在使用python爬虫爬取数据的时候,经常会遇到一些网站的反爬虫措施,一般就是针对于headers中的User-Agent,如果没有对headers进行设置,User-Agent会声明自己是python脚本,而如果网站有反爬虫的想法的话,必然会拒绝这样的连接。而修改headers可以将自己的爬虫脚本伪装成浏览器的正常访问,来避免这一问题。
以爬取“豆瓣读书新书速递”(https://book.douban.com/latest?icn=index-latestbook-all)为例进行模拟浏览器君:
首先我们点击进入将要爬取的那个网页,然后鼠标右击页面,点击审查元素,将会出现下面的的框架,然后我们点击Network,然后刷新一下页面,便会出现如下图所示的信息了:
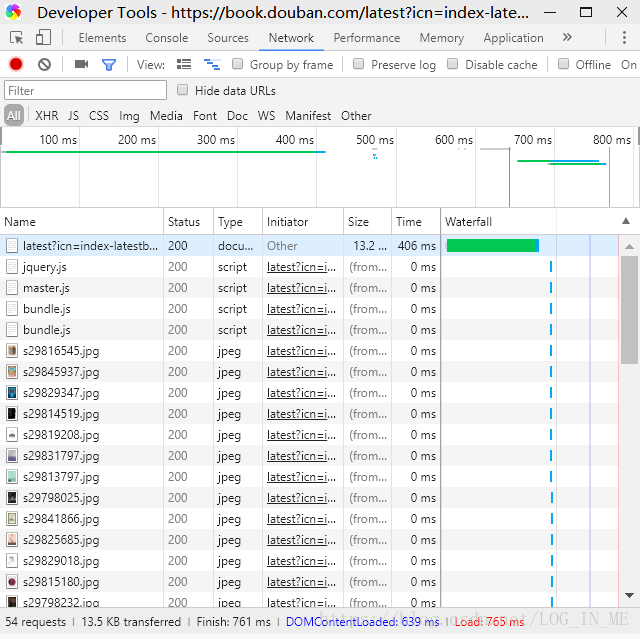
会发现第一行Name名称为我们要爬取网址的标号,点进去,点击上方Headers栏:
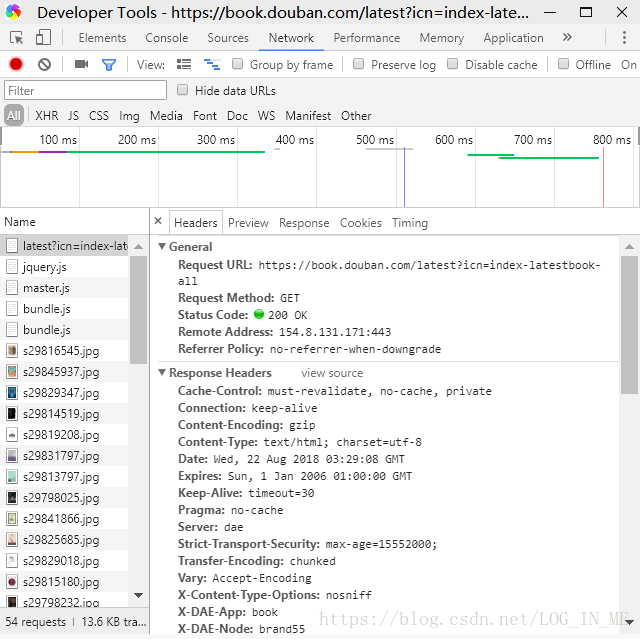
这时我们就可以根据上面的信息模拟浏览器君,在此我就可以设置users-agent,用requests库模拟浏览器君:
import requests
header = {'user-Agent':"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36"}
response = requests.get(url,headers = header)