文章转自:https://zhuanlan.zhihu.com/p/35019701
传统神经网络,一般对输入做一个非线性变换H来得到输出output:
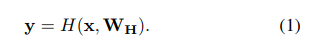
x表示输入,W_H表示权重。
而高速公路网络基于门机制,引入了transform gata T和carry gate C,输出由两个门来控制:
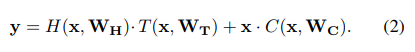
设置C=1-T,公式就变成了:
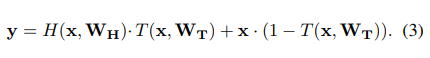
可以看到式子中有点积,所以H(x,W_H),T(x,W_T),x,y的维度是相同的。
特别有:if T(x,W_T)=0:y=x;if T(x,W_T)=1:y=H(x,W_H);

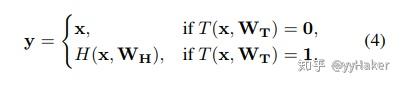
雅克比变换为(也就是对x求导):if T(x,W_T)=0:dy/dx=1;if T(x,W_T)=1:dy/dx=1=H'(x,W_H);
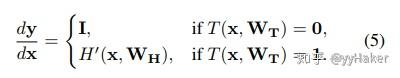
从(4)式就可以看到,高速公路网路其实就是对输入的一部分进行转换,即跟传统神经网络一样,而另一部分则直接通过。在高速公路网络中,引入block的概念(残差块)。计算第i个残差块的输出需要计算和transform gate output
所以,一个block的输出:
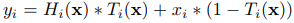
而 transform gate 函数T(x)的计算方法:
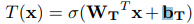
其中,W_T是权值矩阵,b_T是偏移量。
一般设置为负值(例如-1,-3),使得网络初始的时候更偏向carry behavior。还有一个比较有意思的是
, 公式(4)永远都不会是True, 这就使得highway network的behavior介于transform和carry之间。
在实验中还发现将 设置成负值,即是网络层数很深, 用各种各样的方法初始化用不同的激活函数都可以让网络高效的学习。
3. experiment
作者分别训练相同深度的plain network 和 highway network,

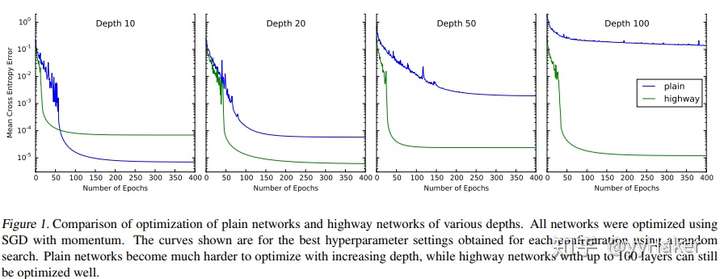
实验发现10层的神经网络plain layer效果好于highway network, 但是随着深度的增加plainnetwork越来越难optimize, 但是highway network到了100层都可以很好的optimize,效果比plain layer刚好,收敛也更快.
为了证明highway network在测试集上的泛化能力, 作者还和fitnet( Romero et al. (2014))作了对比,
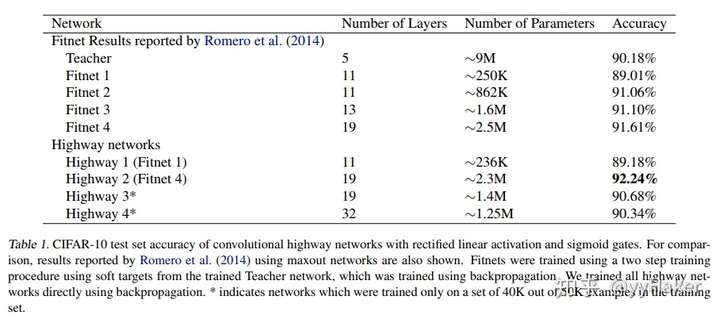
实验发现highway network更容易训练,而且能达到和fitnet相当的效果甚至更好, 而且能够训练thinner and deeper networks, 效果还相当!
作者还用图展示了the best 50 hidden layer的一些数值,

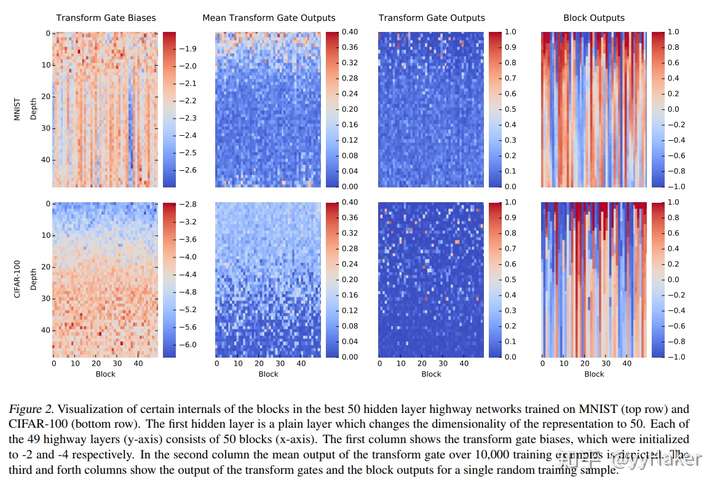

从前两列图可以看出随着层数的增加, bias逐渐增加,mean transform gate output逐渐减少, 这说明浅层的strong negtive bias是让更多的信息直接pass,使得深层网络可以更多的进行处理。

4. conclusion
相比于传统的神经网路随着深度增加训练很难, highway network训练很简单, 使用简单的SGD就可以, 而且即使网络很深甚至到达100层都可以很好的去optimization.
个人认为highway network很大程度借鉴了LSTM的长期短期记忆的门机制的一些思想,使得网络在很深都可以学习!