入页面,系统就会从这个页面的heap申请所需要的空间。代码在page/page0page.cc
/************************************************************//**
Allocates a block of memory from the heap of an index page.
@return pointer to start of allocated buffer, or NULL if allocation fails */
byte*
page_mem_alloc_heap(
/*================*/
page_t* page, /*!< in/out: index page */
page_zip_des_t* page_zip,/*!< in/out: compressed page with enough
space available for inserting the record,
or NULL */
ulint need, /*!< in: total number of bytes needed */
ulint* heap_no)/*!< out: this contains the heap number
of the allocated record
if allocation succeeds */
{
byte* block;
ulint avl_space;
ut_ad(page && heap_no);
/*获取本页面剩余的空间,如果本页面空间有空余,则从本页面申请*/
avl_space = page_get_max_insert_size(page, 1);
if (avl_space >= need) {
block = page_header_get_ptr(page, PAGE_HEAP_TOP);
page_header_set_ptr(page, page_zip, PAGE_HEAP_TOP,
block + need);
*heap_no = page_dir_get_n_heap(page);
page_dir_set_n_heap(page, page_zip, 1 + *heap_no);
return(block);
}
return(NULL);
}这是空间的分配,如果记录被删除并purge了。则系统会把这个记录对应的空间,通过page free管理。每次在页面删除记录后,都会把新删除记录对应空间的NEXT指向原来PAGE_FREE指向的空间,然后再将PAGE_FREE指向新删除的记录空间的首地址,这样就通过链表管理起来了。因为在页面记录中,都会在记录首地址的前两个字节位置存储当前记录的下一个记录,用来将记录之间形成一个单项列表,那么自然被删除的空间也可以通过这个指针串联起来,最终通过PAGE_FREE管理起来。

好了,现在知道未经分配的空间是通过PAGE_HEAP_TOP管理,已经删除并PURGE的记录通过PAGE_FREE管理,那么已经分配的通过什么管理的呢?就是接下来的数据目录(Page Directory)。
数据目录(Page Directory)
上面是介绍了页面的组成结构,那么页面内部是如何组织记录的呢?INNODB引入了slot槽的概念,槽的作用就是页面内搜索数据的,可以理解为在页内构建的一个很小的索引(sparse index)来辅助二分查找。为了管理记录,把多条数据对应一个槽,或者说一个槽own多条记录。到底是几条呢?书上没有给出很细的解释,每个槽占用两个字节(PAGE_DIR_SLOT_SIZE),存储对应记录的页内偏移量。在槽指向的记录中,会有字段记录own记录的数量。由此可见,槽own的记录不能太多,因为太多的话,即意味着槽太过稀疏,不能很好的提高查询效率,但同时也不能own太少,这会导致槽数量变多,占用过多的空间。在InnoDB的实现中,槽own的记录数量在(PAGE_DIR_SLOT_MIN_N_OWNED-PAGE_DIR_SLOT_MAX_N_OWNED)4-8之间,包括4和8,平均是6个记录。如果超过这个数量,就需要重新均衡槽的数量。槽的增加和删除可能需要进行内存拷贝,但是由于槽占用的总体空间很小,开销可以忽略不计。
Page Directory的slot分配是从Page末尾(倒数第八个字节开始)开始逆序分配的。最高的槽位代表页面内索引顺序最小的记录,最低的槽位代表页面内索引顺序最大的记录。就是说在页面内,是通过槽的位置的顺序,来表示所有记录的顺序。在查询记录时。先根据page directory 确定记录所在的范围,然后在据此进行线性查询。书上给了一个图,侧重于槽跟记录的关系。

可见槽的数据是没有顺序的。第0个槽位是989,对应值是1,串起来记录是1,2,3,4的值,而值为4的记录指向下一个偏移量是289值为6的记录。这个位置正好是1号槽。值为4的记录也是0号槽最后一条记录。以此类推,找到页面所有数据。增加slot的函数参阅 page_dir_add_slot。
在InnoDB中,需要查找某条件记录,需要调用函数page_cur_search_with_match,但如果需要定位某个位置,例如大于某条记录的第一条记录,也需要使用同一个函数。定位的位置有PAGE_CUR_G,PAGE_CUR_GE,PAGE_CUR_L,PAGE_CUR_LE四种,分别表示大于,大于等于,小于,小于等于四种位置。由于数据页目录的存在,查找和定位就相对简单,先用二分查找,定位周边的两个目录,然后再用线性查找的方式定位最终的记录或者位置。
此外,由于每次插入前,都需要调用这个函数确定插入位置,为了提高效率,InnoDB针对按照主键顺序插入的场景做了一个小小的优化。因为如果按照主键顺序插入的话,能保证每次都插入在这个数据页的最后,所以只需要直接把位置直接定位在数据页的最后(PAGE_LAST_INSERT)就可以了。至于怎么判断当前是否按照主键顺序插入,就依赖PAGE_N_DIRECTION,PAGE_LAST_INSERT,PAGE_DIRECTION这几个信息了,目前的代码中要求满足5个条件:
- 当前的数据页是叶子节点
- 位置查询模式为PAGE_CUR_LE
- 相同方向的插入已经大于3了(
page_header_get_field(page, PAGE_N_DIRECTION) > 3) - 最后插入的记录的偏移量为空(
page_header_get_ptr(page, PAGE_LAST_INSERT) != 0) - 从右边插入的(
page_header_get_field(page, PAGE_DIRECTION) == PAGE_RIGHT)
源码在page/page0cur.cc
/****************************************************************//**
Searches the right position for a page cursor. */
void
page_cur_search_with_match(
/*=======================*/
const buf_block_t* block, /*!< in: buffer block */
const dict_index_t* index, /*!< in/out: record descriptor */
const dtuple_t* tuple, /*!< in: data tuple */
page_cur_mode_t mode, /*!< in: PAGE_CUR_L,
PAGE_CUR_LE, PAGE_CUR_G, or
PAGE_CUR_GE */
ulint* iup_matched_fields,
/*!< in/out: already matched
fields in upper limit record */
ulint* ilow_matched_fields,
/*!< in/out: already matched
fields in lower limit record */
page_cur_t* cursor, /*!< out: page cursor */
rtr_info_t* rtr_info)/*!< in/out: rtree search stack */
{
ulint up;
ulint low;
ulint mid;
const page_t* page;
const page_dir_slot_t* slot;
const rec_t* up_rec;
const rec_t* low_rec;
const rec_t* mid_rec;
ulint up_matched_fields;
ulint low_matched_fields;
ulint cur_matched_fields;
int cmp;
#ifdef UNIV_ZIP_DEBUG
const page_zip_des_t* page_zip = buf_block_get_page_zip(block);
#endif /* UNIV_ZIP_DEBUG */
mem_heap_t* heap = NULL;
ulint offsets_[REC_OFFS_NORMAL_SIZE];
ulint* offsets = offsets_;
rec_offs_init(offsets_);
ut_ad(dtuple_validate(tuple));
#ifdef UNIV_DEBUG
# ifdef PAGE_CUR_DBG
if (mode != PAGE_CUR_DBG)
# endif /* PAGE_CUR_DBG */
# ifdef PAGE_CUR_LE_OR_EXTENDS
if (mode != PAGE_CUR_LE_OR_EXTENDS)
# endif /* PAGE_CUR_LE_OR_EXTENDS */
ut_ad(mode == PAGE_CUR_L || mode == PAGE_CUR_LE
|| mode == PAGE_CUR_G || mode == PAGE_CUR_GE
|| dict_index_is_spatial(index));
#endif /* UNIV_DEBUG */
page = buf_block_get_frame(block);
#ifdef UNIV_ZIP_DEBUG
ut_a(!page_zip || page_zip_validate(page_zip, page, index));
#endif /* UNIV_ZIP_DEBUG */
ut_d(page_check_dir(page));
#ifdef PAGE_CUR_ADAPT
if (page_is_leaf(page)
&& (mode == PAGE_CUR_LE)
&& !dict_index_is_spatial(index)
&& (page_header_get_field(page, PAGE_N_DIRECTION) > 3)
&& (page_header_get_ptr(page, PAGE_LAST_INSERT))
&& (page_header_get_field(page, PAGE_DIRECTION) == PAGE_RIGHT)) {
if (page_cur_try_search_shortcut(
block, index, tuple,
iup_matched_fields,
ilow_matched_fields,
cursor)) {
return;
}
}
# ifdef PAGE_CUR_DBG
if (mode == PAGE_CUR_DBG) {
mode = PAGE_CUR_LE;
}
# endif
#endif
/* If the mode is for R-tree indexes, use the special MBR
related compare functions */
if (dict_index_is_spatial(index) && mode > PAGE_CUR_LE) {
/* For leaf level insert, we still use the traditional
compare function for now */
if (mode == PAGE_CUR_RTREE_INSERT && page_is_leaf(page)){
mode = PAGE_CUR_LE;
} else {
rtr_cur_search_with_match(
block, (dict_index_t*)index, tuple, mode,
cursor, rtr_info);
return;
}
}
/* The following flag does not work for non-latin1 char sets because
cmp_full_field does not tell how many bytes matched */
#ifdef PAGE_CUR_LE_OR_EXTENDS
ut_a(mode != PAGE_CUR_LE_OR_EXTENDS);
#endif /* PAGE_CUR_LE_OR_EXTENDS */
/* If mode PAGE_CUR_G is specified, we are trying to position the
cursor to answer a query of the form "tuple < X", where tuple is
the input parameter, and X denotes an arbitrary physical record on
the page. We want to position the cursor on the first X which
satisfies the condition. */
up_matched_fields = *iup_matched_fields;
low_matched_fields = *ilow_matched_fields;
/* Perform binary search. First the search is done through the page
directory, after that as a linear search in the list of records
owned by the upper limit directory slot. */
low = 0;
up = page_dir_get_n_slots(page) - 1;
/* Perform binary search until the lower and upper limit directory
slots come to the distance 1 of each other */
while (up - low > 1) {
mid = (low + up) / 2;
slot = page_dir_get_nth_slot(page, mid);
mid_rec = page_dir_slot_get_rec(slot);
cur_matched_fields = std::min(low_matched_fields,
up_matched_fields);
offsets = offsets_;
if (index->rec_cache.fixed_len_key) {
offsets = populate_offsets(
mid_rec, tuple,
const_cast<dict_index_t*>(index),
offsets, &heap);
} else {
offsets = rec_get_offsets(
mid_rec, index, offsets,
dtuple_get_n_fields_cmp(tuple), &heap);
}
cmp = cmp_dtuple_rec_with_match(
tuple, mid_rec, offsets, &cur_matched_fields);
if (cmp > 0) {
low_slot_match:
low = mid;
low_matched_fields = cur_matched_fields;
} else if (cmp) {
#ifdef PAGE_CUR_LE_OR_EXTENDS
if (mode == PAGE_CUR_LE_OR_EXTENDS
&& page_cur_rec_field_extends(
tuple, mid_rec, offsets,
cur_matched_fields)) {
goto low_slot_match;
}
#endif /* PAGE_CUR_LE_OR_EXTENDS */
up_slot_match:
up = mid;
up_matched_fields = cur_matched_fields;
} else if (mode == PAGE_CUR_G || mode == PAGE_CUR_LE
#ifdef PAGE_CUR_LE_OR_EXTENDS
|| mode == PAGE_CUR_LE_OR_EXTENDS
#endif /* PAGE_CUR_LE_OR_EXTENDS */
) {
goto low_slot_match;
} else {
goto up_slot_match;
}
}
slot = page_dir_get_nth_slot(page, low);
low_rec = page_dir_slot_get_rec(slot);
slot = page_dir_get_nth_slot(page, up);
up_rec = page_dir_slot_get_rec(slot);
/* Perform linear search until the upper and lower records come to
distance 1 of each other. */
while (page_rec_get_next_const(low_rec) != up_rec) {
mid_rec = page_rec_get_next_const(low_rec);
cur_matched_fields = std::min(low_matched_fields,
up_matched_fields);
offsets = offsets_;
if (index->rec_cache.fixed_len_key) {
offsets = populate_offsets(
mid_rec, tuple,
const_cast<dict_index_t*>(index),
offsets, &heap);
} else {
offsets = rec_get_offsets(
mid_rec, index, offsets,
dtuple_get_n_fields_cmp(tuple), &heap);
}
cmp = cmp_dtuple_rec_with_match(
tuple, mid_rec, offsets, &cur_matched_fields);
if (cmp > 0) {
low_rec_match:
low_rec = mid_rec;
low_matched_fields = cur_matched_fields;
} else if (cmp) {
#ifdef PAGE_CUR_LE_OR_EXTENDS
if (mode == PAGE_CUR_LE_OR_EXTENDS
&& page_cur_rec_field_extends(
tuple, mid_rec, offsets,
cur_matched_fields)) {
goto low_rec_match;
}
#endif /* PAGE_CUR_LE_OR_EXTENDS */
up_rec_match:
up_rec = mid_rec;
up_matched_fields = cur_matched_fields;
} else if (mode == PAGE_CUR_G || mode == PAGE_CUR_LE
#ifdef PAGE_CUR_LE_OR_EXTENDS
|| mode == PAGE_CUR_LE_OR_EXTENDS
#endif /* PAGE_CUR_LE_OR_EXTENDS */
) {
if (!cmp && !cur_matched_fields) {
#ifdef UNIV_DEBUG
mtr_t mtr;
mtr_start(&mtr);
/* We got a match, but cur_matched_fields is
0, it must have REC_INFO_MIN_REC_FLAG */
ulint rec_info = rec_get_info_bits(mid_rec,
rec_offs_comp(offsets));
ut_ad(rec_info & REC_INFO_MIN_REC_FLAG);
ut_ad(btr_page_get_prev(page, &mtr) == FIL_NULL);
mtr_commit(&mtr);
#endif
cur_matched_fields = dtuple_get_n_fields_cmp(tuple);
}
goto low_rec_match;
} else {
goto up_rec_match;
}
}
if (mode <= PAGE_CUR_GE) {
page_cur_position(up_rec, block, cursor);
} else {
page_cur_position(low_rec, block, cursor);
}
*iup_matched_fields = up_matched_fields;
*ilow_matched_fields = low_matched_fields;
if (UNIV_LIKELY_NULL(heap)) {
mem_heap_free(heap);
}
}
中间的low,up就是开始二分查找了,所以可以理解B+树是通过树形结构找到一个记录所在页面的,而页面内部真正找到这条记录是通过slot完成的。理论加源码才是硬道理。
数据页尾部(Fil Trailer)
这个部分处于数据页最后的位置,这里起一个前后对应的关系,页面最开始的位置存储了checksum。尾部只有8个字节,低地址的四个字节存储checksum的值,高地址的四个字节存储FIL_PAGE_LSN的低位四字节。注意这里的checksum的值不一定与FIL_PAGE_SPACE_OR_CHKSUM的相同,这个依赖不同的checksum计算方法。下面简单介绍,不展开方法本身。
数据页的checksum值的计算方法依赖参数innodb_checksum_algorithm。目前提供三种计算checksum的方法,第一种是crc校验(buf_calc_page_crc32),这种是一种比较新的计算方法,但是可以使用cpu硬件指令来加速。第二种是innodb校验,是innodb自己开发的一种计算方法,但是有新老两种变体,两种变体计算结果不同,为了兼容老的变体,需要在代码中兼容。第三种是none模式,这种计算方式不计算每个数据页的校验值,而是使用一个指定的值填充checksum字段,这种方式速度很快,但也保证不了数据的正确性。在innodb_checksum_algorithm中,除了innodb,crc32,none三种选项之外,还有strict带头的选项。strict的选项表示,在读取的时候必须是指定的校验方式的校验值才通过,其他的都不行,例如,指定了strict_crc32,那么在数据页被读取计算checksum时候,对应的校验值必须也是crc32的才可通过,但是如果指定crc32,如果存储的是innodb或者none的结果,也是可以通过校验的。之所以提供了这种选项,就是为了兼容老版本的mysql以及防止校验算法被修改而导致的数据不可用。这里提醒一下,使用strict模式由于计算量比较小,因此效率相对较高。
核心方法:插入、删除数据
上面我们已经介绍完page的页面结构及管理方式,希望对我们日常开发有所帮助。
前面我们知道页面的不断插入、删除数据,经过一段时间会造成页面空间非常碎,造成表里有空间,但是free链表放不下记录。称为碎片页面。空间占用高,索引数据少,大量无效IO,数据库性能变差。需要回收。
看一下核心数据的方法:page_cur_insert_rec_low 代码在page/page0cur.cc
- 获取记录的长度。函数传入参数就有已经组合好的完整记录,所以只需要从记录的元数据中获取即可。
- 首先从PAGE_FREE链表中尝试获取足够的空间。仅仅比较链表头的一个记录,如果这个记录的空间大于需要插入的记录的空间,则复用这块空间(包括heap_no),否则就从PAGE_HEAP_TOP分配空间。如果这两个地方都没有,则返回空。这里注意一下,由于只判断Free链表的第一个头元素,所以算法对空间的利用率不是很高,估计也是为了操作方便。假设,某个数据页首先删除了几条大的记录,但是最后一条删除的是比较小的记录A,那么后续插入的记录大小只有比记录A还小,才能把Free链表利用起来。举个例子,假设先后删除记录的大小为4K, 3K, 5K, 2K,那么只有当插入的记录小于2K时候,这些被删除的空间才会被利用起来,假设新插入的记录是0.5K,那么Free链表头的2K,可以被重用,但是只是用了前面的0.5K,剩下的1.5K依然会被浪费,下次插入只能利用5K记录所占的空间,并不会把剩下的1.5K也利用起来。这些特性,从底层解释了,为什么InnoDB那么容易产生碎片,经常需要进行空间整理。
- 如果Free链表不够,就从PAGE_HEAP_TOP分配,如果分配成功,需要递增PAGE_N_HEAP。
- 如果这个数据页有足够的空间,则拷贝记录到指定的空间。
- 修改新插入记录前驱上的next指针,同时修改这条新插入记录的指针next指针。这两步主要是保证记录上链表的连续性。
- 递增PAGE_N_RECS。设置heap_no。设置owned值为0。
- 更新PAGE_LAST_INSERT,PAGE_DIRECTION,PAGE_N_DIRECTION,设置这些参数后,可以一定程度上提高连续插入的性能,因为插入前需要先定位插入的位置,有了这些信息可以加快查找。详见查找记录代码分析。
- 修改数据目录。因为增加了一条新的记录,可能有些目录own的记录数量超过了最大值(目前是8条),需要重新整理一下这个数据页的目录(page_dir_split_slot)。算法比较简单,就是找到中间节点,然后用这个中间节点重新构建一个新的目录,为了给这个新的目录腾空间,需要把后续的所有目录都平移,这个涉及一次momove操作(page_dir_split_slot和page_dir_add_slot)。
- 写redolog日志,持久化操作。
- 如果有blob字段,则处理独立的off-page。
/***********************************************************//**
Inserts a record next to page cursor on an uncompressed page.
Returns pointer to inserted record if succeed, i.e., enough
space available, NULL otherwise. The cursor stays at the same position.
@return pointer to record if succeed, NULL otherwise */
rec_t*
page_cur_insert_rec_low(
/*====================*/
rec_t* current_rec,/*!< in: pointer to current record after
which the new record is inserted */
dict_index_t* index, /*!< in: record descriptor */
const rec_t* rec, /*!< in: pointer to a physical record */
ulint* offsets,/*!< in/out: rec_get_offsets(rec, index) */
mtr_t* mtr) /*!< in: mini-transaction handle, or NULL */
{
byte* insert_buf;
ulint rec_size;
page_t* page; /*!< the relevant page */
rec_t* last_insert; /*!< cursor position at previous
insert */
rec_t* free_rec; /*!< a free record that was reused,
or NULL */
rec_t* insert_rec; /*!< inserted record */
ulint heap_no; /*!< heap number of the inserted
record */
ut_ad(rec_offs_validate(rec, index, offsets));
page = page_align(current_rec);
ut_ad(dict_table_is_comp(index->table)
== (ibool) !!page_is_comp(page));
ut_ad(fil_page_index_page_check(page));
ut_ad(mach_read_from_8(page + PAGE_HEADER + PAGE_INDEX_ID) == index->id
|| recv_recovery_is_on()
|| (mtr ? mtr->is_inside_ibuf() : dict_index_is_ibuf(index)));
ut_ad(!page_rec_is_supremum(current_rec));
/* 1. Get the size of the physical record in the page */
rec_size = rec_offs_size(offsets);
#ifdef UNIV_DEBUG_VALGRIND
{
const void* rec_start
= rec - rec_offs_extra_size(offsets);
ulint extra_size
= rec_offs_extra_size(offsets)
- (rec_offs_comp(offsets)
? REC_N_NEW_EXTRA_BYTES
: REC_N_OLD_EXTRA_BYTES);
/* All data bytes of the record must be valid. */
UNIV_MEM_ASSERT_RW(rec, rec_offs_data_size(offsets));
/* The variable-length header must be valid. */
UNIV_MEM_ASSERT_RW(rec_start, extra_size);
}
#endif /* UNIV_DEBUG_VALGRIND */
/* 2. Try to find suitable space from page memory management */
free_rec = page_header_get_ptr(page, PAGE_FREE);
if (UNIV_LIKELY_NULL(free_rec)) {
/* Try to allocate from the head of the free list. */
ulint foffsets_[REC_OFFS_NORMAL_SIZE];
ulint* foffsets = foffsets_;
mem_heap_t* heap = NULL;
rec_offs_init(foffsets_);
foffsets = rec_get_offsets(
free_rec, index, foffsets, ULINT_UNDEFINED, &heap);
if (rec_offs_size(foffsets) < rec_size) {
if (UNIV_LIKELY_NULL(heap)) {
mem_heap_free(heap);
}
goto use_heap;
}
insert_buf = free_rec - rec_offs_extra_size(foffsets);
if (page_is_comp(page)) {
heap_no = rec_get_heap_no_new(free_rec);
page_mem_alloc_free(page, NULL,
rec_get_next_ptr(free_rec, TRUE),
rec_size);
} else {
heap_no = rec_get_heap_no_old(free_rec);
page_mem_alloc_free(page, NULL,
rec_get_next_ptr(free_rec, FALSE),
rec_size);
}
if (UNIV_LIKELY_NULL(heap)) {
mem_heap_free(heap);
}
} else {
use_heap:
free_rec = NULL;
insert_buf = page_mem_alloc_heap(page, NULL,
rec_size, &heap_no);
if (UNIV_UNLIKELY(insert_buf == NULL)) {
return(NULL);
}
}
/* 3. Create the record */
insert_rec = rec_copy(insert_buf, rec, offsets);
rec_offs_make_valid(insert_rec, index, offsets);
/* 4. Insert the record in the linked list of records */
ut_ad(current_rec != insert_rec);
{
/* next record after current before the insertion */
rec_t* next_rec = page_rec_get_next(current_rec);
#ifdef UNIV_DEBUG
if (page_is_comp(page)) {
ut_ad(rec_get_status(current_rec)
<= REC_STATUS_INFIMUM);
ut_ad(rec_get_status(insert_rec) < REC_STATUS_INFIMUM);
ut_ad(rec_get_status(next_rec) != REC_STATUS_INFIMUM);
}
#endif
page_rec_set_next(insert_rec, next_rec);
page_rec_set_next(current_rec, insert_rec);
}
page_header_set_field(page, NULL, PAGE_N_RECS,
1 + page_get_n_recs(page));
/* 5. Set the n_owned field in the inserted record to zero,
and set the heap_no field */
if (page_is_comp(page)) {
rec_set_n_owned_new(insert_rec, NULL, 0);
rec_set_heap_no_new(insert_rec, heap_no);
} else {
rec_set_n_owned_old(insert_rec, 0);
rec_set_heap_no_old(insert_rec, heap_no);
}
UNIV_MEM_ASSERT_RW(rec_get_start(insert_rec, offsets),
rec_offs_size(offsets));
/* 6. Update the last insertion info in page header */
last_insert = page_header_get_ptr(page, PAGE_LAST_INSERT);
ut_ad(!last_insert || !page_is_comp(page)
|| rec_get_node_ptr_flag(last_insert)
== rec_get_node_ptr_flag(insert_rec));
if (!dict_index_is_spatial(index)) {
if (UNIV_UNLIKELY(last_insert == NULL)) {
page_header_set_field(page, NULL, PAGE_DIRECTION,
PAGE_NO_DIRECTION);
page_header_set_field(page, NULL, PAGE_N_DIRECTION, 0);
} else if ((last_insert == current_rec)
&& (page_header_get_field(page, PAGE_DIRECTION)
!= PAGE_LEFT)) {
page_header_set_field(page, NULL, PAGE_DIRECTION,
PAGE_RIGHT);
page_header_set_field(page, NULL, PAGE_N_DIRECTION,
page_header_get_field(
page, PAGE_N_DIRECTION) + 1);
} else if ((page_rec_get_next(insert_rec) == last_insert)
&& (page_header_get_field(page, PAGE_DIRECTION)
!= PAGE_RIGHT)) {
page_header_set_field(page, NULL, PAGE_DIRECTION,
PAGE_LEFT);
page_header_set_field(page, NULL, PAGE_N_DIRECTION,
page_header_get_field(
page, PAGE_N_DIRECTION) + 1);
} else {
page_header_set_field(page, NULL, PAGE_DIRECTION,
PAGE_NO_DIRECTION);
page_header_set_field(page, NULL, PAGE_N_DIRECTION, 0);
}
}
page_header_set_ptr(page, NULL, PAGE_LAST_INSERT, insert_rec);
/* 7. It remains to update the owner record. */
{
rec_t* owner_rec = page_rec_find_owner_rec(insert_rec);
ulint n_owned;
if (page_is_comp(page)) {
n_owned = rec_get_n_owned_new(owner_rec);
rec_set_n_owned_new(owner_rec, NULL, n_owned + 1);
} else {
n_owned = rec_get_n_owned_old(owner_rec);
rec_set_n_owned_old(owner_rec, n_owned + 1);
}
/* 8. Now we have incremented the n_owned field of the owner
record. If the number exceeds PAGE_DIR_SLOT_MAX_N_OWNED,
we have to split the corresponding directory slot in two. */
if (UNIV_UNLIKELY(n_owned == PAGE_DIR_SLOT_MAX_N_OWNED)) {
page_dir_split_slot(
page, NULL,
page_dir_find_owner_slot(owner_rec));
}
}
/* 9. Write log record of the insert */
if (UNIV_LIKELY(mtr != NULL)) {
page_cur_insert_rec_write_log(insert_rec, rec_size,
current_rec, index, mtr);
}
return(insert_rec);
}删除数据
注意这里的删除操作是指真正的删除物理记录,而不是标记记录为delete-mark。核心函数入口函数在page_cur_delete_rec。步骤如下:
- 如果需要删除的记录是这个数据页的最后一个记录,那么直接把这个数据页重新初始化成空页(
page_create_empty)即可。 - 如果不是最后一条,就走正常路径。首先记录redolog日志。
- 重置
PAGE_LAST_INSERT和递增block的modify clock。后者主要是为了让乐观的查询失效。 - 找到需要删除记录的前驱和后继记录,然后修改指针,使前驱直接指向后继。这样记录的链表上就没有这条记录了。
- 如果一个目录指向这条被删除的记录,那么让这个目录指向删除记录的前驱,同时减少这个目录own的记录数。
- 如果这个记录有blob的off-page,则删除。
- 把记录放到
PAGE_FREE链表头部,然后递增PAGE_GARBAGE的大小,减小PAGE_N_RECS用户记录的值。 - 由于第五步中递减了own值,可能导致own的记录数小于最小值(目前是4条)。所以需要重新均衡目录,可能需要删除某些目录(
page_dir_balance_slot)。具体算法也比较简单,首先判断是否可以从周围的目录中挪一条记录过来,如果可以直接调整一下前后目录的指针即可。这种简单的调整要求被挪出记录的目录own的记录数量足够多,如果也没有足够的记录,就需要删除其中一个目录,然后把后面的目录都向前平移(page_dir_delete_slot)。
/***********************************************************//**
Deletes a record at the page cursor. The cursor is moved to the next
record after the deleted one. */
void
page_cur_delete_rec(
/*================*/
page_cur_t* cursor, /*!< in/out: a page cursor */
const dict_index_t* index, /*!< in: record descriptor */
const ulint* offsets,/*!< in: rec_get_offsets(
cursor->rec, index) */
mtr_t* mtr) /*!< in: mini-transaction handle
or NULL */
{
page_dir_slot_t* cur_dir_slot;
page_dir_slot_t* prev_slot;
page_t* page;
page_zip_des_t* page_zip;
rec_t* current_rec;
rec_t* prev_rec = NULL;
rec_t* next_rec;
ulint cur_slot_no;
ulint cur_n_owned;
rec_t* rec;
page = page_cur_get_page(cursor);
page_zip = page_cur_get_page_zip(cursor);
/* page_zip_validate() will fail here when
btr_cur_pessimistic_delete() invokes btr_set_min_rec_mark().
Then, both "page_zip" and "page" would have the min-rec-mark
set on the smallest user record, but "page" would additionally
have it set on the smallest-but-one record. Because sloppy
page_zip_validate_low() only ignores min-rec-flag differences
in the smallest user record, it cannot be used here either. */
current_rec = cursor->rec;
ut_ad(rec_offs_validate(current_rec, index, offsets));
ut_ad(!!page_is_comp(page) == dict_table_is_comp(index->table));
ut_ad(fil_page_index_page_check(page));
ut_ad(mach_read_from_8(page + PAGE_HEADER + PAGE_INDEX_ID) == index->id
|| (mtr ? mtr->is_inside_ibuf() : dict_index_is_ibuf(index))
|| recv_recovery_is_on());
ut_ad(mtr == NULL || mtr->is_named_space(index->space));
/* The record must not be the supremum or infimum record. */
ut_ad(page_rec_is_user_rec(current_rec));
if (page_get_n_recs(page) == 1 && !recv_recovery_is_on()) {
/* Empty the page, unless we are applying the redo log
during crash recovery. During normal operation, the
page_create_empty() gets logged as one of MLOG_PAGE_CREATE,
MLOG_COMP_PAGE_CREATE, MLOG_ZIP_PAGE_COMPRESS. */
ut_ad(page_is_leaf(page));
/* Usually, this should be the root page,
and the whole index tree should become empty.
However, this could also be a call in
btr_cur_pessimistic_update() to delete the only
record in the page and to insert another one. */
page_cur_move_to_next(cursor);
ut_ad(page_cur_is_after_last(cursor));
page_create_empty(page_cur_get_block(cursor),
const_cast<dict_index_t*>(index), mtr);
return;
}
/* Save to local variables some data associated with current_rec */
cur_slot_no = page_dir_find_owner_slot(current_rec);
ut_ad(cur_slot_no > 0);
cur_dir_slot = page_dir_get_nth_slot(page, cur_slot_no);
cur_n_owned = page_dir_slot_get_n_owned(cur_dir_slot);
/* 0. Write the log record */
if (mtr != 0) {
page_cur_delete_rec_write_log(current_rec, index, mtr);
}
/* 1. Reset the last insert info in the page header and increment
the modify clock for the frame */
page_header_set_ptr(page, page_zip, PAGE_LAST_INSERT, NULL);
/* The page gets invalid for optimistic searches: increment the
frame modify clock only if there is an mini-transaction covering
the change. During IMPORT we allocate local blocks that are not
part of the buffer pool. */
if (mtr != 0) {
buf_block_modify_clock_inc(page_cur_get_block(cursor));
}
/* 2. Find the next and the previous record. Note that the cursor is
left at the next record. */
ut_ad(cur_slot_no > 0);
prev_slot = page_dir_get_nth_slot(page, cur_slot_no - 1);
rec = (rec_t*) page_dir_slot_get_rec(prev_slot);
/* rec now points to the record of the previous directory slot. Look
for the immediate predecessor of current_rec in a loop. */
while (current_rec != rec) {
prev_rec = rec;
rec = page_rec_get_next(rec);
}
page_cur_move_to_next(cursor);
next_rec = cursor->rec;
/* 3. Remove the record from the linked list of records */
page_rec_set_next(prev_rec, next_rec);
/* 4. If the deleted record is pointed to by a dir slot, update the
record pointer in slot. In the following if-clause we assume that
prev_rec is owned by the same slot, i.e., PAGE_DIR_SLOT_MIN_N_OWNED
>= 2. */
#if PAGE_DIR_SLOT_MIN_N_OWNED < 2
# error "PAGE_DIR_SLOT_MIN_N_OWNED < 2"
#endif
ut_ad(cur_n_owned > 1);
if (current_rec == page_dir_slot_get_rec(cur_dir_slot)) {
page_dir_slot_set_rec(cur_dir_slot, prev_rec);
}
/* 5. Update the number of owned records of the slot */
page_dir_slot_set_n_owned(cur_dir_slot, page_zip, cur_n_owned - 1);
/* 6. Free the memory occupied by the record */
page_mem_free(page, page_zip, current_rec, index, offsets);
/* 7. Now we have decremented the number of owned records of the slot.
If the number drops below PAGE_DIR_SLOT_MIN_N_OWNED, we balance the
slots. */
if (cur_n_owned <= PAGE_DIR_SLOT_MIN_N_OWNED) {
page_dir_balance_slot(page, page_zip, cur_slot_no);
}
#ifdef UNIV_ZIP_DEBUG
ut_a(!page_zip || page_zip_validate(page_zip, page, index));
#endif /* UNIV_ZIP_DEBUG */
}
#ifdef UNIV_COMPILE_TEST_FUNCS总结
总体来说,InnoDB数据页的结构设计折中了插入,删除以及查找的效率,是一种值得学习的数据结构。就是源码看的头疼。