why?
在tensorflow的ps架构中,ps负责存储模型的参数,worker负责使用训练数据对参数进行更新。默认情况下,tensorflow会把参数按照round-robin的方式放到各个参数服务器(ps)上。例如,模型有5个参数(注意这五个参数都是tensor而非标量),P1,P2, P3, P4, P5,由2个ps(记为ps0和ps1)负责存放,则P1,P3,P5会存放在ps0上,P2,P4会存放在ps1上。显然,如果P1,P3,P5都比P2,P4大,那ps0上存放的参数会远大于ps1。这样在更新参数时,ps0的网络就有可能成为瓶颈。
造成参数分布不均匀的主要原因在于tensorflow在为各个参数分配ps时,只是在参数这个粒度做的,粒度太大。如,参数A的大小为1024*1024,参数B的大小为2*2。在这种情况下,如果不对A和B进行分割,无论如何分配都无法做到均匀。如果把A和B分割成512*1024 + 512*1024和1*2 + 1*2,那在两台ps上就可以均匀分配。
how?
tensorflow提供了对参数进行分割的接口----tf.fixed_size_partitioner:
tf.fixed_size_partitioner(
num_shards,
axis=0
)该接口可以将参数在指定维度(axis)分割成指定份数(num_shards),接口定义在 tensorflow/python/ops/partitioned_variables.py。
要想使用该接口,需要搭配tf.variable_scope:
partitioner = tf.fixed_size_partitioner(num_of_ps, 0)
with tf.variable_scope("conv1", partitioner=partitioner):
W_conv1 = weight_variable([5, 5, 1, 32], "conv1")
b_conv1 = bias_variable([32], "conv1")例如,上面的示例相比于常规的tensorflow代码只增加了tf.fixed_size_partitioner和tf.variable_scope中的partitioner参数,就可以将weight和bias分割成了num_of_ps份。
完整示例代码见附录。
效果
在tensorboard中将参数的分割可视化,可以看到1000大小的参数分成了两个500大小的参数,分别存放在ps0和ps1上。
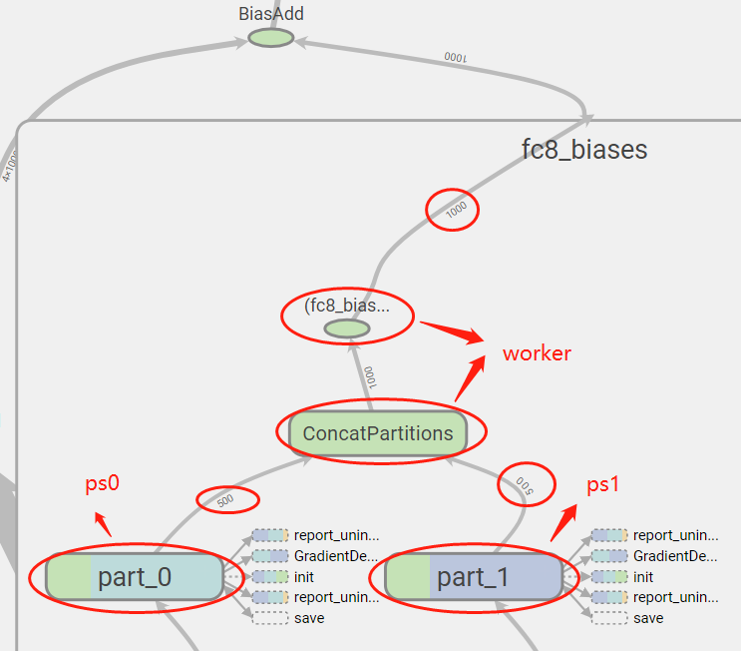
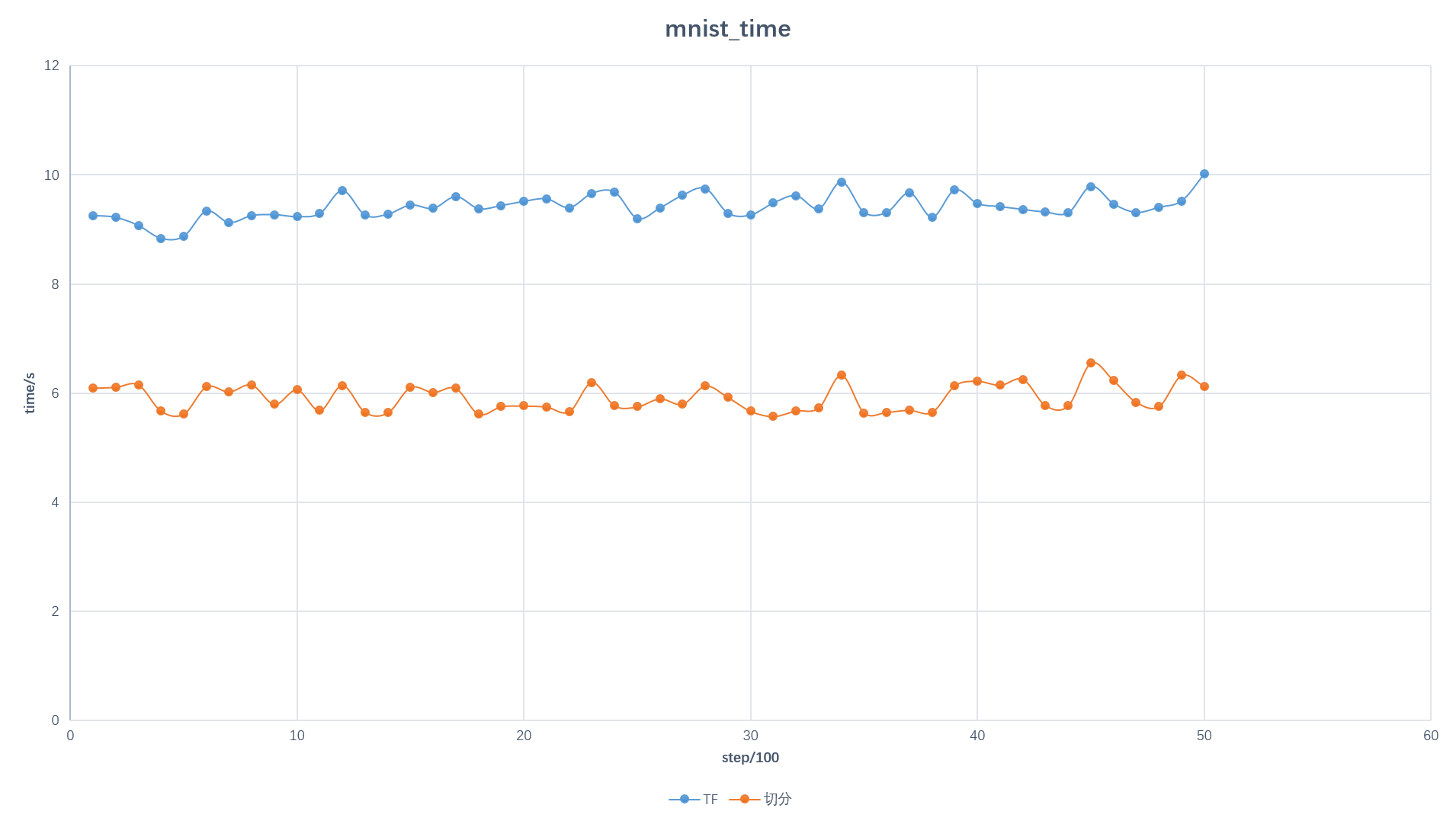
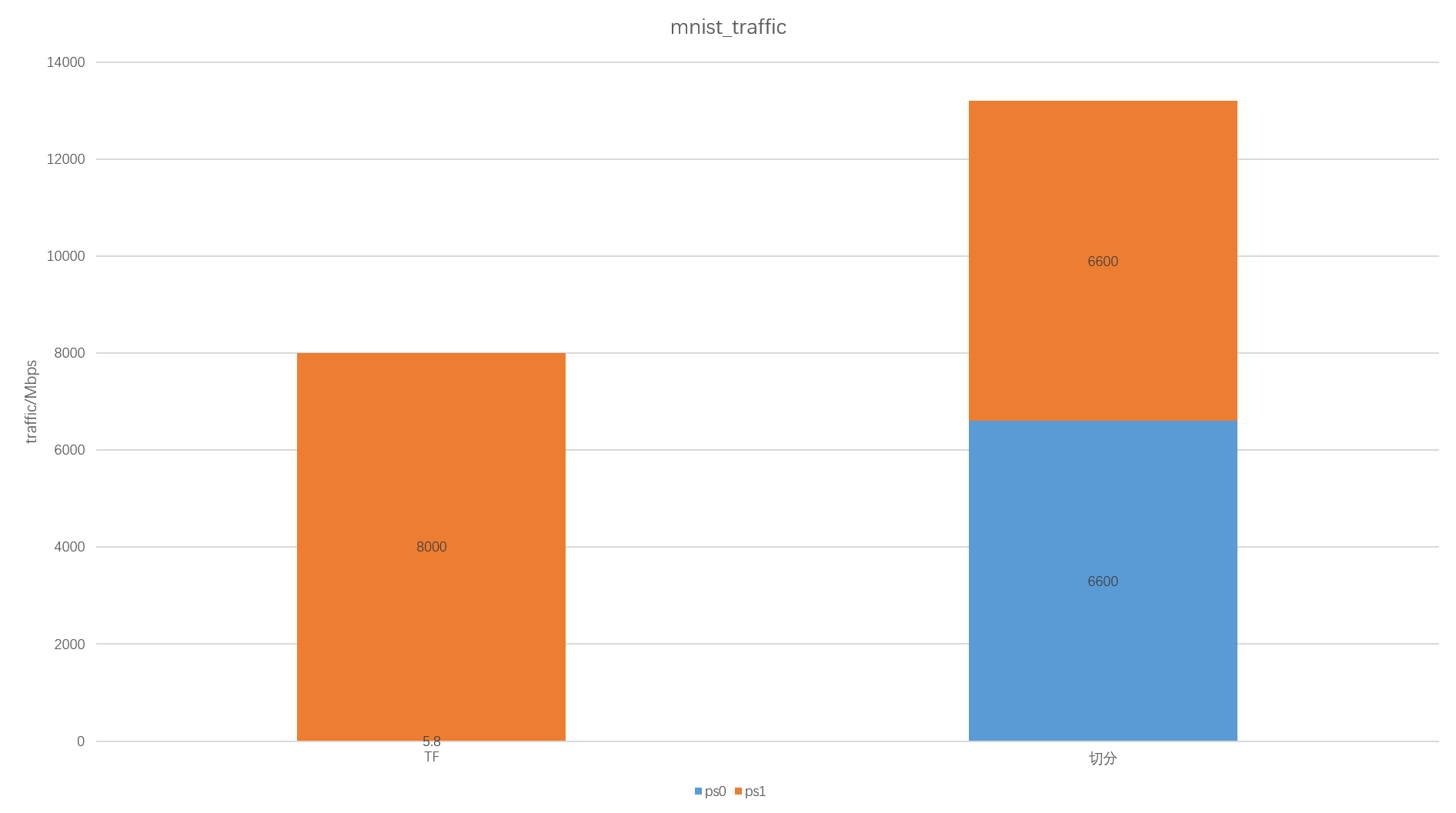
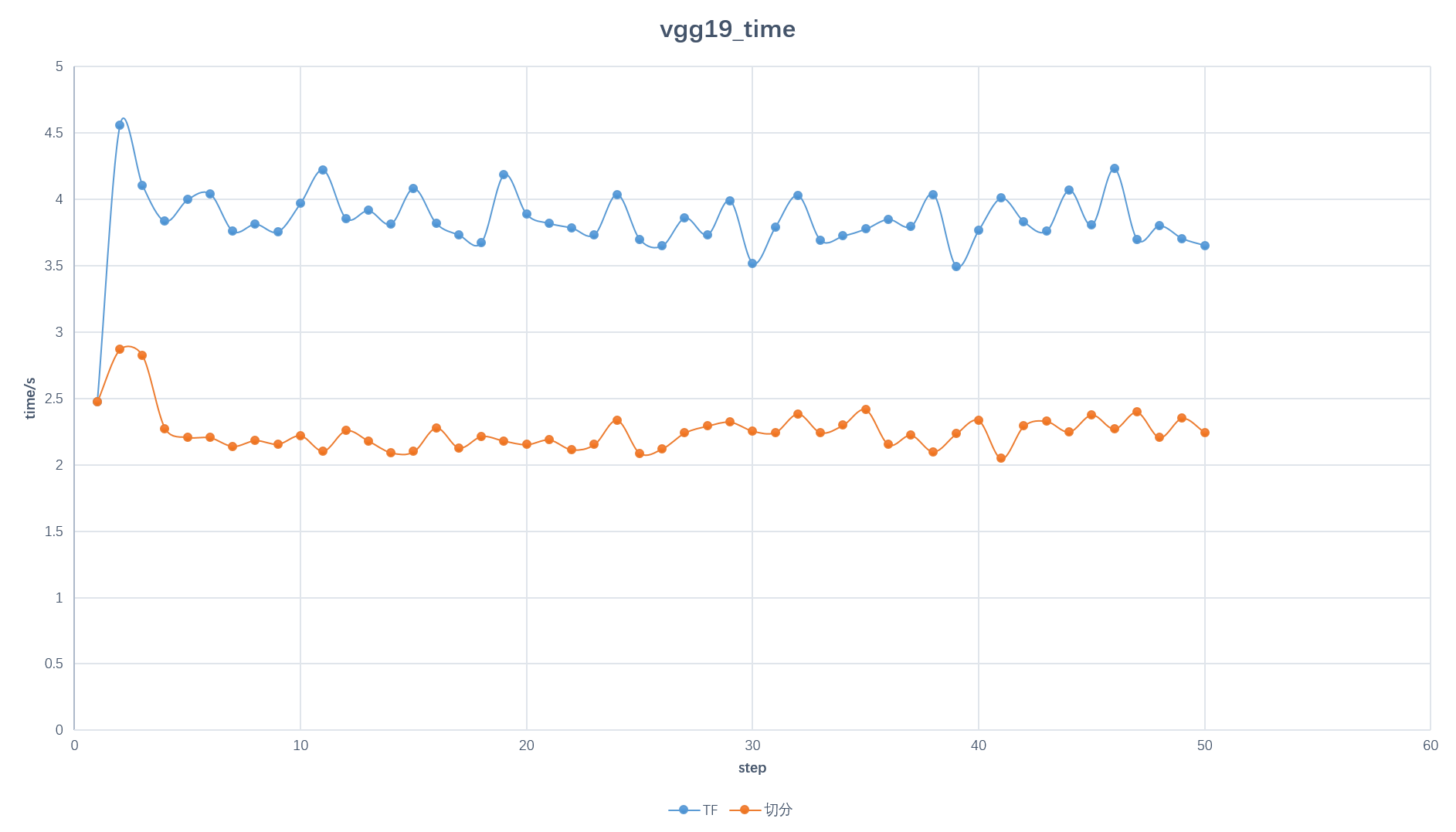
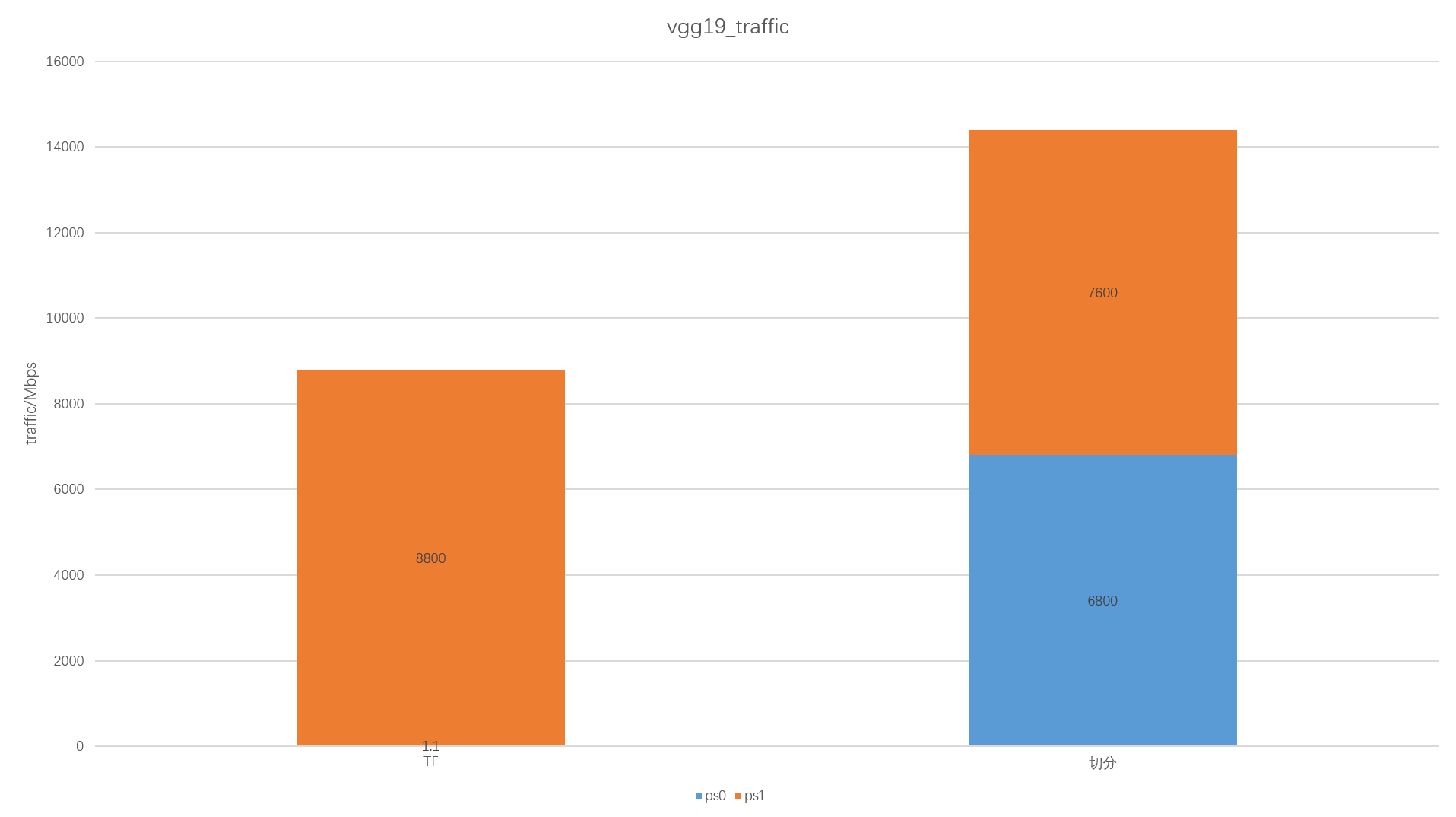
下面以7台worker和2台ps为例,对mnist_cnn和vgg19进行测试,对比分割前后的性能差距。
mnist:
- loss:
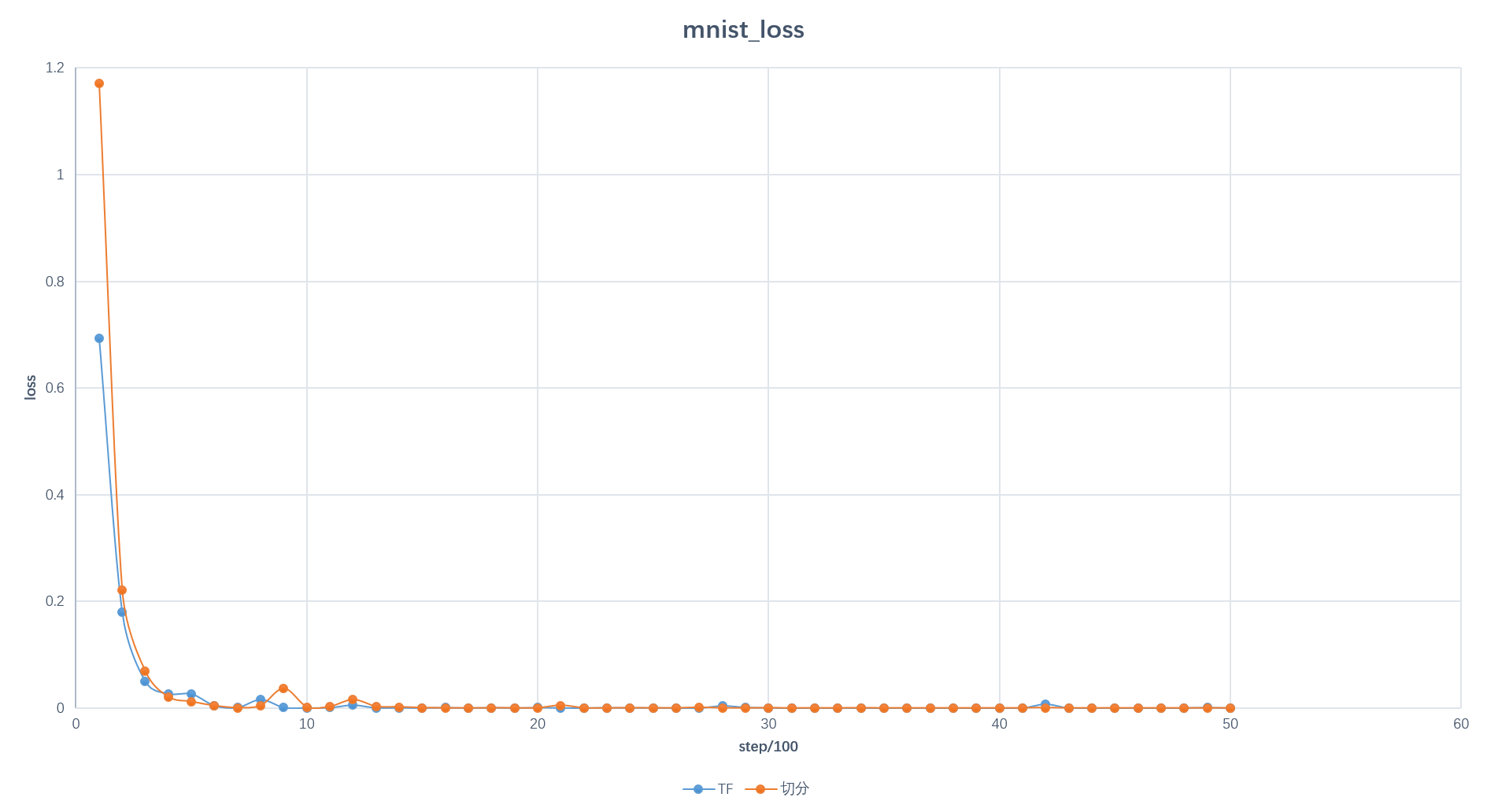
- accuracy:

- 训练时间
- 两台ps的流量:
vgg19:
- 训练时间
- 两台ps的流量:
附录:
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import math
import sys
import re
import tempfile
import time
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
from tensorflow.contrib import layers
import tensorflow.contrib.learn as skflow
flags = tf.app.flags
flags.DEFINE_string("data_dir", "./MNIST_data",
"Directory for storing mnist data")
flags.DEFINE_boolean("download_only", False,
"Only perform downloading of data; Do not proceed to "
"session preparation, model definition or training")
flags.DEFINE_string("job_name", "","One of 'ps' or 'worker'")
flags.DEFINE_string("ps_hosts", "12.12.10.11:7777, 12.12.10.12:7777",
"List of hostname:port for ps jobs."
"This string should be the same on every host!!")
flags.DEFINE_string("worker_hosts", "12.12.10.11:2222",
"List of hostname:port for worker jobs."
"This string should be the same on every host!!")
flags.DEFINE_integer("task_index", None,
"Ps task index or worker task index, should be >= 0. task_index=0 is "
"the master worker task that performs the variable "
"initialization ")
flags.DEFINE_integer("replicas_to_aggregate", None,
"Number of replicas to aggregate before parameter update"
"is applied (For sync_replicas mode only; default: "
"num_workers)")
flags.DEFINE_integer("train_steps", 100000,
"Number of (global) training steps to perform")
flags.DEFINE_integer("batch_size", 128, "Training batch size")
flags.DEFINE_float("learning_rate", 0.01, "Learning rate")
flags.DEFINE_boolean("sync_replicas", True,
"Use the sync_replicas (synchronized replicas) mode, "
"wherein the parameter updates from workers are aggregated "
"before applied to avoid stale gradients")
flags.DEFINE_boolean("allow_soft_placement", True, "True: allow")
flags.DEFINE_boolean("log_device_placement", False, "True: allow")
FLAGS = flags.FLAGS
def deepnn(x):
"""deepnn builds the graph for a deep net for classifying digits.
Args:
x: an input tensor with the dimensions (N_examples, 784), where 784 is the
number of pixels in a standard MNIST image.
Returns:
A tuple (y, keep_prob). y is a tensor of shape (N_examples, 10), with values
equal to the logits of classifying the digit into one of 10 classes (the
digits 0-9). keep_prob is a scalar placeholder for the probability of
dropout.
"""
partitioner = tf.fixed_size_partitioner(num_of_ps, 0)
with tf.variable_scope("reshape", partitioner=partitioner):
x_image = tf.reshape(x, [-1, 28, 28, 1])
# First convolutional layer - maps one grayscale image to 32 feature maps.
with tf.variable_scope("conv1", partitioner=partitioner):
W_conv1 = weight_variable([5, 5, 1, 32], "conv1")
b_conv1 = bias_variable([32], "conv1")
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
# Pooling layer - downsamples by 2X.
with tf.variable_scope("pool1", partitioner=partitioner):
h_pool1 = max_pool_2x2(h_conv1)
# Second convolutional layer -- maps 32 feature maps to 64.
with tf.variable_scope("conv2", partitioner=partitioner):
W_conv2 = weight_variable([5, 5, 32, 64], "conv2")
b_conv2 = bias_variable([64], "conv2")
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
# Second pooling layer.
with tf.variable_scope("pool2", partitioner=partitioner):
h_pool2 = max_pool_2x2(h_conv2)
# Fully connected layer 1 -- after 2 round of downsampling, our 28x28 image
# is down to 7x7x64 feature maps -- maps this to 1024 features.
with tf.variable_scope("fc1", partitioner=partitioner):
W_fc1 = weight_variable([7 * 7 * 64, 1024], "fc1")
b_fc1 = bias_variable([1024], "fc1")
h_pool2_flat = tf.reshape(h_pool2, [-1, 7 * 7 * 64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
# Dropout - controls the complexity of the model, prevents co-adaptation of
# features.
with tf.variable_scope("dropout", partitioner=partitioner):
keep_prob = tf.placeholder(tf.float32)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
# Map the 1024 features to 10 classes, one for each digit
with tf.variable_scope("fc2", partitioner=partitioner):
W_fc2 = weight_variable([1024, 10], "fc2")
b_fc2 = bias_variable([10], "fc2")
y_conv = tf.matmul(h_fc1_drop, W_fc2) + b_fc2
return y_conv, keep_prob
def conv2d(x, W):
"""conv2d returns a 2d convolution layer with full stride."""
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
def max_pool_2x2(x):
"""max_pool_2x2 downsamples a feature map by 2X."""
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1], padding='SAME')
def weight_variable(shape, name):
"""weight_variable generates a weight variable of a given shape."""
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.get_variable(name=name + "_wei", initializer=initial)
def bias_variable(shape, name):
"""bias_variable generates a bias variable of a given shape."""
initial = tf.constant(0.1, shape=shape)
return tf.get_variable(name=name + "_bia", initializer=initial)
def get_device_setter(num_parameter_servers, num_workers):
"""
Get a device setter given number of servers in the cluster.
Given the numbers of parameter servers and workers, construct a device
setter object using ClusterSpec.
Args:
num_parameter_servers: Number of parameter servers
num_workers: Number of workers
Returns:
Device setter object.
"""
ps_hosts = re.findall(r'[\w\.:]+', FLAGS.ps_hosts) # split address
worker_hosts = re.findall(r'[\w\.:]+', FLAGS.worker_hosts) # split address
assert num_parameter_servers == len(ps_hosts)
assert num_workers == len(worker_hosts)
cluster_spec = tf.train.ClusterSpec({"ps":ps_hosts,"worker":worker_hosts})
# Get device setter from the cluster spec #
return tf.train.replica_device_setter(cluster=cluster_spec)
def main(unused_argv):
mnist = input_data.read_data_sets(FLAGS.data_dir, one_hot=False)
if FLAGS.download_only:
sys.exit(0)
ps_hosts = re.findall(r'[\w\.:]+', FLAGS.ps_hosts)
num_parameter_servers = len(ps_hosts)
if num_parameter_servers <= 0:
raise ValueError("Invalid num_parameter_servers value: %d" %
num_parameter_servers)
worker_hosts = re.findall(r'[\w\.:]+', FLAGS.worker_hosts)
num_workers = len(worker_hosts)
if FLAGS.job_name == "worker" and FLAGS.task_index >= num_workers:
raise ValueError("Worker index %d exceeds number of workers %d " %
(FLAGS.task_index, num_workers))
server = tf.train.Server({"ps":ps_hosts,"worker":worker_hosts}, job_name=FLAGS.job_name, task_index=FLAGS.task_index,protocol='grpc')
print("GRPC URL: %s" % server.target)
print("Task index = %d" % FLAGS.task_index)
print("Number of workers = %d" % num_workers)
print("Number of ps = %d" % num_parameter_servers)
print("batch size = %d" % FLAGS.batch_size)
if FLAGS.job_name == "ps":
server.join()
else:
is_chief = (FLAGS.task_index == 0)
if FLAGS.sync_replicas:
if FLAGS.replicas_to_aggregate is None:
replicas_to_aggregate = num_workers
else:
replicas_to_aggregate = FLAGS.replicas_to_aggregate
# Construct device setter object #
device_setter = get_device_setter(num_parameter_servers,
num_workers)
# The device setter will automatically place Variables ops on separate #
# parameter servers (ps). The non-Variable ops will be placed on the workers. #
with tf.device(device_setter):
global_step = tf.Variable(0, name="global_step", trainable=False)
with tf.name_scope('input'):
# input #
image = tf.placeholder(tf.float32, shape=[None, 784], name="x-input")
# label #
label = tf.placeholder(tf.int64, shape=[None], name="y-input")
# Build the graph for the deep net
y_conv, keep_prob = deepnn(image, num_parameter_servers)
cross_entropy = tf.reduce_mean(tf.losses.sparse_softmax_cross_entropy(labels=label, logits=y_conv))
#tf.summary.scalar('cross_entropy', cross_entropy)
print("trainable:")
for var in tf.trainable_variables():
print(var, end="")
print(var.device)
with tf.name_scope('train'):
start_l_rate = 0.001
decay_step = 1000
decay_rate = 0.5
learning_rate = tf.train.exponential_decay(start_l_rate, global_step, decay_step, decay_rate, staircase=False)
optimizer = tf.train.RMSPropOptimizer(learning_rate=learning_rate)
if FLAGS.sync_replicas:
optimizer = tf.train.SyncReplicasOptimizer(optimizer,
replicas_to_aggregate=num_workers,
total_num_replicas=num_workers,
name = "mnist_sync_replicas")
train_op = optimizer.minimize(loss=cross_entropy,
global_step=global_step
)
#tf.summary.scalar('learning_rate', learning_rate)
if FLAGS.sync_replicas and is_chief:
# Initial token and chief queue runners required by the sync_replicas mode #
chief_queue_runner = optimizer.get_chief_queue_runner()
init_tokens_op = optimizer.get_init_tokens_op()
with tf.name_scope('accuracy'):
correct_prediction = tf.equal(tf.argmax(y_conv, 1), label)
correct_prediction = tf.cast(correct_prediction, tf.float32)
accuracy = tf.reduce_mean(correct_prediction)
#tf.summary.scalar('accuracy', accuracy)
merged = tf.summary.merge_all()
init_op = tf.global_variables_initializer()
sv = tf.train.Supervisor(is_chief=is_chief,
init_op=init_op,
recovery_wait_secs=1,
global_step=global_step)
sess_config = tf.ConfigProto(allow_soft_placement=FLAGS.allow_soft_placement,
log_device_placement=FLAGS.log_device_placement,
device_filters=["/job:ps", "/job:worker/task:%d" % FLAGS.task_index])
# The chief worker (task_index==0) session will prepare the session, #
# while the remaining workers will wait for the preparation to complete. #
if is_chief:
print("Worker %d: Initializing session..." % FLAGS.task_index)
else:
print("Worker %d: Waiting for session to be initialized..." % FLAGS.task_index)
sess = sv.prepare_or_wait_for_session(server.target, config=sess_config)
if tf.gfile.Exists('./summary/train'):
tf.gfile.DeleteRecursively('./summary/train')
tf.gfile.MakeDirs('./summary/train')
train_writer = tf.summary.FileWriter('./summary/train', sess.graph)
print("Worker %d: Session initialization complete." % FLAGS.task_index)
if FLAGS.sync_replicas and is_chief:
# Chief worker will start the chief queue runner and call the init op #
print("Starting chief queue runner and running init_tokens_op")
sv.start_queue_runners(sess, [chief_queue_runner])
sess.run(init_tokens_op)
## Perform training ##
time_begin = time.time()
print("Training begins @ %s" % time.ctime(time_begin))
local_step = 1
n_iter_time_begin = time.time()
print("local step global step loss accuracy time")
while True:
# Training feed #
batch_xs, batch_ys = mnist.train.next_batch(FLAGS.batch_size)
train_feed = {image: batch_xs, label: batch_ys, keep_prob: 0.5}
_, step, loss, accur = sess.run([train_op, global_step, cross_entropy, accuracy], feed_dict=train_feed)
now = time.time()
if(local_step % 100 == 0):
n_iter_time_end = time.time()
print(" %5d %5d %.6f %.6f %.6f " %
(local_step, step+1, loss, accur, n_iter_time_end - n_iter_time_begin))
n_iter_time_begin = time.time()
if step+1 >= FLAGS.train_steps:
break
local_step += 1
time_end = time.time()
print("Training ends @ %s" % time.ctime(time_end))
training_time = time_end - time_begin
print("Training elapsed time: %f s" % training_time)
# memory issue occured, split testing data into batch #
acc_acu = 0.
for i in xrange(int(10000/1000)):
test_x, test_y = mnist.test.next_batch(1000)
acc_batch = sess.run(accuracy, feed_dict={image: test_x, label: test_y})
print(acc_batch)
acc_acu += acc_batch
acc = acc_acu/10.0
print ("test accuracy %g" % acc)
#sv.stop()
if __name__ == "__main__":
tf.app.run()