今天来一篇实战项目,scrapy+selenium爬取豆瓣的动态网页加上爬取的数据进行数据分析,来看一看会有什么好玩的东西。
一直有个抓取火爆明星信息的念头,今天终于开干,先找个入口,于是得到这个网页:http://top.baidu.com/buzz?b=17这是男演员热搜排行榜,最后一个参数换成18是女演员排行榜。网页大体是这样子:
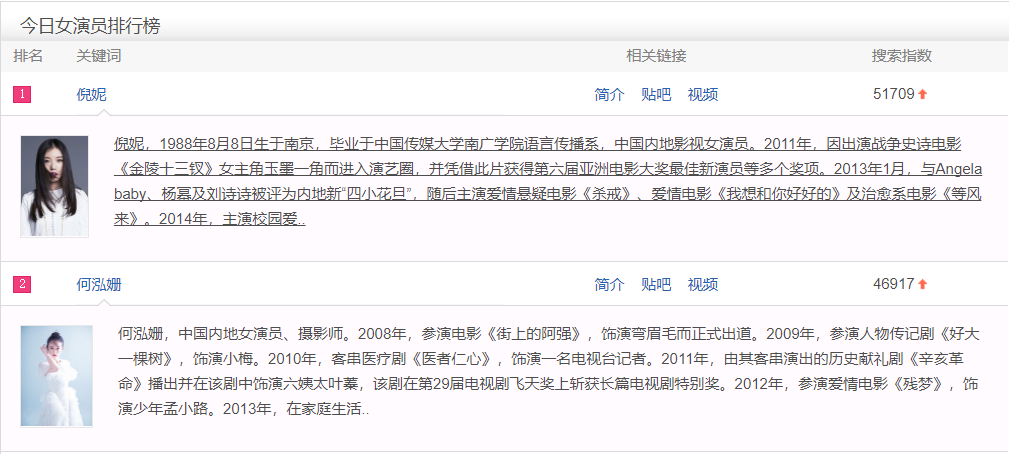
男,女各有前五十名,为了方便抓取与分析,只取各前二十五名。
爬虫实战
selenium动态爬取
我们获取到明星名字列表后,主要思路是通过豆瓣查询明星,然后再抓取该演员的影视详情,https://movie.douban.com/subject_search?search_text={}此链接是用于查询,{}内是姓名
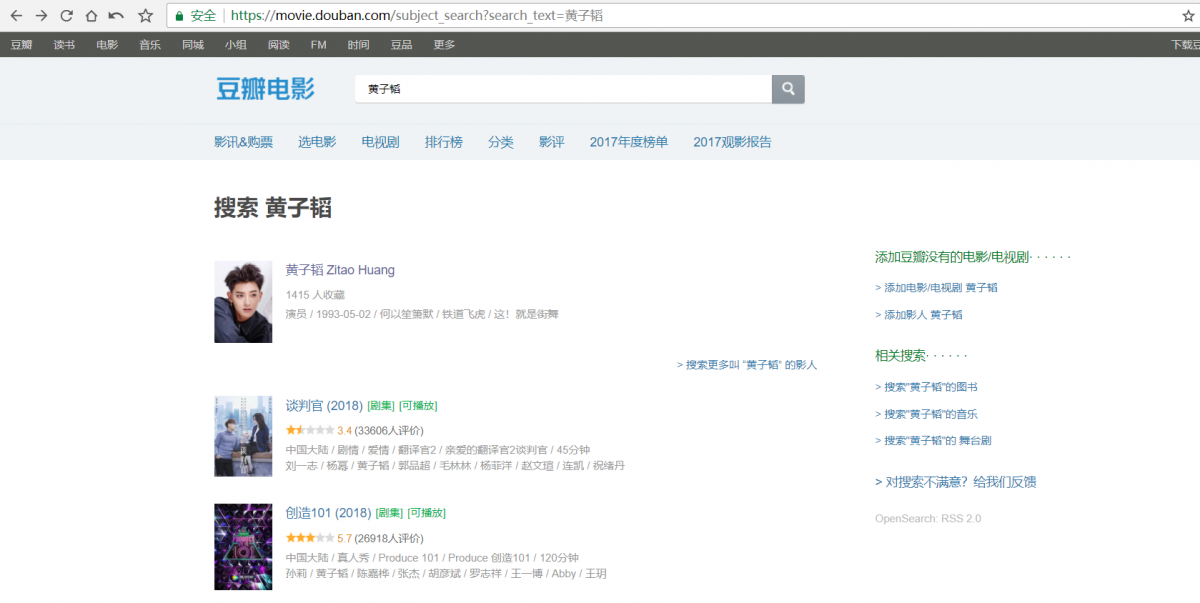
会拿到这样一个页面,点击第一条时,是通过ajax加载出来的,红框中的数字对应着不同的明星
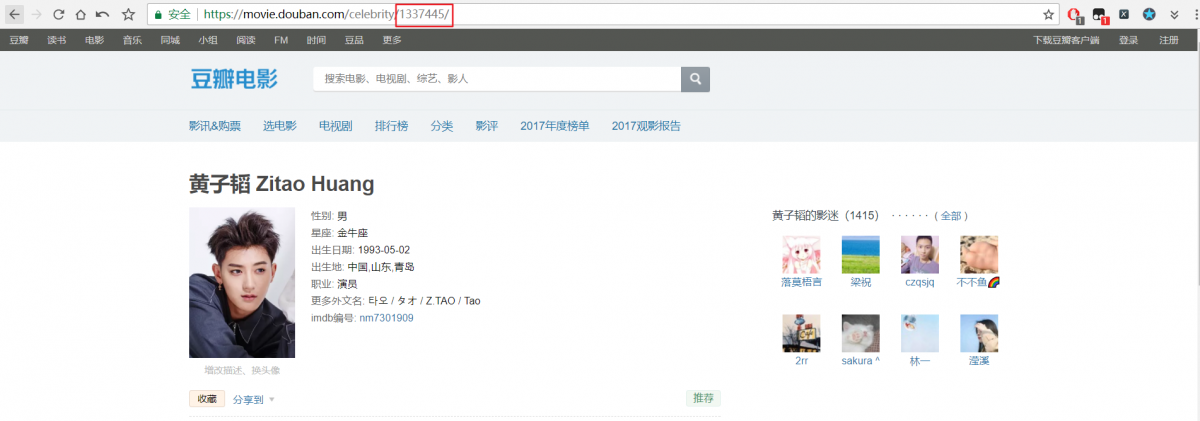
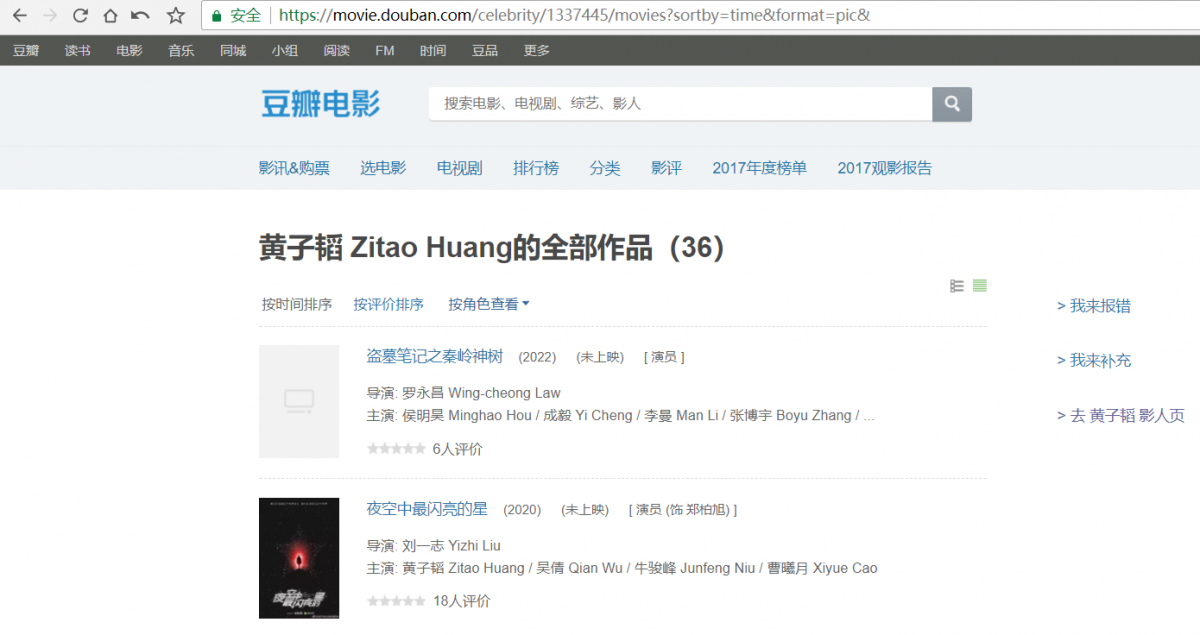
拿到那一串数字后,通过构造这样一个请求就能拿到影人的所有信息了https://movie.douban.com/celebrity/1337445/movies?sortby=time&format=pic&
selenium主要代码:
#不加载图片
p1 = webdriver.FirefoxProfile()
p1.set_preference('permissions.default.image',2)
driver = webdriver.Firefox(p1)
driver.get(response.url)
#拿到网页源码
page_s = driver.page_source
time.sleep(2)
driver.close()
#拿到数字
pattern = re.compile(r"https://movie.douban.com/celebrity/(.*?)/")
match = pattern.findall(page_s)
信息提取
拿到影人影视页面后,要进行提取,需要抓取的内容是红框的部分

第一个影视由于评价人数太少,没有评分,这种信息我们不再抓取,分析一下两者区别
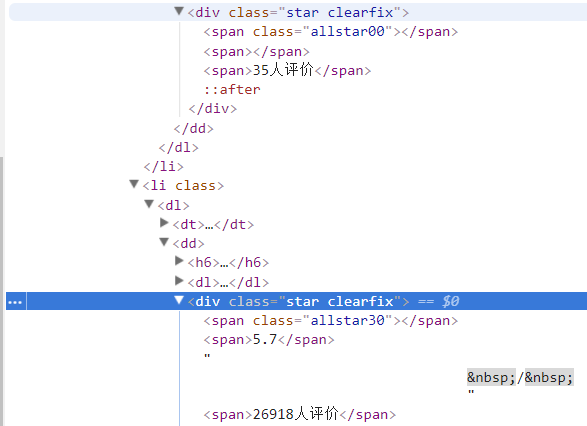
可以看出两个span的class,没有评分的是allstar00,另一个是allstar30,经过观察几个没有评分的,都是allstar00,所以进行抓取时要倒着抓,先找allstar后面不是00的,再通过父节点去抓取这一影视的其他信息。
#在xpath中用正则进行匹配
name_list = response.xpath('//span[re:match(@class,"allstar[1-9]\d{0,}")]/../../h6/a/text()').extract()
score_list = response.xpath('//span[re:match(@class,"allstar[1-9]\d{0,}")]/../span[2]/text()').extract()
写入文件
之后把抓取到的信息以csv格式存储
import csv
class DoubanPipeline(object):
def __init__(self):
with open('mingxing.csv', 'a', encoding='utf-8', newline='') as h:
writer = csv.writer(h)
writer.writerow(["姓名","性别","影视名称","分数","上映时间","评价人数"])
def process_item(self, item, spider):
with open('mingxing.csv', 'a', encoding='utf-8', newline='') as h:
writer = csv.writer(h)
writer.writerow((item['mingxing_name'],item['sex'],item['name'],item['score'],item['time'],item['num']))
return item由于豆瓣有反爬,对男星和女星分两次抓取,抓取的太多的话,会被禁掉ip,等几个小时,或者重启路由器可以解决问题。
数据分析
查看大致信息
首先把需要导入的库都导入,加入一个支持中文编码
plt.rcParams["font.sans-serif"]=["SimHei"] #用来正常显示中文标签
导入文件并查看
data = pd.read_csv("./mingxing.csv")
data.head()
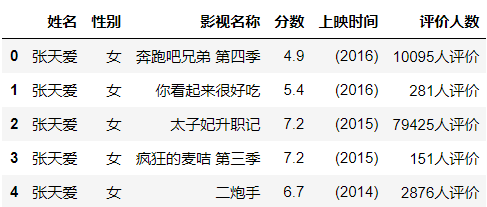
看看都有哪些明星
data['姓名'].unique()

这里面有没有你的爱豆噢,有的话可能等会就对不住了,毕竟我们要用数据说话。
数据处理
去掉时间里的括号
data['上映时间'] = data['上映时间'].str.replace("(","")
data['上映时间'] = data['上映时间'].str.replace(")","")
提取出评价人数中的数字,并把数字转化为数值类型
data['评价人数'] = data['评价人数'].str.extract("(\d+)")
data['评价人数'] = pd.to_numeric(data['评价人数'])
再次查看信息
data.head()
data.info()
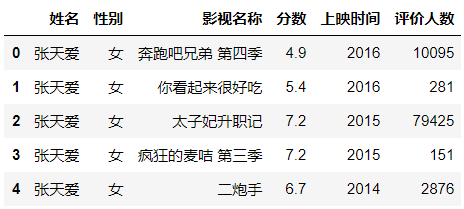

数据就整洁多了,共2360条信息,都没有空值。
数据分析
查看平得分,绝大多数还是在及格线以上的
ave_score = data.groupby('姓名')['分数'].mean()
display(ave_score.sort_values(ascending=False))
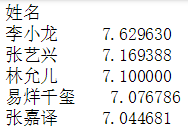

前五和后五,李小龙师傅果然厉害,后五就认识两个人,可能是我脱节了。
查看评价人数的平均值
num_total = data.groupby('姓名')['评价人数'].mean()
display(num_total.sort_values(ascending=False))

下面两张图是当时的排行榜的图:
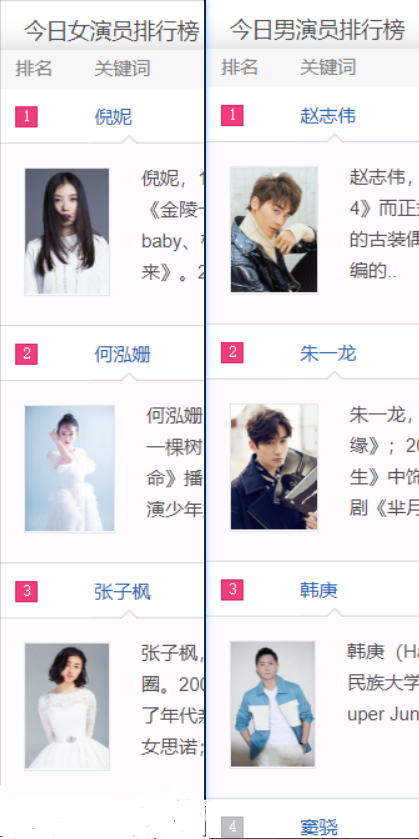
可以看出倪妮,张子枫,韩庚,窦饶也基本在排行榜前几,有着一定的相似。
统计每个明星的影视数量
d1 = pd.DataFrame(data['姓名'].value_counts())
#修改列名
d1.columns=['作品数量']
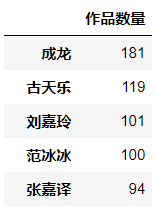
成龙大哥还是很拼啊,都一大把年纪了,还不断出新作品,我记的以前他好像说《十二生肖》是最后一部作品,如今还没退休呢。顺便调侃一下古仔,如果古仔又拍了烂片,那一定是没有钱做公益了,古仔是一位非常低调的慈善家,捐助了许许多多的希望小学,还经常到小学去看望学生,给古仔点个大大的赞。
看一下每位影星最好的作品与最差的作品的分差
pol_score = data.groupby('姓名')['分数'].apply(lambda x:x.max()-x.min())
display(pol_score.sort_values(ascending=False))
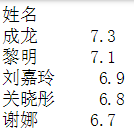
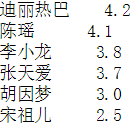
前五和后五,成龙大哥依然位居榜首,看来演多必失啊,这分差差出一个好作品了,后五中,可见李小龙师傅的水平还是相当稳定的,其他的也不好说,可能好的作品分不高,差的作品又不是特别差,毕竟豆瓣有个最低分2分限制着。
本来是想找一下作品全部都及格的影星,没料到却是没有,找了都高于5分的,竟然只有两位。
lis_failed = []
for i in data['姓名'].unique():
if all(data[data['姓名'] == i]['分数'] >5):
lis_failed.append(i)
lis_failed
>>>['胡因梦', '李小龙']
李小龙师傅作为中国功夫首位全球推广者、好莱坞首位华人主角果然名副其实。
作图分析
来个拉仇恨的操作,分析一下影星的烂片(低于6分)和非烂片(大于或等于6分)的比例,画个饼图
先通过数据分组聚合,拿到数据
d2 = pd.DataFrame(data[data['分数']<6]['姓名'].value_counts())
d2.columns=['不及格作品数量']
failed_per = pd.merge(d1,d2,left_index=True,right_index=True)
failed_per['及格作品数量'] = failed_per['作品数量'] - failed_per['不及格作品数量']
failed_per.drop(['作品数量'],axis=1,inplace=True)
d1是之前的一个作品总数的数据
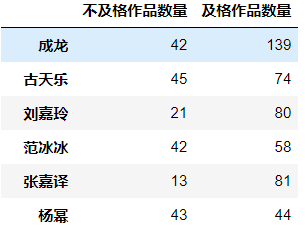
大幂幂快要持平了噢,画个饼图
a=0
figsize = 11,14
fig = plt.figure(figsize=figsize)
plot_pos = [331, 332, 333, 334, 335, 336, 337, 338, 339]
for i in data['姓名'].unique()[:9]:
ax = fig.add_subplot(plot_pos[a])
a=a+1
ax.pie(failed_per.loc[i],labels=['不及格','及格'],autopct='%.2f%%')
ax.set_title(i)
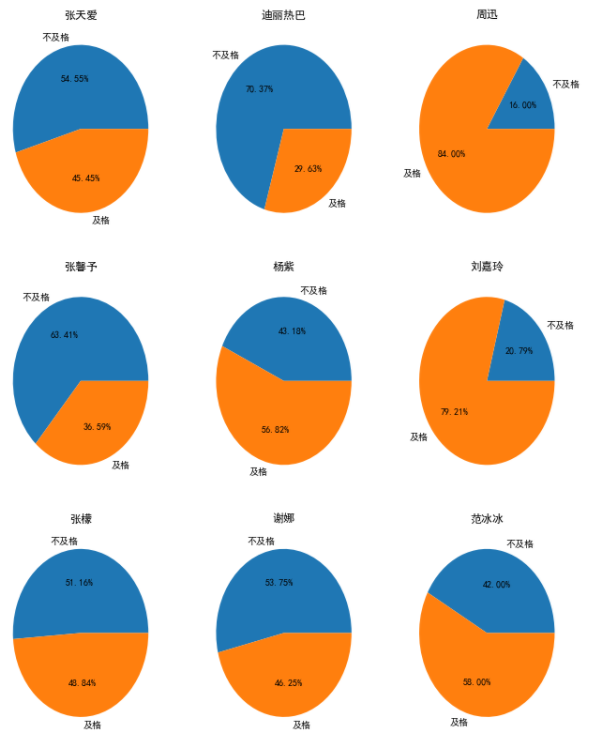
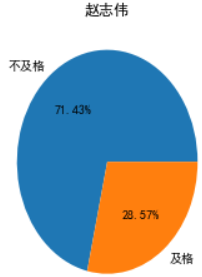
只会画九个子图所有,循环了几轮才画完,瞅一瞅谁的烂片率比较高,三个大于或等于70%的。
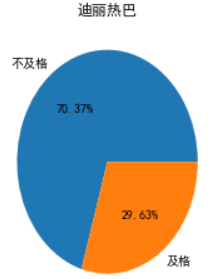
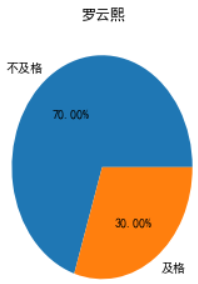
倒是有一个很让我惊讶,星女郎"林允"
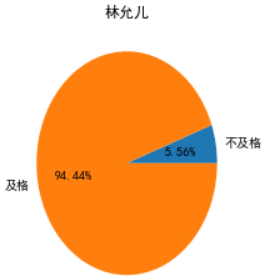
这是我认识的那个美人鱼林允嘛,吓的我赶紧查了查原数据,发现林允儿是韩国明星,中国的叫林允,这下不仅脸盲,名字都开始盲了。
再来一波作图分析,查看一下明星在每年的作品的平均水平,做个折线图。
先分组
time_score_mean = data.groupby(['姓名','上映时间'])['分数'].mean()
看一下
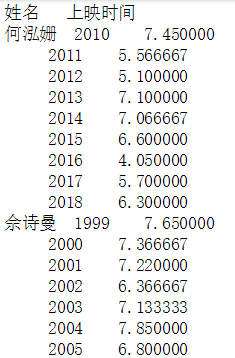
开始画图,依然循环很多轮
a=0
figsize = 11,14
fig = plt.figure(figsize=figsize)
plot_pos = [331, 332, 333, 334, 335, 336, 337, 338, 339]
for i in data['姓名'].unique()[:9]:
ax = fig.add_subplot(plot_pos[a])
a=a+1
ax.plot(pd.DataFrame(time_score_mean[i]).index, pd.DataFrame(time_score_mean[i])['分数'])
plt.grid(True)
ax.set_title(i)
不是我挑事噢,热巴的这个先吸引了我的眼球
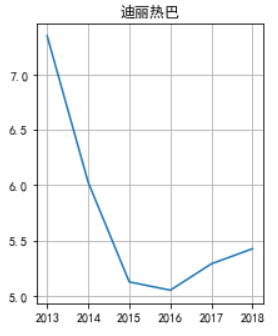
一个大跌,16年之后也在涨,那先加油吧。
成龙大哥的图也挺好玩,感觉演出了正态分布,忽略下面挤作一团的时间,不会调倾斜度,了解的大佬知会一下。
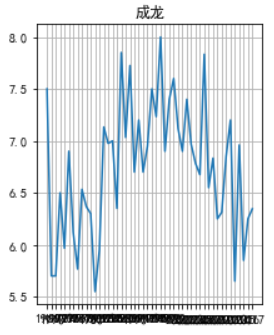
还有这位演员,下滑的拉不住了
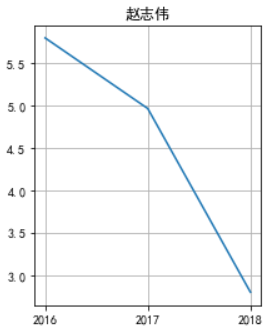
于是乎百度了一下,没错他演了电影版《爱情公寓》,解释的通了。
看一下我们的大猪蹄子的
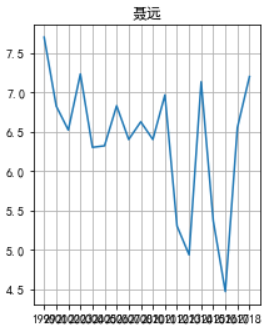
两次跌入谷底哎,18年这分数,《延禧攻略》没差了。
还有很多待挖掘的信息,大家可以自己动手来玩噢。
关注公众号,回复豆瓣源码,可以拿到爬虫和数据分析的所有代码,还有数据一份。
回复scrapy一份scrapy中文文档拿走。
