我曾经用Java代码模拟了Redis的存储和读取,那只是一个功能的简单实现,并没有什么技术含量可言.Redis在如今的互联网应用当中算是起到了一个中流砥柱的作用吧,我姑且这么认知,毕竟在扛并发和缓存方面使用范围比较广,而且集群部署健壮性也是OK的.对于大厂而言可能已经很小儿科,但是对于小型企业而言还是有点帮助的.最近如果有时间准备去看看Memcache,虽然这东西最大存储单槽1MB,Redis是1GB,But Redis是单进程单线程的对于多核CPU而言最多也就占据单个核心而Memcache则不然,多核CPU对其更加有利..但是我没用过Memcache,惭愧啊.希望有时间能模拟一个环境进行压测,获取压力曲线这种第一手资料,再来更加详细总结一下吧.
优势和使用的原因
互联网项目,类似电商、社交、网约车之类的都会面临高并发的一个问题.在解决并发安全问题的基础上必须考虑的就是一个性能问题,这直接影响到用户体验和服务提供的能力上限.通常那些热度比较高的热点会被用户大量访问,比如某国产手机做了个爆款,类似小米之类的一上线发布,会引发很多米粉的关注,PV就这样上去了..一种不假思索的解决方案就是使用缓存.而Redis这种基于内存的NoSQL在执行效率上远胜于MySQL,Oracle之类的基于硬盘的传统关系型数据.而且因为是内存级的所以还能避免直接操作传统数据库带来的链路层延时带来的时间浪费,真是快哉秒哉.
理想很丰满,现实很骨感.
就算是引入了缓存,依然能会存在一些出人意料的情况,而正是这些极端情况带来的风险还是切实威胁着生产环境的.比如缓存雪崩,缓存穿透,缓存击穿.
缓存雪崩:
就和滚雪球一样,雪球越滚越大最后雪崩.比如某些数据没有被成功加载入缓存当中,或者某一时间点大量缓存同时失效,此时如果又有大量的请求进来进行查询而缓存之中没有对应的副本去响应请求,必然的结果就是去查询数据库,直接导致数据库服务器压力过大响应缓慢,或者干脆直接宕机.
如图: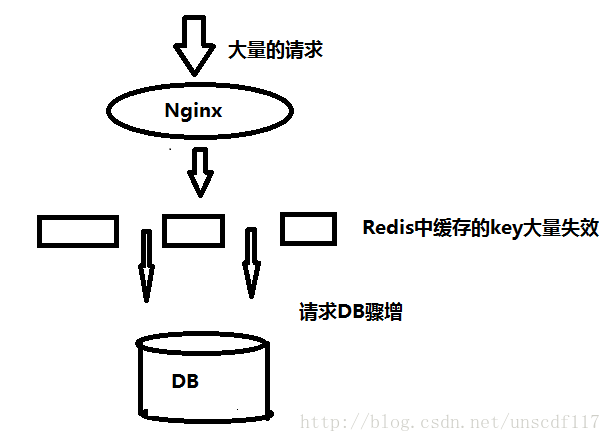
解决之道:最简单的办法就是让key的失效时间不连续,比如expire设置为1分钟失效,可以在后面增加1-20秒的随机数,一定程度上能够解决大面积失效的问题.但是万一命很背,随机数全是一样的,比如都是1秒,仍然会导致雪崩,这个时候就需要在代码中使用到上锁,或者通过Queue来保证缓存通过单线程写入,避免这种情况..这里感谢原阿里P7大佬的点拨,谢谢.
缓存穿透:
当查询一个不存在的数据时,缓存肯定是不会被命中的,而正因为缓存不被命中,所以需要去数据库中查询并且写入缓存.缓存中没有的数据就去数据库查询,如果查询到了就写入缓存同时返回结果给用户,等待下次访问直接走缓存,但是如果查询失败了必然是不会写入缓存中的,那么如果人家频繁操或者说并发量大的情况下(也可能是攻击),DB依然容易宕机.
如图:
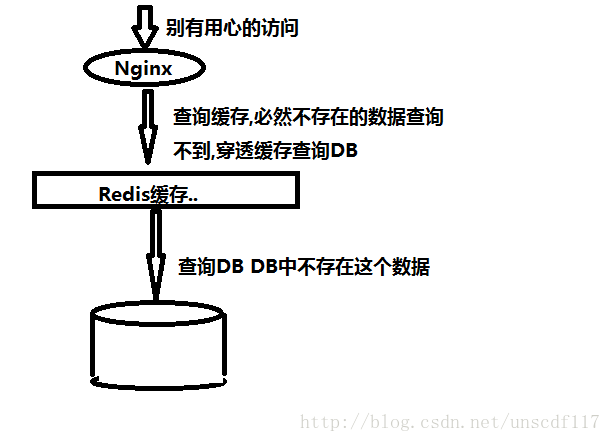
解决之道:在爱品宝跨境商城当中采用的是一种比较原始但是可靠的土方法(我的馊主意),如果一个查询结果为空,照样缓存这个空结果,但是过期时间设置得比较短就30秒.减少数据库服务器压力,把压力转嫁给Redis集群.还有StackOverFlow上的一个老外给出的方法是使用一个BloomFilter,但是很惭愧,这个我并没有过深研究,有时间我会补全 //TODO 研究BloomFilter并且熟悉其原理
缓存击穿:
某一时刻有一个key快要过期了,此时一波洪峰正在路上,key过期以后自然是不存在了的,此时洪峰到了,高并发带来的就是一顿骚操作,所有的人都查询了数据库,并且都往缓存中写..想想也是很可怕的.
如图:
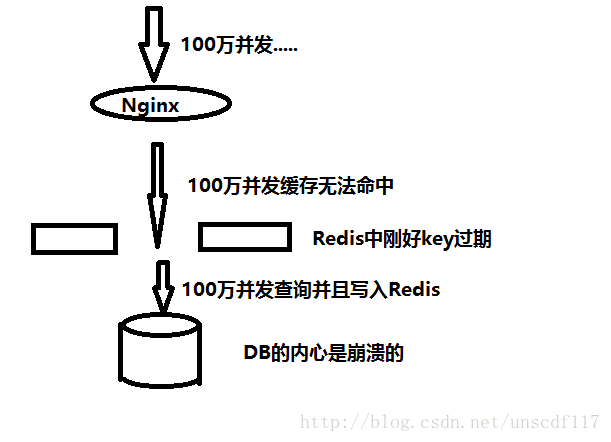
解决之道:使用互斥锁,在缓存失效的时候,查询缓存必然是不命中,先通过Redis的SETNX(Set if not exits)设置一个代表互斥锁的key,例如mutex_lock_key: ,并且给其设置一个较长一点的过期时间(防止查询时间过长其他线程又进来捣乱),一旦这个互斥锁设置成功,再查询数据库,然后写入缓存,否则就重新走以上步骤..
其他好的办法暂时也没想到..//TODO