版权声明:本文为博主原创文章,未经同意禁止转载! https://blog.csdn.net/xm1076709179/article/details/80044970
语音识别就是将包含文字信息的语音通过计算机转化成文字的过程,也叫语音转写,英文叫automatic speech recognition(ASR)或者 speech to text(STT),语音识别框架一般如图所示:
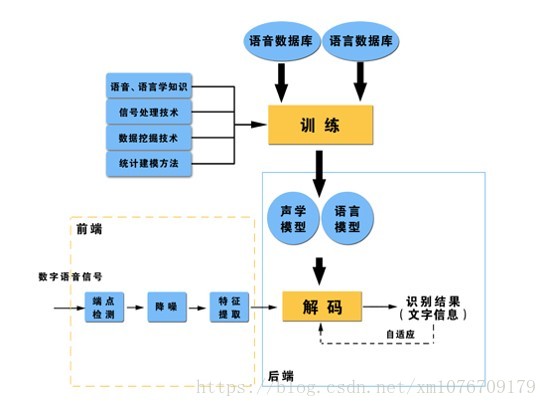
从上图中可以看出,语音识别技术是一个复杂的多学科交叉技术,涉及到信号处理、统计、机器学习、语言学、数据挖掘、生理学等知识。一个完整的语音识别系统声学方面和语言学方面。声学方面包括从最初的语音信号获取(这其中包括将语音转化成电信号)到语音信号处理(包括模数转换,降噪、增强、端点检测(VAD)等),再到特征提取(MFCC、FB、PLP、BN等),最后到声学模型建模;语言学方面包括字典(词典)构造,语言模型建模等。通过建立的声学模型和语言模型就可以对输入的测试语音进行解码,得到相对应的文字。
解码原理(基于最大后验概率MAP)
假设我们有一段语音
(通常是提取的特征),要得到对应的文本
,就是求使得概率
最大的
的过程,即求
利用条件概率公式和贝叶斯公式将上述公式转化为
表示声学观测序列的概率,不管选择解码空间中的哪一条路径,一段语音发出来后 就确定了,是一个未知的常数,虽然这个概率很难估计,但是并不会影响到 的取值,因此,上式可以简化为
该公式就是解码的核心公式了,下面对该公式做一个简单解读
其中第一项 就是我们的声学模型,准确的说,这个概率可以通过声学模型和词典(Lexicon)计算得到,第二项就是我们的语言模型,该怎么理解呢?
从概率上看, 表示在给定文本 的情况下,求“生成”语音 的概率,就是说,我们之所以说某一句话而不会说其他话,是因为在说这句话之前,脑海里肯定有我们想表达的内容(这里内容就可以理解成文本 ),然后,调动发声器官发出语音 ,因此,语音识别的目标就是通过发出的语音 去猜测说这句话到底表达什么内容 。
而 就是我们的先验概率,为什么这么说,因为它不依赖于我们给定的语音 ,而是由经验得出的,具体的,可以理解为人类发展到现在所总结出来的语法知识,更通俗一点就是人类的表达习惯。举个例子,我们通常会说“上床睡觉”而不会说“上床上班”。这个概率可以由语言模型得到。
要使得 最大,一方面需要文字表达尽量符合语法习惯(即 尽量大),另一方面需要识别出来的文字尽量和发出的语音相符(即 尽量大),就是说,在解码空间里(解码空间后续会说,简单理解为不同词之间有多种组合方式,不同的组合方式构成不同的 ),可能有很多种组合都符合语法习惯,但是有些就和发出的语音不太吻合,例如,我们说一句话“我下班坐地铁回家”,其中有三个不同的识别结果:
1.我下班坐公交回家
2.我坐地铁回家
3.我下班坐地铁回家
显然,上述三种识别结果都符合语法习惯,但是前两种识别结果都存在误识(替换错误,后续会讲)或信息丢失(删除错误,后续会讲),即语音中所表达的信息没有被完全识别出来,因此声学模型的得分 就没有第3种识别结果得分高。
好了,语音识别的介绍就到这里,具体如何对声学模型和语言模型进行建模,以及解码等内容在后续进行介绍。
ps:哪位大神能教我怎样用 把 写到 下面去吗,这样看着好别扭