以前工作优化过一个全表遍历、处理数据的逻辑,表中数据千万级,姑且成为表a吧。
经过排查最终发现性能瓶颈点,是遍历性能很低,类似这样的sql:
select * from a limit 0,10000;
select * from a limit 10000,10000。程序循环的使用这种模式的sql去遍历表,显然这种方式没法用到索引,越往后遍历性能越低。

如图,一个简单的sql执行时间14s多。
---------------------------------------------------------------
优化方案一 : 带索引链式遍历
实际上解决这个问题也挺简单,只要带索引遍历就快多了。
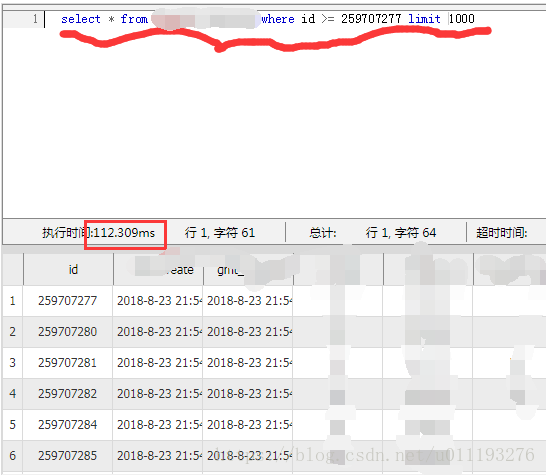
类似的查询效果,由于where条件中的id字段有索引,对于比较靠后的数据,查询性能轻松提升了百倍。
那初步的优化方案就很容易想到了,id有索引,而且是自增的,就从id=1开始遍历,结果集以id升序排列,然后根据结果集最后一条数据的id,继续下一次遍历,大致sql为:
select * from a where id > 0 order by id limit 10000;假如得到的最后一条数据id为10000,则下次遍历的sql为
select * from a where id > 10000 order by id limit 10000;...
依此类推,直到遍历完成
---------------------------------------------------------
优化方案二 : id分区实现多线程遍历
方案一有一个很明显的缺陷:下次遍历必须知道上次遍历的最后一个id的值,也就是前后遍历形成了一个依赖链,这导致无法实现遍历行为之间的并行操作,如图。
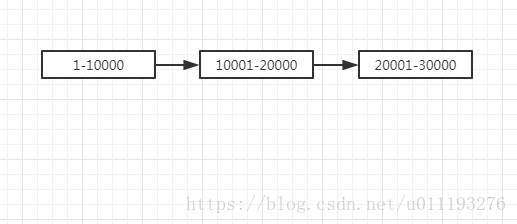
要实现并发遍历的关键在于id的分区,找到表的最大最小id,然后进行id的区间拆分,比如第一个线程遍历id区间为1-10000的数据,第二个线程遍历id区间为10001-20000的数据,依此类推,直到遍历到最大id。这样可以实现多个线程并行操作,性能会大大提升。

——找到表中最大最小id,确定id区间:
select min(id),max(id) from a limit 100;——多线程遍历,每个线程每批次拿10000个id,从min(id)开始,到max(id)结束:
线程1:
select * from a where id >= 1 and id <= 10000;线程2:
select * from a where id >= 100001 and id <=20000;...
当然,相对于第一种方案,第二种更适用于表数据id紧凑的情况,如果id区间拉得足够大(比如1-10亿),而实际数据量没多少(比如20000条),可能第一种效果更好一些,因为第一种无效遍历会少一些。
至于用游标啥的,公司开发没权限,DBA不给支持,没实验过,不过上述两种方案实际上完全够用了