协同过滤通常用于创建推荐系统(例如,Netflix节目/电影推荐)。目前最先进的协同过滤模型实际上使用了一种非常简单的方法,结果很好。
在这篇文章中,我将概述这些最先进的模型,这些模型利用“浅层学习”,然后介绍一种利用深度学习的新方法(我认为很有前途!)。在这篇文章中,我将使用MovieLens数据集作为示例,其中包含用户对电影的评分。我还演示了如何在我的Github上提供的脚本中使用浅层和深层协作过滤,所以如果你想使用这些模型,请查看我的Github!这个脚本使用了优秀的深度学习库fastai(它是在PyTorch之上编写的)和PyTorch。
浅层学习
目前最流行的协同过滤模型使用称为嵌入矩阵的东西。嵌入矩阵包含多维信息。例如,假设我们有三个因素的电影嵌入矩阵。情况可能是这三个因素对应于电影的行动方式,电影的浪漫程度,以及电影是否与纪录片更相似。当然,这些因素可以对应于任何事物(并且不一定易于解释),并且嵌入式基质通常包含许多因素。在训练协作过滤模型时更新这些矩阵。使用MovieLens数据集示例,使用我们的标准协同过滤技术,我们将为用户和电影提供嵌入矩阵(请参见下图)。矩阵的大小将是我们选择的因素数量的用户或电影数量。关于选择嵌入矩阵中的因子数量,这需要一些反复试验。在我的示例脚本中 Github上,嵌入因子的数量设置为50.在训练开始之前,这些嵌入矩阵中的值是随机初始化的。在训练期间,这些值在更新中用于减少损失(即,使预测的评级更类似于实际评级)。在每次训练迭代期间,对于每个用户对电影的评级,采用相应矢量的点积。此点积是预测的评级。点击产品是针对每个用户评级的每部电影的评分(注意:未被电影评级的电影设置为0),并将预测的评级与实际评级进行比较。然后,使用随机梯度下降(或随机梯度下降的紧密变体)来更新嵌入矩阵内的值,以减少损失函数。除了嵌入矩阵之外,最先进的协同过滤模型还包含一个偏差项,它基本上是为某些用户提供的,这些用户总是会给出更高或更低的收视率或整体给予更高或更低收视率的电影。 (即好的或坏的电影)。这些偏差项被添加到点积中。

这就是最先进的协作过滤模型。正如你所看到的,所有这些背后的数学都非常简单,如果你看一下我在Github上发布的附带脚本,你会看到使用fastai库创建和训练一个状态。只需几行代码即可实现最先进的协同过滤模型。
深度学习
好的,所以我们已经介绍了目前最先进的协同过滤模型,该模型非常有效并且利用了“浅层学习”,但该领域的下一步是什么?一个有前景的方向可能是深度学习的协同过滤,因为(1)深度学习在其他工作领域(例如,计算机视觉)非常成功;(2)它允许更大的模型规范,这听起来真的很烦人,但是可以允许机器学习从业者创建针对其数据集定制的模型。据我所知,基于深度学习的协同过滤的想法首先在fastai MOOC中呈现,我认为这是该领域非常令人兴奋的方向!在深入学习协同过滤的细节之前,我不得不承认,使用示例MovieLens数据集,浅层学习模型优于深度学习模型。但是,我认为足够修改模型的体系结构并使用正确的数据集(可能是更大的数据集 - 我只使用了MovieLens数据集的一个子部分),深度学习的协同过滤可以胜过浅层学习模型。
在这里,我将讨论只有一个隐藏层的模型,但这些模型可以以任何你想要的方式进行定制!注意:我确实尝试添加更多图层,并且使用此数据集,一个隐藏图层模型执行得最好。
和以前一样,我们首先为电影和用户创建一个嵌入矩阵,其中随机初始化的权重(大小是指定数量的因素的用户或电影数量)。然后,对于每个用户和相应的电影嵌入因子向量,我们连接这些向量(见下图)。在示例脚本中,此时有一点点丢失(0.05)以防止过度拟合。然后,我们将连接嵌入因子向量乘以另一个矩阵,其中包含嵌入因子* 2的大小(在本例中,它必须是这个,因为这是连接嵌入向量中的列数)除了一些其他数字(在例如我有10)。然后通过整流线性单元激活功能(ReLU; 这是一种奇特的说法,将负值改为0); 这在深度学习中很常见,并且使函数非线性。同样,为了防止过度拟合,我们应用更多的dropout。之后,我们将矩阵乘积(通过ReLU和dropout)乘以一个矩阵,该矩阵具有一些其他行数(在本例中为10)和一列。因此,矩阵乘法的输出将是一个数字,这正是我们想要的,因为我们试图预测一个等级。然后将该预测评级通过S形函数(乘以[(最大评级 - 最小评级)+最小评级]),以使预测值更接近数据集中的实际预测。对于所有单个用户和评级都重复这一点,就像之前一样,
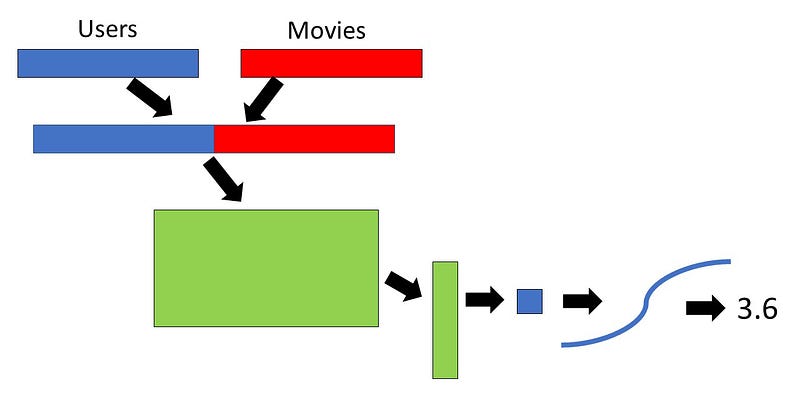
这里需要注意的是我没有提到任何关于偏差的内容,这是因为PyTorch中的线性层已经考虑了偏差,所以我们不必担心它。
同样,正如我之前提到的,深度学习模型比浅层学习模型更糟糕,但我相信这个框架是一个很有前途的工作。如果你想试试这篇文章中提到的例子,请查看我的Github。我期待听到读者的评论,也许还会看到协同过滤与深度学习的其他用途。
原文:https://towardsdatascience.com/collaborative-filtering-from-shallow-to-deep-learning-680926d5d844