最近刚好有时间,整理了下List集合相关。
在平常开发中,但凡看到一组数据,我们都习惯尝试用List,似乎List已经无所不能。今天研究List下子类的源码,让我们了解平常使用List时应该注意的地方,提高一定的效率。
开始
首先是关于ArrayList、LinkedList和Vector的继承关系,如下:
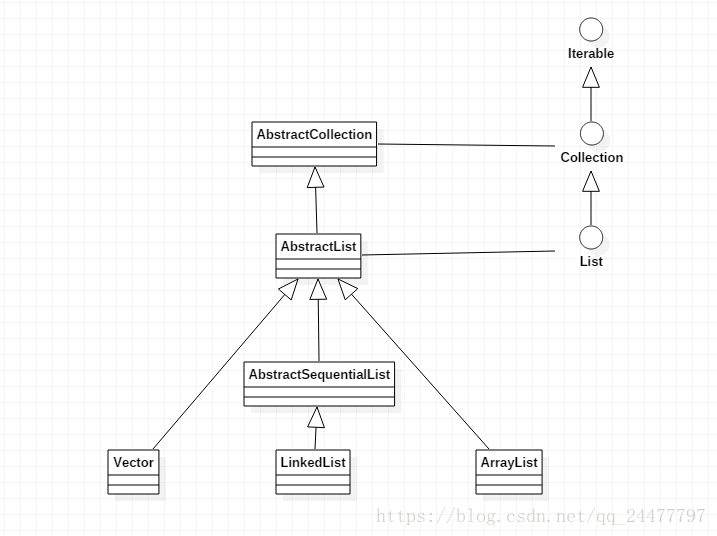
在源码中Vector、LinkedList、ArrayList同时实现了List,但其父类AbstractList已经实现了List,在UML中就不体现了。
先看下ArrayList的源码
构造方法
...
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
...
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}可以看出当我们在Java代码中调用List<String> strList = new ArrayList<>();时,其ArrayList内部是使用了一个长度为0的Object数组来当我们List元素的容器。扩容规则,我们可以看下Add/Remove方法:
Add方法
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
...
private void ensureCapacityInternal(int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
...
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}可以看到当我们在Add元素的时候,ArrayList内部会先对Object数组容器做一次容量判断,确定是否扩容。新的长度 int newCapacity = oldCapacity + (oldCapacity >> 1);右移一位即相当于除以2,所以新长度为之前长度的1.5倍。addAll及add重载的方法都长的差不多,就不重复介绍了。
Remove方法
public E remove(int index) {
if (index >= size)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
modCount++;
E oldValue = (E) elementData[index];
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}remove移除是通过,将要移除位后面的元素全部向前移动一位,再最后一位置为null,最后长度减1。可以看出数组的长度并没有变动,只是将List的Size字段减1。
removeAll和removeXXX等重载方法都差不多,就不多介绍了。
Clear方法
public void clear() {
modCount++;
// clear to let GC do its work
for (int i = 0; i < size; i++)
elementData[i] = null;
size = 0;
}Clear方法是直接将元素置为null,所以在很多复用List的时候,我们可以优先考虑clear,而不是直接重新new一个ArrayList。
再看和ArrayList相近的Vector
之所有相近,是因为Vector的源码和ArrayList基本相同。特别之处在于Vector对于数据操作相关的方法都加上了synchronized方法锁,在平常我们也将Vector称为线程安全的ArrayList。
依次比较上方ArrayList分析的方法:
构造方法:相同的代码就不贴了,Vector有些扩展,多了一个重载的构造方法:
public Vector(int initialCapacity, int capacityIncrement) {
super();
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
this.elementData = new Object[initialCapacity];
this.capacityIncrement = capacityIncrement;
}capacityIncrement在grow时用上,看下面:
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + ((capacityIncrement > 0) ?
capacityIncrement : oldCapacity);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity);
}在相比较ArrayList的时候,newCapacity 规则有点变化,在我们使用Vector独有的构造方法,即capacityIncrement不为0下,数组长度增加量被定死为capacityIncrement,否则增加为之前的2倍,ArrayList是1.5倍,区别倒是不大。
Add方法:
Vector多了addElement方法,和add方法代码相同,只是没有返回值。和ArrayList的add基本类似。
public synchronized boolean add(E e) {
modCount++;
ensureCapacityHelper(elementCount + 1);
elementData[elementCount++] = e;
return true;
}Remove方法:和ArrayList的remove基本类似。
最后LinkedList
构造方法:
构造方法上并没有什么特别的:
...
public LinkedList() {
}
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}
...Add方法:
...
public boolean add(E e) {
linkLast(e);
return true;
}
...
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
...LinkedList同时开放了addFirst和addList方法
public void addFirst(E e) {
linkFirst(e);
}
public void addLast(E e) {
linkLast(e);
}
private void linkFirst(E e) {
final Node<E> f = first;
final Node<E> newNode = new Node<>(null, e, f);
first = newNode;
if (f == null)
last = newNode;
else
f.prev = newNode;
size++;
modCount++;
}看到以上,我们发现,LinkedList就是数据结构中的线性表的概念,具体我们看下Node这个Class:
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}Node含有:一个前驱和一个后继,再加上数据E。
在addLast中,可以看出其操作是将尾节点的后继修改为我们新加入的元素,再把新接入的元素置为尾节点。addFirst同理。
Remove方法:
remove典型的有remove、removeFirst、removeLast方法。
...
public boolean remove(Object o) {
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}
...
public E removeFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return unlinkFirst(f);
}
public E removeLast() {
final Node<E> l = last;
if (l == null)
throw new NoSuchElementException();
return unlinkLast(l);
}
...再看下unlink相关方法:
private E unlinkFirst(Node<E> f) {
// assert f == first && f != null;
final E element = f.item;
final Node<E> next = f.next;
f.item = null;
f.next = null; // help GC
first = next;
if (next == null)
last = null;
else
next.prev = null;
size--;
modCount++;
return element;
}
private E unlinkLast(Node<E> l) {
// assert l == last && l != null;
final E element = l.item;
final Node<E> prev = l.prev;
l.item = null;
l.prev = null; // help GC
last = prev;
if (prev == null)
first = null;
else
prev.next = null;
size--;
modCount++;
return element;
}
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}unlinkFirst和unlinkLast都是unlink的在头部及尾部的简化,我们直接看unlink方法。unlink操作和我们在数据结构中“链表删除一个元素”的概念一模一样,即找到要删除元素的前驱和后继,将前驱所在节点的后继修改为当前元素的后继;将后继所在节点的前驱修改为当前元素的前驱。这样链表就重新完整了。整个删除过程,无需遍历或者动到其它无关的节点,这个也是线性表最大的优势。
总结:
1、在选择List的时候,和之前的认识差不多:对于要求有序、查找要求高的集合,推荐使用ArrayList,当然对于确定长度的,还推荐直接使用数组,毕竟ArrayList也是使用数组来实现的;对于增删频率高的集合,推荐使用LinkedList。
2、从另一个角度理解ArrayList,即对数组进行了合理的封装,支持动态扩容。
3、在考虑到线程安全时,可以使用Vector。
4、在使用ArrayList及Vector时注意数组的长度,在一定情况下,如果知道数组的长度,我们可以在初始化就传入数组长度的参数,减少一定的开销。