9.1 正则介绍_grep上 9.2 grep中 9.3 grep下 
9.1 正则介绍_grep上
9.2 grep中
9.3 grep下
扩展
把一个目录下,过滤所有*.php文档中含有eval的行
grep -r --include="*.php" 'eval' /data/
特殊符号
| ###管道符号
命令1 | 命令2
find -type -f |xargs ls -l
find 查找 -type 类型 -f 普通文档 | 管道分隔符 xarge 传递的是把字符串变成了文件名
sed 无非就是查找和替换
. ### 当前目录
.. ### 当前目录的上一级目录
* ### 通配符
> ### 取代 输出重定向 会清空源文件内容 然后再向文件里面追加内容
>> ### 追加 输出重定向 追加到文件的最后一行
< ### 输入重定向 tr xargs
<< ### 追加重定向 cat 用来给文件追加多行文本
'' ### 单引号 ,不具备变量置换功能,输出所见即所得 原样输出
“”## 双引号 ,具有变量置换功能,解析变量输出
`` ### 倒引号 中间是命令 ,会先执行 等价$() /
# ### 注释 root 超级用户提示符
$ ### 变量 取变量里面的内容就是个盒子,取盒子里面的内容
手 鞋盒子 拿出鞋 ==========》取变量里面的内容
awk $取列 $数字
&& ### 前面成功 后面再执行
; ### 分号,多条命令写在同一行
|| ### 前面一个失败 执行后面一个
- ###
~ ### 当前;
/ ### 根 路径分隔符
\ ### 转义 \班长 ===> 学校
? ### 通配符 正则表达式 重复前面一个字符0次或者1次 (.是有且只有一次 )
+ ### 重复前一个字符一次或一次以上 可以取出连续的前一个字符[a-z]
! ### find
[] ### 表示一个整体匹配中括号中任意一个字符 里面代表或者可以是a 也可以是 b 也要c[abc] ls file [678] ls file [0-9]
{} ### 中间为命令区块 组合 或内容序列
.* ### 匹配所有字符 .*^以任意多个字符开头 .*$以任意多个字符结尾
| ### 正则里面表示或者
()### 分组被括起来的东西表示一个整体 (一个字符)
---------
? 0次或1次
* 0次无穷次
+ 1次无穷次
一、 grep
-
正则就是一串有规律的字符串
-
掌握好正则对于编写shell脚本有很大帮助
-
各种编程语言中都有正则,原理是一样的
-
本章将要学习grep/egrep、sed、awk
grep/egrep命令
-
grep命令:过滤出指定关键字的行;
-
格式:grep [参数] ‘字符’ filename
-
grep -n 显示符号要求的行,并显示行号
-
grep -c 打印符合要求的行数
-
grep -v 打印不符合要求的行,取反的意思
-
grep -r 会把目录下的所有文件全部遍历;-r针对的是目录,如果不加-r只能针对文件
-
grep -i 忽略大小写
-
grep -A2 打印符合要求的行以及下面两行
-
grep -B2 打印符合要求的行以及上面两行
-
grep -C2 打印符合要求的行以及上下两行
-
grep -w 匹配一个完整的单词
-
grep -E 特殊符号脱意==egrep
-
centos7中自带 --color显示颜色 ;
-
grep 跟特殊符号的话,要用单引号
-
grep --include 包含
-
grep -l 只打印出含有匹配字符串的文件名,不输出具体匹配行的数据
过滤出包含root字符的行。
[root@linux-151 ~]# grep 'root' test.txtroot:x:0:0:root:/root:/bin/bashoperator:x:11:0:operator:/root:/sbin/nologin
grep –n 过滤出包含root的行,并显示行号;
[root@linux-151 ~]# grep -n 'root' test.txt1:root:x:0:0:root:/root:/bin/bash10:operator:x:11:0:operator:/root:/sbin/nologin
test.txt中包含root字符的一共有几行。
[root@linux-151 ~]# grep -c 'root' test.txt2
过滤出不包含nologin的行;
[root@linux-151 ~]# grep -v 'nologin' test.txtroot:x:0:0:root:/root:/bin/bashsync:x:5:0:sync:/sbin:/bin/syncshutdown:x:6:0:shutdown:/sbin:/sbin/shutdownhalt:x:7:0:halt:/sbin:/sbin/haltlem:x:1000:1000::/home/lem:/bin/bashuser3:x:1004:1003::/home/user3:/sbin/nolonginuser4:x:1005:1003::/home/user4:/sbin/nolonginuser5:x:1007:1006::/home/user5:/bin/loginuser7:x:1009:1009::/home/user7:/bin/bash
grep –i 不区分大小写
[root@linux-151 ~]# grep -i 'biin' test.txtroot:x:0:0:root:/root:/biin/bashBiin:x:1:1:bin:/bin:/sbin/nologinadm:x:3:4:adm:/var/adm:/sBiin/nologinsync:x:5:0:sync:/sbin:/Biin/syncshutdown:x:6:0:shutdown:/sbiin:/sbin/shutdown
[root@linux-151 ~]# grep 'biin' test.txtroot:x:0:0:root:/root:/biin/bashshutdown:x:6:0:shutdown:/sbiin:/sbin/shutdown
grep –A2 打印符合要求的行以及下面两行;
[root@linux-151 ~]# grep -nA2 'root' test.txt1:root:x:0:0:root:/root:/biin/bash2-Biin:x:1:1:bin:/bin:/sbin/nologin3-daemon:x:2:2:daemon:/sbin:/sbin/nologin
--
10:operator:x:11:0:operator:/root:/sbin/nologin11-games:x:12:100:games:/usr/games:/sbin/nologin12-ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
grep –B2 打印符合要求的行以及上面两行;
[root@linux-151 ~]# grep -nB2 'spool' test.txt3-daemon:x:2:2:daemon:/sbin:/sbin/nologin4-adm:x:3:4:adm:/var/adm:/sBiin/nologin5:lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
--
7-shutdown:x:6:0:shutdown:/sbiin:/sbin/shutdown8-halt:x:7:0:halt:/sbin:/sbin/halt9:mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
--
17-polkitd:x:998:996:User for polkitd:/:/sbin/nologin18-tss:x:59:59:Account used by the trousers package to sandbox the tcsd daemon:/dev/null:/sbin/nologin
19:postfix:x:89:89::/var/spool/postfix:/sbin/nologin
grep –C2 打印符合要求的行以及这行上下各两行;
[root@linux-151 ~]# grep -nC2 'halt' test.txt6-sync:x:5:0:sync:/sbin:/Biin/sync7-shutdown:x:6:0:shutdown:/sbiin:/sbin/shutdown8:halt:x:7:0:halt:/sbin:/sbin/halt9-mail:x:8:12:mail:/var/spool/mail:/sbin/nologin10-operator:x:11:0:operator:/root:/sbin/nologin
grep/egrep示例:
-
grep -n 'root' test.txt
-
grep -nv 'nologin' test.txt
-
grep '[0-9]'/etc/inittab
-
grep -v '[0-9]'/etc/inittab
-
grep '[^0-9]' inittab #非0-9 只要不是一个数字 ,方括号里面的反义 取反非的意思
-
grep '^[^0-9]' inittab 重点 #以什么开头 以一个什么字母开头 非数字 外面是开头 里面就是非
-
grep -v '^#' /etc/inittab #号开头的行
-
grep -v '^#' /etc/inittab|grep -v '^$'
-
grep '^[^a-zA-Z]' test.txt #非a-Z 方括号里面的反义 取反非的意思
-
grep 'r.o' test.txt #任意的一个字符
-
grep 'oo*' test.txt
-
grep '0*0' passwd #左边的0开始 0到N次
-
grep '.*' test.txt #匹配所有字符
-
grep 'o{2}' /etc/passwd #o花括号 -
grep -E 'o{2}' passwd #前面一个字符的重复范围 ! o花括号2 代表出现2次o
-
egrep 'o{2}' /etc/passwd #和上面道理一样
-
grep 'o\{2\}' passwd #和上面道理一样
-
egrep 'o+' /etc/passwd
-
grep 'o\+o' passwd #加号表示 +号前面这个字符1次或者多次
-
egrep 'o+o' passwd #和上面一样
-
egrep 'oo?' /etc/passwd
-
grep 'o\?l' passwd #有的时候就是ol 没有的时候就l 表示0个或者1个前面的字符
-
grep 'root\|nologin' passwd # root 或者 nologin \ 拖意
-
egrep 'root|nologin' /etc/passwd # 和上面一样
-
grep 'root\|nologin\|ftp' passwd # 和上面一样 再多一个 或者
-
grep -i 'root\|nologin\|ftp' passwd # 和上面一样 再加了一个不区分大小写
-
egrep '(oo){2}' /etc/passwd #一个组合oo
-
[0-9]:这里的方括号,表示方括号里面的任意一个字符;只要有一个数字,不管是几,就算符合要求。
过滤出包含数字的行 ; grep '[0-9]' test1.txt
[root@linux-151 ~]# grep '[0-9]' test1.txtroot:x:0:0:root:/root:/biin/bash123123Biin:x:1:1:bin:/bin:/sbin/nologindaemon:x:2:2:daemon:/sbin:/sbin/nologinadm:x:3:4:adm:/var/adm:/sBiin/nologinlp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
aaaa1111bbbb
11111111sync:x:5:0:sync:/sbin:/Biin/syncshutdown:x:6:0:shutdown:/sbiin:/sbin/shutdownhalt:x:7:0:halt:/sbin:/sbin/haltmail:x:8:12:mail:/var/spool/mail:/sbin/nologinoperator:x:11:0:operator:/root:/sbin/nologin
过滤出所有不包含数字的行; grep -nv 'nologin' test.txt
[root@linux-151 ~]# grep -nv '[0-9]' test1.txt8:BBBBBBB11:asgfhavkhasd
过滤出不以#开头的行,方便查看某个文件的配置
[root@linux-151 ~]# grep -nv '^#' 2.txt10:dbadfasdfervadsv13:123`123dv15:12312312316:
过滤出不以#或者开头的行不包括空行
[root@linux-151 ~]# grep -v '^#' 2.txt |grep -v '^$'
dbadfasdfervadsv
123`123dv
123123123
过滤出不以字母开头的行
grep '^[^a-zA-Z]' test.txt
[root@linux-151 ~]# grep '^[^a-zA-Z]' test.txt11111111111
!@@@@$$$$$$
111111a22222222
过滤出不包含特殊符号的行
grep -v '^[^a-zA-Z0-9]' 2.txt
[root@linux-151 ~]# grep -v '^[^a-zA-Z0-9]' 2.txt
dbadfasdfervadsv
123`123dv
123123123
正则里面的特殊符号
-
1 . 表示 任意一个字符
-
2 * 表示 零个或多个前面的字符
-
3 .* 表示零个或多个任意字符,空行也包含在内;以r开头o结尾。
-
4 ? 表示0个或者1个前面的字符,使用的时候要\ 脱意一下
-
5 + 表示一个或者多个+前面的字符
-
6 | 在正则表达式里面表示或者,可以写多个,是特殊符号,要使用脱意 或者-E 或者 egrep
-
7 () 括号表示一个整体,{1,3}大括号表示一个范围 ? +(){} |都是特殊符号,要使用必须脱意或者-E 或者egrep
+ * 和的区别 *号0次或者多次 +号没有0次这样说法 1次2次3次
六周第一次课 9.1 正则介绍_grep上 9.2 grep中 9.3 grep下
六周第一次课
9.1 正则介绍_grep上
9.2 grep中
9.3 grep下
扩展
把一个目录下,过滤所有*.php文档中含有eval的行
grep -r --include="*.php" 'eval' /data/
特殊符号
| ###管道符号
命令1 | 命令2
find -type -f |xargs ls -l
find 查找 -type 类型 -f 普通文档 | 管道分隔符 xarge 传递的是把字符串变成了文件名
sed 无非就是查找和替换
. ### 当前目录
.. ### 当前目录的上一级目录
* ### 通配符
> ### 取代 输出重定向 会清空源文件内容 然后再向文件里面追加内容
>> ### 追加 输出重定向 追加到文件的最后一行
< ### 输入重定向 tr xargs
<< ### 追加重定向 cat 用来给文件追加多行文本
'' ### 单引号 ,不具备变量置换功能,输出所见即所得 原样输出
“”## 双引号 ,具有变量置换功能,解析变量输出
`` ### 倒引号 中间是命令 ,会先执行 等价$() /
# ### 注释 root 超级用户提示符
$ ### 变量 取变量里面的内容就是个盒子,取盒子里面的内容
手 鞋盒子 拿出鞋 ==========》取变量里面的内容
awk $取列 $数字
&& ### 前面成功 后面再执行
; ### 分号,多条命令写在同一行
|| ### 前面一个失败 执行后面一个
- ###
~ ### 当前;
/ ### 根 路径分隔符
\ ### 转义 \班长 ===> 学校
? ### 通配符 正则表达式 重复前面一个字符0次或者1次 (.是有且只有一次 )
+ ### 重复前一个字符一次或一次以上 可以取出连续的前一个字符[a-z]
! ### find
[] ### 表示一个整体匹配中括号中任意一个字符 里面代表或者可以是a 也可以是 b 也要c[abc] ls file [678] ls file [0-9]
{} ### 中间为命令区块 组合 或内容序列
.* ### 匹配所有字符 .*^以任意多个字符开头 .*$以任意多个字符结尾
| ### 正则里面表示或者
()### 分组被括起来的东西表示一个整体 (一个字符)
---------
? 0次或1次
* 0次无穷次
+ 1次无穷次
一、 grep
-
正则就是一串有规律的字符串
-
掌握好正则对于编写shell脚本有很大帮助
-
各种编程语言中都有正则,原理是一样的
-
本章将要学习grep/egrep、sed、awk
grep/egrep命令
-
grep命令:过滤出指定关键字的行;
-
格式:grep [参数] ‘字符’ filename
-
grep -n 显示符号要求的行,并显示行号
-
grep -c 打印符合要求的行数
-
grep -v 打印不符合要求的行,取反的意思
-
grep -r 会把目录下的所有文件全部遍历;-r针对的是目录,如果不加-r只能针对文件
-
grep -i 忽略大小写
-
grep -A2 打印符合要求的行以及下面两行
-
grep -B2 打印符合要求的行以及上面两行
-
grep -C2 打印符合要求的行以及上下两行
-
grep -w 匹配一个完整的单词
-
grep -E 特殊符号脱意==egrep
-
centos7中自带 --color显示颜色 ;
-
grep 跟特殊符号的话,要用单引号
-
grep --include 包含
-
grep -l 只打印出含有匹配字符串的文件名,不输出具体匹配行的数据
过滤出包含root字符的行。
[root@linux-151 ~]# grep 'root' test.txtroot:x:0:0:root:/root:/bin/bashoperator:x:11:0:operator:/root:/sbin/nologin
grep –n 过滤出包含root的行,并显示行号;
[root@linux-151 ~]# grep -n 'root' test.txt1:root:x:0:0:root:/root:/bin/bash10:operator:x:11:0:operator:/root:/sbin/nologin
test.txt中包含root字符的一共有几行。
[root@linux-151 ~]# grep -c 'root' test.txt2
过滤出不包含nologin的行;
[root@linux-151 ~]# grep -v 'nologin' test.txtroot:x:0:0:root:/root:/bin/bashsync:x:5:0:sync:/sbin:/bin/syncshutdown:x:6:0:shutdown:/sbin:/sbin/shutdownhalt:x:7:0:halt:/sbin:/sbin/haltlem:x:1000:1000::/home/lem:/bin/bashuser3:x:1004:1003::/home/user3:/sbin/nolonginuser4:x:1005:1003::/home/user4:/sbin/nolonginuser5:x:1007:1006::/home/user5:/bin/loginuser7:x:1009:1009::/home/user7:/bin/bash
grep –i 不区分大小写
[root@linux-151 ~]# grep -i 'biin' test.txtroot:x:0:0:root:/root:/biin/bashBiin:x:1:1:bin:/bin:/sbin/nologinadm:x:3:4:adm:/var/adm:/sBiin/nologinsync:x:5:0:sync:/sbin:/Biin/syncshutdown:x:6:0:shutdown:/sbiin:/sbin/shutdown
[root@linux-151 ~]# grep 'biin' test.txtroot:x:0:0:root:/root:/biin/bashshutdown:x:6:0:shutdown:/sbiin:/sbin/shutdown
grep –A2 打印符合要求的行以及下面两行;
[root@linux-151 ~]# grep -nA2 'root' test.txt1:root:x:0:0:root:/root:/biin/bash2-Biin:x:1:1:bin:/bin:/sbin/nologin3-daemon:x:2:2:daemon:/sbin:/sbin/nologin
--
10:operator:x:11:0:operator:/root:/sbin/nologin11-games:x:12:100:games:/usr/games:/sbin/nologin12-ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
grep –B2 打印符合要求的行以及上面两行;
[root@linux-151 ~]# grep -nB2 'spool' test.txt3-daemon:x:2:2:daemon:/sbin:/sbin/nologin4-adm:x:3:4:adm:/var/adm:/sBiin/nologin5:lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
--
7-shutdown:x:6:0:shutdown:/sbiin:/sbin/shutdown8-halt:x:7:0:halt:/sbin:/sbin/halt9:mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
--
17-polkitd:x:998:996:User for polkitd:/:/sbin/nologin18-tss:x:59:59:Account used by the trousers package to sandbox the tcsd daemon:/dev/null:/sbin/nologin
19:postfix:x:89:89::/var/spool/postfix:/sbin/nologin
grep –C2 打印符合要求的行以及这行上下各两行;
[root@linux-151 ~]# grep -nC2 'halt' test.txt6-sync:x:5:0:sync:/sbin:/Biin/sync7-shutdown:x:6:0:shutdown:/sbiin:/sbin/shutdown8:halt:x:7:0:halt:/sbin:/sbin/halt9-mail:x:8:12:mail:/var/spool/mail:/sbin/nologin10-operator:x:11:0:operator:/root:/sbin/nologin
grep/egrep示例:
-
grep -n 'root' test.txt
-
grep -nv 'nologin' test.txt
-
grep '[0-9]'/etc/inittab
-
grep -v '[0-9]'/etc/inittab
-
grep '[^0-9]' inittab #非0-9 只要不是一个数字 ,方括号里面的反义 取反非的意思
-
grep '^[^0-9]' inittab 重点 #以什么开头 以一个什么字母开头 非数字 外面是开头 里面就是非
-
grep -v '^#' /etc/inittab #号开头的行
-
grep -v '^#' /etc/inittab|grep -v '^$'
-
grep '^[^a-zA-Z]' test.txt #非a-Z 方括号里面的反义 取反非的意思
-
grep 'r.o' test.txt #任意的一个字符
-
grep 'oo*' test.txt
-
grep '0*0' passwd #左边的0开始 0到N次
-
grep '.*' test.txt #匹配所有字符
-
grep 'o{2}' /etc/passwd #o花括号 -
grep -E 'o{2}' passwd #前面一个字符的重复范围 ! o花括号2 代表出现2次o
-
egrep 'o{2}' /etc/passwd #和上面道理一样
-
grep 'o\{2\}' passwd #和上面道理一样
-
egrep 'o+' /etc/passwd
-
grep 'o\+o' passwd #加号表示 +号前面这个字符1次或者多次
-
egrep 'o+o' passwd #和上面一样
-
egrep 'oo?' /etc/passwd
-
grep 'o\?l' passwd #有的时候就是ol 没有的时候就l 表示0个或者1个前面的字符
-
grep 'root\|nologin' passwd # root 或者 nologin \ 拖意
-
egrep 'root|nologin' /etc/passwd # 和上面一样
-
grep 'root\|nologin\|ftp' passwd # 和上面一样 再多一个 或者
-
grep -i 'root\|nologin\|ftp' passwd # 和上面一样 再加了一个不区分大小写
-
egrep '(oo){2}' /etc/passwd #一个组合oo
-
[0-9]:这里的方括号,表示方括号里面的任意一个字符;只要有一个数字,不管是几,就算符合要求。
过滤出包含数字的行 ; grep '[0-9]' test1.txt
[root@linux-151 ~]# grep '[0-9]' test1.txtroot:x:0:0:root:/root:/biin/bash123123Biin:x:1:1:bin:/bin:/sbin/nologindaemon:x:2:2:daemon:/sbin:/sbin/nologinadm:x:3:4:adm:/var/adm:/sBiin/nologinlp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
aaaa1111bbbb
11111111sync:x:5:0:sync:/sbin:/Biin/syncshutdown:x:6:0:shutdown:/sbiin:/sbin/shutdownhalt:x:7:0:halt:/sbin:/sbin/haltmail:x:8:12:mail:/var/spool/mail:/sbin/nologinoperator:x:11:0:operator:/root:/sbin/nologin
过滤出所有不包含数字的行; grep -nv 'nologin' test.txt
[root@linux-151 ~]# grep -nv '[0-9]' test1.txt8:BBBBBBB11:asgfhavkhasd
过滤出不以#开头的行,方便查看某个文件的配置
[root@linux-151 ~]# grep -nv '^#' 2.txt10:dbadfasdfervadsv13:123`123dv15:12312312316:
过滤出不以#或者开头的行不包括空行
[root@linux-151 ~]# grep -v '^#' 2.txt |grep -v '^$'
dbadfasdfervadsv
123`123dv
123123123
过滤出不以字母开头的行
grep '^[^a-zA-Z]' test.txt
[root@linux-151 ~]# grep '^[^a-zA-Z]' test.txt11111111111
!@@@@$$$$$$
111111a22222222
过滤出不包含特殊符号的行
grep -v '^[^a-zA-Z0-9]' 2.txt
[root@linux-151 ~]# grep -v '^[^a-zA-Z0-9]' 2.txt
dbadfasdfervadsv
123`123dv
123123123
正则里面的特殊符号
-
1 . 表示 任意一个字符
-
2 * 表示 零个或多个前面的字符
-
3 .* 表示零个或多个任意字符,空行也包含在内;以r开头o结尾。
-
4 ? 表示0个或者1个前面的字符,使用的时候要\ 脱意一下
-
5 + 表示一个或者多个+前面的字符
-
6 | 在正则表达式里面表示或者,可以写多个,是特殊符号,要使用脱意 或者-E 或者 egrep
-
7 () 括号表示一个整体,{1,3}大括号表示一个范围 ? +(){} |都是特殊符号,要使用必须脱意或者-E 或者egrep
+ * 和的区别 *号0次或者多次 +号没有0次这样说法 1次2次3次
六周第二次课
9.4/9.5 sed
9.4/9.5 sed
grep 是-e sed 是-r
-
sed命令比grep更强大,除了拥有查找功能外,还拥有替换功能
-
sed命令格式:sed -n 'n'p filename ,单引号内的n是数字,表示第几行;
-
sed 可以实现grep的大部分功能 ,但是不显示颜色
-
sed -n 是打印符合条件的行,p是print打印的意思
-
sed -r 脱义(去除特殊符号本身的意义,使其代表特殊意义)
-
sed -e 进行多次命令,和;效果一行
-
sed '/[0-9]'d 2.txt d表示删除不包含数字的行;不是真正的删除,是不显示,相当于grep -v 取反
-
sed -n '/root/'Ip sed I 大I 不区分大小写
-
/定义格式化字符串/
-
sed -i ' [0-9]'d 2.txt -i 是真正删除掉文档里面不包含数字的行;一半不建议使用。
-
正则中 | 表示或者,并且要sed两次表示
-
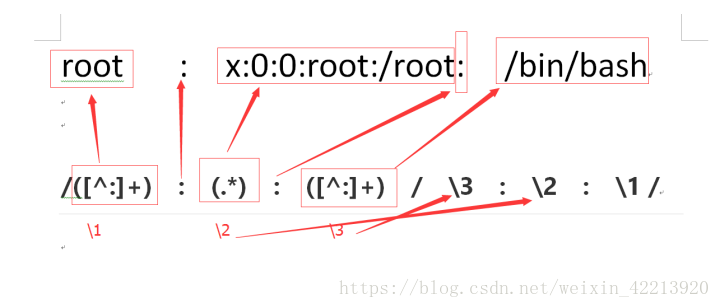
sed -r 's/([^:]+):(.*):([^:]+)/\3:\2:\1/' 1.txt 以:为分割符,将第一段和最后一段互相替换,\1表示第一个()内容,\2表示第二个()内容,\3表示第三个内容。
-
sed -r 's/(.*)/aaa:&/g' 1.txt
sed实例1:
-
sed -n '5'p test.txt #打印第5行
-
sed -n '1,5'p test.txt #打印1到5行
-
sed -n '1,$'p test.txt #打印第1行到末行
-
sed -n '/root/'p sed #匹配root p打印出来 n匹配的行
-
sed -nr '/o+t/'p sed #
-
sed -n '/^1/'p test.txt #打印1 开头的
-
sed -n 'in$'p test.txt
-
sed -n '/r..o/'p test.txt
-
sed -n 'oo*'p test.txt
-
sed -e '1'p -e '/111/'p -n test.txt #-e多次操作 不仅几行打出来还要匹配字符串 ---首先打印第一行sed -e '1'p ,然后匹配111的行也打印出来
查找指定行
-
打印第5行;
[root@linux-151 ~]# sed -n '5'p 1.txtlp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
-
打印第1-5行;
[root@linux-151 ~]# sed -n '1,5'p 1.txtroooot:x:0:0:root:/root:/bin/bashbin:x:1:1:bin:/bin:/sbin/nologindaemon:x:2:2:daemon:/sbin:/sbin/nologinadm:x:3:4:adm:/var/adm:/sbin/nologinlp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
-
打印全部内容可以用(1,$)表示;内容太多,就不显示全部内容。
[root@linux-151 ~]# sed -n '1,$'p 1.txtroooot:x:0:0:root:/root:/bin/bashbin:x:1:1:bin:/bin:/sbin/nologindaemon:x:2:2:daemon:/sbin:/sbin/nologin
…
…
user6:x:1008:1003::/home/wuzhou:/sbin/nologinuser7:x:1009:1009::/home/user7:/bin/bash
查找指定字符串的行
-
查找带有root字符的行;字符要用/ /括起来。
[root@linux-151 ~]# sed -n '/root/'p 1.txtroooot:x:0:0:root:/root:/bin/bash
-
查询的内容也可以是正则;
-
查找以l开头的行
[root@linux-151 ~]# sed -n '/^l/'p 1.txtlp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
-
查找以/login结尾的行;注意:这里需要将/login前面的/脱意一下。
[root@linux-151 ~]# sed -n '/\/login$/'p 1.txtuser5:x:1007:1006::/home/user5:/bin/login
-
查找包含r.o
[root@linux-151 ~]# sed -n '/r.o/'p 1.txtroooot:x:0:0:root:/root:/bin/bashoperator:x:11:0:operator:/rooot:/sbin/nologin
-
打印带有数字的行
[root@linux-151 ~]# cat 3.txt121212
ababab
[root@linux-151 ~]# sed -n '/[0-9]/'p 3.txt121212
-
打印以数字开头的行
[root@linux-151 ~]# sed -n '/^[0-9]/'p 1.txt1111bbaavv
-
sed –e 可以进行多次命令;
[root@linux-151 ~]# sed -e '1'p -e '/111/'p -n 1.txtroooot:x:0:0:root:/root:/bin/bash1111bbaavv
删除某些行
sed实例2:
-
sed '1'd test.txt #删除第一行
-
sed '1,3'd test.txt #删除第1到第3行
-
sed '/oot/'d test.txt
-
sed -i '1,25'd sed # -i 直接修改 删除1-25行
-
sed -i '/aming/'d sed # 直接修改 把aming 相关的行删除
-
删除第1行
[root@linux-151 ~]# cat 3.txt121212
ababab
dfbnsofvas
sdg1wasdf2
!#D@!##!@#
[root@linux-151 ~]# sed '1'd 3.txt
ababab
dfbnsofvas
sdg1wasdf2
!#D@!##!@#
-
删除第1-3行
[root@linux-151 ~]# cat 3.txt121212
ababab
dfbnsofvas
sdg1wasdf2
[root@linux-151 ~]# sed '1,3'd 3.txt
sdg1wasdf2
!#D@!##!@#
-
删除带有ab字符的行
[root@linux-151 ~]# cat 3.txt121212
ababab
dfbnsofvas
sdg1wasdf2
[root@linux-151 ~]# sed '/ab/'d 3.txt121212
dfbnsofvas
sdg1wasdf2
!#D@!##!@#
sed替换功能
-
sed 's/[0-9]/a/g' 1.txt //将所有数字替换成a
-
sed '1,10s/root/toor/g' sed #调换1-10行root换成toorsed '1,10s#root#rooR#g' sed #和上面一样
-
sed 's/root/ROOT/g' 1.txt //将文件1.txt中root全部换成ROOT
-
sed '1,10s/root/ROOT/g' 1.txt //将文件1.txt前10行中root全部替换成ROOT
-
sed 's#[a-zA-Z]##g' # 就文件所有英文替换为空
-
head sed |sed -r 's#(.*)#aaa:&#' #所有行前面加aaa
-
paste 1.txt 2.txt //将1.txt的内容和2.txt内容连在一起
-
sed -i '30,40s/^.*$/#&/g' 1.txt //前面加入加上#注释掉
-
sed -i 's/^/#/g' 1.txt //前面加入加上#注释掉
-
s 是替换的意思,g为全局替换,否者就替换一次,/可以用#@来替换字符
-
-
第2段
-
:(.*): :......: 冒号开头当中不管什么字符但是必须冒号结尾 第2段
-
第1段
-
[^:]: .....: :开头 :结尾
-
第3段
-
[^:]+: 不能冒号开头,文件里面只能数字开头

sed实例3:
-
sed '1,2s/ot/to/g' test.txt
-
sed 's#ot#to#g' test.txt
-
sed 's/[0-9]//g' test.txt
-
sed 's/[a-zA-Z]//g' test.txt
-
sed -r 's/(rot)(.*)(bash)/\3\2\1/' test.txt
-
sed 's/^.*$/123&/' test.txt
-
sed -i 's/ot/to/g' test.txt
-
将1到2行中ot替换成to
[root@linux-151 ~]# head -5 1.txt|sed '1,2s/ot/to/'groooto:x:0:0:roto:/roto:/bin/bashbin:x:1:1:bin:/bin:/sbin/nologindaemon:x:2:2:daemon:/sbin:/sbin/nologinadm:x:3:4:adm:/var/adm:/sbin/nologinlp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
-
/可以用#或者@来替换
[root@linux-151 ~]# head -5 1.txt|sed '1,2s#ot#to#'groooto:x:0:0:roto:/roto:/bin/bashbin:x:1:1:bin:/bin:/sbin/nologindaemon:x:2:2:daemon:/sbin:/sbin/nologinadm:x:3:4:adm:/var/adm:/sbin/nologinlp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
-
将数字全部删除
[root@linux-151 ~]# head -5 1.txt|sed 's/[0-9]//'groooot:x:::root:/root:/bin/bashbin:x:::bin:/bin:/sbin/nologindaemon:x:::daemon:/sbin:/sbin/nologinadm:x:::adm:/var/adm:/sbin/nologinlp:x:::lp:/var/spool/lpd:/sbin/nologin
-
只保留数字
[root@linux-151 ~]# head -5 1.txt|sed 's/[^0-9]//'g0011223447
-
删除所有字母
[root@linux-151 ~]# head -5 1.txt|sed 's/[a-zA-Z]//'g::0:0::/://::1:1::/://::2:2::/://::3:4:://://::4:7::///://
-
以:为分割,将第一段和最后一段调换位置;+ 在里面是特殊符号,要脱意 用 -r
[root@linux-151 ~]# head -5 1.txt|sed -r 's/([^:]+):(.*):([^:]+)/\3:\2:\1/'g
/bin/bash:x:0:0:root:/root:roooot
/sbin/nologin:x:1:1:bin:/bin:bin
/sbin/nologin:x:2:2:daemon:/sbin:daemon
/sbin/nologin:x:3:4:adm:/var/adm:adm
/sbin/nologin:x:4:7:lp:/var/spool/lpd:lp
-
;分号可以进行多次匹配
[root@linux-151 ~]# sed -n '/root/p;/user5/p' 1.txtroooot:x:0:0:root:/root:/bin/bashuser5:x:1007:1006::/home/user5:/bin/login
-
-e 进行多次命令,和;效果一行
[root@linux-151 ~]# sed -n -r -e '/root/'p -e '/user5/'p 1.txtroooot:x:0:0:root:/root:/bin/bashuser5:x:1007:1006::/home/user5:/bin/login
-
在每一行前面加上aaa: &表示前面()的内容
[root@linux-151 ~]# head -5 1.txt|sed -r 's/(.*)/aaa:&/g'aaa:roooot:x:0:0:root:/root:/bin/bashaaa:bin:x:1:1:bin:/bin:/sbin/nologinaaa:daemon:x:2:2:daemon:/sbin:/sbin/nologinaaa:adm:x:3:4:adm:/var/adm:/sbin/nologinaaa:lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
\1 表示前面()的内容
[root@linux-151 ~]# head -5 1.txt|sed -r 's/(.*)/aaa:\1/g'aaa:roooot:x:0:0:root:/root:/bin/bashaaa:bin:x:1:1:bin:/bin:/sbin/nologinaaa:daemon:x:2:2:daemon:/sbin:/sbin/nologinaaa:adm:x:3:4:adm:/var/adm:/sbin/nologinaaa:lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
-
-i 会直接更改文件本身的内容
sed -i 's/^/#/g' 3.txt
[root@linux-151 ~]# sed -i 's/^/#/g' 3.txt
[root@linux-151 ~]# cat 3.txt
#121212#ababab#dfbnsofvas#sdg1wasdf2#!#D@!##!@#
跟阿铭学linux第十四章练习题和知识面扩充
http://ask.apelearn.com/question/5438
六周第三次课
9.6/9.7 awk
扩展
把这里面的所有练习题做一下
http://www.apelearn.com/study_v2/chapter14.html
9.6/9.7 awk
-
awk也是流式编辑器,针对文档中的行和段进行操作 awk可以分为几个部分:
-
匹配字符或者字符串
-
截取文档中的某一段
-
条件操作符
-
数学运算
-
内置变量
-
默认空格和空白字符作为分隔符
awk内置变量
条件操作符
-
awk常用的变量有OFS,NR和NF
-
OFS 是print打印指定分隔符
-
NR 表示行数 可以做为判断条件
-
NF 表示段数 可以做为判断条件
-
== 等于,精确匹配
-
>大于
-
>= 大于等于
-
< 小于
-
<= 小于等于
-
!= 不等于
实例1:
-
head -n2 test.txt|awk -F ':' '{print $1}' # -F 分隔':' 冒号作为分隔符 打印第1端
-
head -n2 test.txt|awk -F ':' '{print $0}' #-F 分隔':' 0 表示所有的段
-
awk '{print $0}' passwd #和cat命令一样
-
awk -F ':' '{print $1,$2,$3,$4}' passwd #-F 分隔':' 冒号作为分隔符 打印第1段 第2 第3 第4段
-
awk -F ':' '{print $1"#"$2"#"$3"#"$4}' #不常用,分隔符变成# 但是#需要加上双引号
-
awk '/oo/' test.txt #匹配oo的行
-
awk -F ':' '$1 ~/oo/' test.txt #精确的匹配第一段带有oo的行 这就是比sed grep 高级的地方可以分段
-
awk -F ':' '/root/ {print $1,$3} /user2/ {print $3,$4}' passwd #匹配root打印1,3段 匹配user2 打印3,4段
-
awk -F ':' '/root|user2/ {print $0}' passwd #匹配root和user2 匹配到打印整行
-
awk -F ':' '$3=="0"' /etc/passwd # 第3端 等于0 匹配出来 必须要== 不然就变变量了A=B了
-
awk -F ':' '$3>="500"' /etc/passwd #加双引号 就不是数字就变奥斯卡马 排序了
-
awk -F ':' '$3>=500' /etc/passwd #第三段 大于等于500
-
awk -F ':' '$7!="/sbin/nologin"' /etc/passwd #第7端不等于/sbin/nologin
-
awk -F ':' '$3<$4' passwd # 第3段和第4段比较
-
awk -F ':' '$3>"5" && $3<"7"' passwd # 第3段 大于5 并且或者 第3段小于7
-
awk -F ':' '$3>1000 || $7=="/sbin/nologin"' passwd #$3大于 1000 或者 $7 等于/sbin/nologin
-
awk -F ':' '{OFS="#"} $3>1000 || $7 ~ /bash/ {print $1,$3,$7}' passwd # OFS 用来指定分隔符号# 第3>1000 并且&7 包换了/bash/ 打印出来 137
-
awk -F ':' '{OFS="#"}{if ($3>500) {print $1,$2,$3,$4}}' passwd #比上面看的懂 意思差不多 OFS指定# 然后第3段大于500 再打印出来 13 7 段
-
awk -F ':' '{print NR ":" $0}' passwd #冒号分割 打印所有行
-
awk -F ':' '{print NF ":" $0}' passwd # 可以显示多少段
-
awk -F ':' 'NR<10 && $1 ~ /root|mail/' passwd # 可以做为判断条件 2个条件一起用 并且$1包换了root | 或者 mail的行
-
-
awk -F ':' '$1="root"' passwd #$1赋值 所有第一个变成root
-
-
awk -F ':' '$1=="root"' passwd #这个就是匹配 匹配root的行


配 符或者字串
匹配root的行
[root@linux-151 ~]# awk '/root/' 1.txtroot:x:0:0:root:/root:/bin/bashoperator:x:11:0:operator:/root:/sbin/nologin
awk可以做到匹配某一段中的某个字符,以:分隔,匹配第一段中带有root的行
[root@linux-151 ~]# awk -F ':' '$1 ~ /root/' 1.txtroot:x:0:0:root:/root:/bin/bash
awk匹配字符可以使用正则
[root@linux-151 ~]# awk '/ooo?/' 1.txtroot:x:0:0:root:/root:/bin/bashlp:x:4:7:lp:/var/spool/lpd:/sbin/nologinmail:x:8:12:mail:/var/spool/mail:/sbin/nologinoperator:x:11:0:operator:/root:/sbin/nologinpostfix:x:89:89::/var/spool/postfix:/sbin/nologin
awk自带脱意功能,grep脱意需要-E或者egrep,sed脱意需要-r选项
[root@linux-151 ~]# awk -F ':' '/oo+/' 1.txtroot:x:0:0:root:/root:/bin/bashlp:x:4:7:lp:/var/spool/lpd:/sbin/nologinmail:x:8:12:mail:/var/spool/mail:/sbin/nologinoperator:x:11:0:operator:/root:/sbin/nologinpostfix:x:89:89::/var/spool/postfix:/sbin/nologin
grep -E
[root@linux-151 ~]# grep -E 'oo+' 1.txtroot:x:0:0:root:/root:/bin/bashlp:x:4:7:lp:/var/spool/lpd:/sbin/nologinmail:x:8:12:mail:/var/spool/mail:/sbin/nologinoperator:x:11:0:operator:/root:/sbin/nologinpostfix:x:89:89::/var/spool/postfix:/sbin/nologin
sed –r
[root@linux-151 ~]# sed -n -r '/oo+/'p 1.txtroot:x:0:0:root:/root:/bin/bashlp:x:4:7:lp:/var/spool/lpd:/sbin/nologinmail:x:8:12:mail:/var/spool/mail:/sbin/nologinoperator:x:11:0:operator:/root:/sbin/nologinpostfix:x:89:89::/var/spool/postfix:/sbin/nologin
截取文档中的某一段
-
awk –F '分隔符' 如果不指定分隔符,默认会以空格或者空白字符分隔。
打印第一段
[root@linux-151 ~]# head -5 1.txt |awk -F ':' '{print $1}'
root
bin
daemon
adm
lp
打印全部内容;$0表示全部内容
[root@linux-151 ~]# head -5 1.txt |awk -F ':' '{print $0}'root:x:0:0:root:/root:/bin/bashbin:x:1:1:bin:/bin:/sbin/nologindaemon:x:2:2:daemon:/sbin:/sbin/nologinadm:x:3:4:adm:/var/adm:/sbin/nologinlp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
打印第1段~第4段
[root@linux-151 ~]# head -5 1.txt |awk -F ':' '{print $1,$2,$3,$4}'
root x 0 0
bin x 1 1
daemon x 2 2
adm x 3 4
lp x 4 7
-
注意:这里打印出来了第1到第4段,但是内容没有分隔符,这里我们加个分隔符,分隔符要以双引号引起来;后面我们会介绍一个变量OFS来进行分隔。
[root@linux-151 ~]# head -5 1.txt |awk -F ':' '{print $1"#"$2"#"$3"#"$4}'
root#x#0#0bin#x#1#1daemon#x#2#2adm#x#3#4lp#x#4#7
-
awk可以支持多个匹配
匹配到root打印第1和第3段,匹配到user打印第1,第3,第4段。
[root@linux-151 ~]# awk -F ':' '/root/{print $1,$3} /user/ {print $1,$3,$4}' 1.txt
root 0operator 11
tss 59 59
user3 1004 1003
user4 1005 1003
user5 1007 1006
user6 1008 1003
user7 1009 1009
-
|在正则里面表示或者
打印出匹配到root或者user的行
[root@linux-151 ~]# awk '/root|bash/' 1.txtroot:x:0:0:root:/root:/bin/bashoperator:x:11:0:operator:/root:/sbin/nologinlem:x:1000:1000::/home/lem:/bin/bashuser7:x:1009:1009::/home/user7:/bin/bash
||也是并且的意思,但是用法还是有一点区别。
[root@linux-151 ~]# awk '/root/||/bash/' 1.txtroot:x:0:0:root:/root:/bin/bashoperator:x:11:0:operator:/root:/sbin/nologinlem:x:1000:1000::/home/lem:/bin/bashuser7:x:1009:1009::/home/user7:/bin/bash
条件操作符
-
== 等于,精确匹配
-
>大于
-
>= 大于等于
-
< 小于
-
<= 小于等于
-
!= 不等于
打印出第3段等于0的行
[root@linux-151 ~]# awk -F ':' '$3=='0'' 1.txt
打印出第3段大于等于500的行
[root@linux-151 ~]# awk -F ':' '$3>='500'' 1.txt
systemd-bus-proxy:x:999:997:systemd Bus Proxy:/:/sbin/nologinpolkitd:x:998:996:User for polkitd:/:/sbin/nologinchrony:x:997:995::/var/lib/chrony:/sbin/nologinlem:x:1000:1000::/home/lem:/bin/bashuser3:x:1004:1003::/home/user3:/sbin/nolonginuser4:x:1005:1003::/home/user4:/sbin/nolonginuser5:x:1007:1006::/home/user5:/bin/loginuser6:x:1008:1003::/home/wuzhou:/sbin/nologinuser7:x:1009:1009::/home/user7:/bin/bash
注意'500'和"500"区别:双引号引起来的500会把它当成字符,会按照阿斯玛排序,单用号引起来的500是数字。
[root@linux-151 ~]# awk -F ':' '$3>="500"' 1.txtshutdown:x:6:0:shutdown:/sbin:/sbin/shutdownhalt:x:7:0:halt:/sbin:/sbin/haltmail:x:8:12:mail:/var/spool/mail:/sbin/nologinnobody:x:99:99:Nobody:/:/sbin/nologin
systemd-bus-proxy:x:999:997:systemd Bus Proxy:/:/sbin/nologindbus:x:81:81:System message bus:/:/sbin/nologinpolkitd:x:998:996:User for polkitd:/:/sbin/nologintss:x:59:59:Account used by the trousers package to sandbox the tcsd daemon:/dev/null:/sbin/nologin
postfix:x:89:89::/var/spool/postfix:/sbin/nologinsshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin
chrony:x:997:995::/var/lib/chrony:/sbin/nologin
打印出第7段不/sbin/nologin的行
[root@linux-151 ~]# awk -F ':' '$7!="/sbin/nologin"' 1.txtroot:x:0:0:root:/root:/bin/bashsync:x:5:0:sync:/sbin:/bin/syncshutdown:x:6:0:shutdown:/sbin:/sbin/shutdownhalt:x:7:0:halt:/sbin:/sbin/haltlem:x:1000:1000::/home/lem:/bin/bashuser3:x:1004:1003::/home/user3:/sbin/nolonginuser4:x:1005:1003::/home/user4:/sbin/nolonginuser5:x:1007:1006::/home/user5:/bin/loginuser7:x:1009:1009::/home/user7:/bin/bash
并且&&和或者||
[root@linux-151 ~]# awk -F ':' '$3>'1000' && $3<'1009'' 1.txtuser3:x:1004:1003::/home/user3:/sbin/nolonginuser4:x:1005:1003::/home/user4:/sbin/nolonginuser5:x:1007:1006::/home/user5:/bin/loginuser6:x:1008:1003::/home/wuzhou:/sbin/nologin
或者||
[root@linux-151 ~]# awk -F ':' '$3>'1000' || $7=="/bin/bash"' 1.txtroot:x:0:0:root:/root:/bin/bashlem:x:1000:1000::/home/lem:/bin/bashuser3:x:1004:1003::/home/user3:/sbin/nolonginuser4:x:1005:1003::/home/user4:/sbin/nolonginuser5:x:1007:1006::/home/user5:/bin/loginuser6:x:1008:1003::/home/lem:/sbin/nologinuser7:x:1009:1009::/home/user7:/bin/bash
两个字段进行运算
[root@linux-151 ~]# awk -F ':' '$3>$4' 1.txtsync:x:5:0:sync:/sbin:/bin/syncshutdown:x:6:0:shutdown:/sbin:/sbin/shutdownhalt:x:7:0:halt:/sbin:/sbin/haltoperator:x:11:0:operator:/root:/sbin/nologin
systemd-bus-proxy:x:999:997:systemd Bus Proxy:/:/sbin/nologinpolkitd:x:998:996:User for polkitd:/:/sbin/nologinchrony:x:997:995::/var/lib/chrony:/sbin/nologinuser3:x:1004:1003::/home/user3:/sbin/nolonginuser4:x:1005:1003::/home/user4:/sbin/nolonginuser5:x:1007:1006::/home/user5:/bin/loginuser6:x:1008:1003::/home/lem:/sbin/nologin
awk内置变量
-
awk常用的变量有OFS,NR和NF
-
OFS 用来指定分隔符号
-
NR 表示行数
-
NF 表示段数
指定#为分隔符
[root@linux-151 ~]# awk -F ':' '{OFS="#"} $3>"5" {print $1,$2,$3,$4}' 1.txt
shutdown#x#6#0halt#x#7#0mail#x#8#12nobody#x#99#99systemd-bus-proxy#x#999#997dbus#x#81#81polkitd#x#998#996tss#x#59#59postfix#x#89#89sshd#x#74#74chrony#x#997#995
用awk打印前5行,并显示行号
[root@linux-151 ~]# head -5 1.txt|awk -F ':' '{print NR":"$0}'1:root:x:0:0:root:/root:/bin/bash2:bin:x:1:1:bin:/bin:/sbin/nologin3:daemon:x:2:2:daemon:/sbin:/sbin/nologin4:adm:x:3:4:adm:/var/adm:/sbin/nologin5:lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
用awk打印20行以后的行,并显示行号
[root@linux-151 ~]# awk -F ':' 'NR>20 {print NR":"$0}' 1.txt21:chrony:x:997:995::/var/lib/chrony:/sbin/nologin22:lem:x:1000:1000::/home/lem:/bin/bash23:user3:x:1004:1003::/home/user3:/sbin/nolongin24:user4:x:1005:1003::/home/user4:/sbin/nolongin25:user5:x:1007:1006::/home/user5:/bin/login26:user6:x:1008:1003::/home/lem:/sbin/nologin27:user7:x:1009:1009::/home/user7:/bin/bash
awk中可以使用if判断
[root@linux-151 ~]# awk -F ':' '{OFS="#"} {if($3>'1000'){print $1,$2,$3}}' 1.txt
user3#x#1004user4#x#1005user5#x#1007user6#x#1008user7#x#1009
awk中的数学运算
-
awk可以更改段值
将第一段全部更改为root
[root@linux-151 ~]# head -5 1.txt|awk -F ':' '$1="root"'
root x 0 0 root /root /bin/bash
root x 1 1 bin /bin /sbin/nologin
root x 2 2 daemon /sbin /sbin/nologin
root x 3 4 adm /var/adm /sbin/nologin
root x 4 7 lp /var/spool/lpd /sbin/nologin
-
awk可以计算某个段的值
求第3段和
[root@linux-151 ~]# awk -F ':' '{(oto=oto+$3)}; END {print oto}' 1.txt9694
打印出第一段是root的行
[root@linux-151 ~]# awk -F ':' '{if ($1=="root") {print $0}}' 1.txtroot:x:0:0:root:/root:/bin/bash