原文:https://doc.akka.io/docs/akka/current/guide/introduction.html?language=scala
Akka是一套开放源码库,用于设计可伸缩的、具有弹性的系统,跨越处理器内核和网络。Akka允许您专注于满足业务需求,而不是编写低级别代码来提供可靠的行为、容错和高性能。
许多常见做法和使用的编程模型并不能解决和设计现代计算机体系结构所固有的重要挑战。为了解决那些问题,分布式系统必须应对组件崩溃不能响应,消息丢失时没有轨迹,网络延迟波动。这些问题经常发生在精心管理的数据中心环境中-甚至在虚拟化架构中更是如此。
为了帮助你处理这些现实,Akka提供了:
- 多线程行为,而不使用低级别的并发结构,如原子或锁-减轻了您甚至不考虑内存可见性的问题。
- 系统及其组件之间的透明远程通信-使您不必编写和维护困难的网络代码。
- 一种集群的、高可用性的体系结构,它是弹性的,可以按需向内或向外扩展,使您能够交付一个真正的响应式系统。
Akka对Actor模型的使用提供了一个抽象级别,使得编写正确的并发、并行和分布式系统变得更容易。角色模型跨越了全部Akka库,为您提供了一种理解和使用它们的一致方式。因此,Akka提供了深度的集成,您无法通过挑选库来解决单个问题并尝试将它们组合在一起来实现。
通过学习Akka和如何使用Actor模型,您将获得一组广泛而深入的工具,这些工具可以在统一的编程模型中解决困难的分布式/并行系统问题,在这个模型中,一切都紧密而有效地结合在一起。
How to get started
如果这是您第一次体验Akka,我们建议您从运行一个简单的HelloWorld项目开始。有关下载和运行HelloWorld示例的说明,请参阅QuickStart指南。QuickStart指南向您介绍了如何定义角色系统、角色和消息以及如何使用测试模块和日志记录的示例代码。在30分钟内,您应该能够运行HelloWorld示例并了解它是如何构造的。
本入门指南提供了下一级别的信息。它涵盖了为什么角色模型适合现代分布式系统的需要,并包括一个教程,将帮助您进一步了解Akka。主题包括:
Why modern systems need a new programming model
角色模型是几十年前由卡尔·休伊特(CarlHewitt)提出的,作为在高性能网络中处理并行处理的一种方式-这种环境在当时是不可用的。今天,硬件和基础设施能力已经赶上并超过了休伊特的设想。因此,构建具有严格需求的分布式系统的组织遇到了传统的面向对象编程(OOP)模型无法完全解决的挑战,但它可以从角色模型中受益。
今天,角色模型不仅被认为是一种非常有效的解决方案-它已经在世界上一些最苛刻的应用程序的生产中得到了证明。为了突出角色模型解决的问题,本主题讨论传统编程与现代多线程多CPU体系结构的现实之间的不匹配:
The challenge of encapsulation
OOP的核心支柱是封装。封装规定对象的内部数据不能直接从外部访问;它只能通过调用一组精心设计的方法来修改。该对象负责公开保护其封装数据的不变性质的安全操作。

例如,对有序二叉树实现的操作必须不允许违反树的顺序不变。调用方希望顺序是完整的,并且当查询树以获取特定的数据时,他们需要能够依赖于这个约束。
当我们分析OOP运行时行为时,我们有时会绘制一个显示方法调用交互的消息序列图。例如:

不幸的是,上面的图表不能准确地表示执行过程中实例的生命线。实际上,一个线程执行所有这些调用,执行发生在调用方法的在同一个线程上。用执行线程更新关系图,如下所示:

当您尝试对多线程所发生的情况进行建模时,这种澄清的意义就变得清楚了。突然间,我们画得很整齐的图表变得不够用了。我们可以尝试说明访问同一个实例的多个线程:
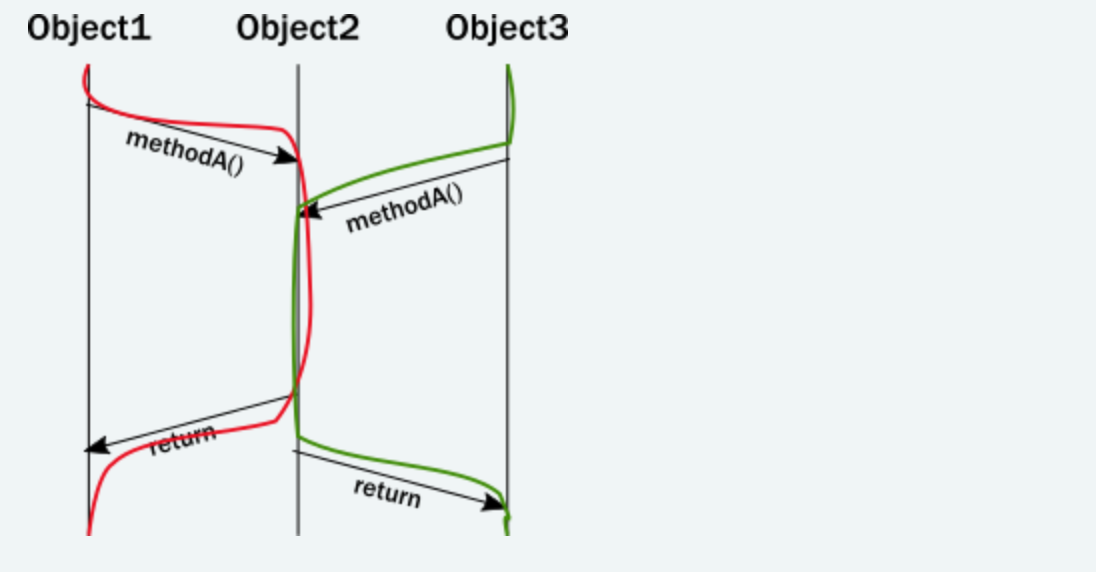
有一段执行,两个线程进入相同的方法。不幸的是,对象的封装模型并不能保证该部分中发生了什么。这两个调用的指令可以任意的方式交织在一起,这就消除了保持变量不变的任何希望,而无需在两个线程之间进行某种类型的协调。现在,想象一下这个问题由于存在许多线程而变得更加复杂。
解决此问题的常见方法是围绕这些方法添加一个锁。虽然这可以确保在任何给定的时间最多有一个线程进入该方法,但这是一种代价很高的策略:
- 锁严重限制了并发性,在现代的cpu体系结构上,它们的代价非常高昂,需要从操作系统中重装线程以挂起线程并在以后恢复它。
- 调用者线程现在被阻塞,因此它不能执行任何其他有意义的工作。即使在桌面应用程序中,这也是不可接受的,即使在运行长时间的后台作业时,我们也希望保持应用程序面向用户的部分(其用户界面)具有响应性。在后端,阻塞是完全浪费的。人们可能认为启动新线程可以弥补这一点,但线程也是一种代价高昂的抽象。
- 锁引入了一个新的威胁:死锁。
这些现实导致了一种不成功的局面:
- 如果没有足够的锁,状态就会损坏。
- 有了许多锁,性能就会受到影响,很容易导致死锁。
此外,锁只能在本地正常工作。当涉及到跨多台计算机进行协调时,唯一的选择是分布式锁。不幸的是,分布式锁的效率比本地锁低几个数量级,并且通常对扩展施加一个硬限制。分布式锁协议需要在多台计算机上通过网络进行多次通信,因此延迟时间过高。
在面向对象语言中,我们通常很少考虑线程或线性执行路径。我们经常设想一个系统是一个对象实例网络,它对方法调用作出反应,修改它们的内部状态,然后通过方法调用相互通信,从而推动整个应用程序状态向前:
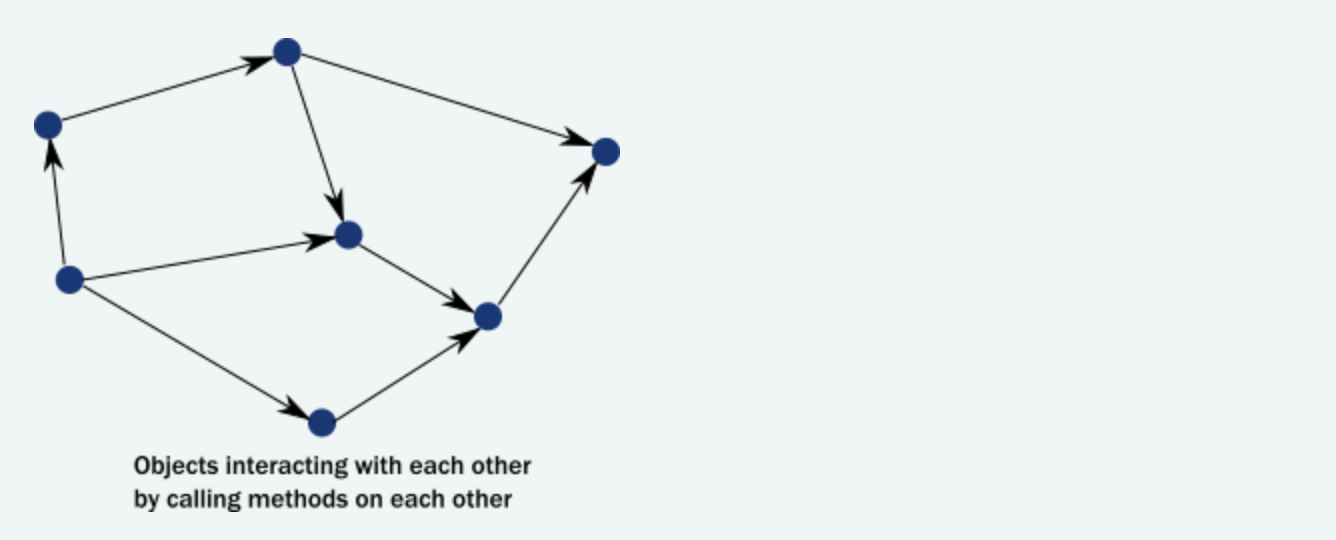
然而,在多线程分布式环境中,实际发生的事情是线程通过以下方法调用“遍历”这个对象实例网络。因此,真正驱动线程执行的是:
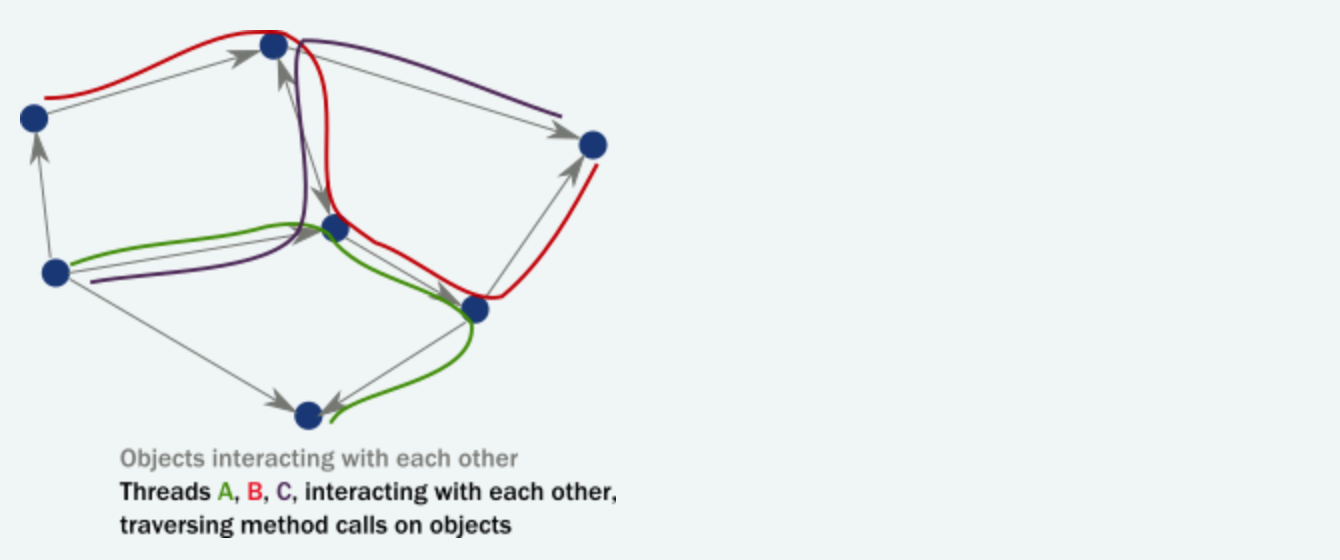
总的来说:
- 对象只能保证封装(保护不变量)在面对单线程访问时,多线程执行几乎总是导致损坏的内部状态。在相同的代码段中有两个争用线程可能会破坏每个不变量。
- 虽然锁似乎是支持多线程封装的自然补救措施,但实际上它们效率低下,在任何实际规模的应用程序中都很容易导致死锁。
- 锁在本地工作,试图使它们分布在本地,但扩展的可能性有限。
现代计算机体系结构中共享内存的错觉
80‘-90年代的编程模型认为写入变量意味着直接写入内存位置(这可能模糊了局部变量可能只存在于寄存器中)。对于现代架构,如果我们简化了一些事情,那么cpu就会编写缓存行而不是直接写内存。大多数缓存都是本地cpu核心,也就是说,一个核心写的都不能被另一个内核所显示。为了使本地更改可见于另一个核心,因此对于另一个线程来说,缓存行需要被发送到其他核心缓存。
在jvm上,我们必须显式地表示通过使用volatile标记或原子包装来跨线程共享的内存位置。否则,我们只能在锁定的部分访问它们。为什么我们不把所有变量标记为volatile?因为传送高速缓存线跨越核心是一个非常昂贵的操作!这样做会隐式地将涉及额外工作所涉及的核心拖放,从而导致缓存一致性协议(协议cpu用于传输主内存和其他cpu之间缓存线)瓶颈。结果是减速幅度。
即使对于了解这种情况的开发人员来说,要确定哪些内存位置应该标记为volatile,或者使用哪些原子结构是一种黑暗艺术。
总的来说:
- 不再存在真正的共享内存,cpu内核就像网络上的计算机一样,通过显式地传递块数据(缓存行)。cpu之间的通信和网络通信比许多实现都更加常见。通过消息传递是当前的标准,它跨越cpu或联网计算机。
- 通过标记为共享或使用原子数据结构的变量来隐藏消息传递方面,更有纪律和有原则的方法是将状态保持到并发实体中,并通过消息显式地传播并发实体之间的数据或事件。
call stacks的错觉
今天,我们经常用call stacks来做理所当然的事。但是,它们是在一个并行编程并不重要,多cpu系统并不常见的时代发明的。call stacks不会跨线程,不模拟异步调用链。
当线程打算将任务委托到“后台”时,会出现问题。实际上,这实际上意味着委托另一个线程。这不能是简单的方法/函数调用,因为调用对线程是严格的本地调用。通常发生的是,调用者将对象放在一个由工作线程共享的内存位置(“被调用者”),反过来,它会在某些事件循环中重新选择它。这样可以让调用方线程继续运行并执行其他任务。
第一个问题是,如何才能通知“caller”完成任务?但是当任务与异常失败时会出现更严重的问题。异常传播到哪里?它可能将传播到工作线程的异常处理程序,完全忽略实际的调用方是谁:

这是一个严重的问题,工作线程如何处理这种情况?它很可能无法解决这个问题,因为它通常忽略了失败任务的目的。需要通知“调用方”线程,但是没有一个调用堆栈以异常解除。故障通知只能通过侧通道来完成,例如,在调用“调用方”线程时,将错误代码放在另一个位置上,否则会预期结果一旦就绪。如果此通知未到位,“调用方”将永远不会通知失败,任务丢失!这与网络系统工作类似,因为在没有任何通知的情况下,消息/请求可以丢失/失败。
当事情发生错误时,这种坏情况会变得更糟,而一个由线程支持的遇到了一个bug,最终会出现无法恢复的状况。例如,由bug引发的内部异常,将其抛到root线程,并使线程关闭。这立即引发了一个问题:谁应该重新启动线程托管服务的正常操作,以及如何恢复到一个已知的状态?乍一看,这似乎是可以控制的,但是我们突然面临一个新的、意想不到的现象:线程当前正在运行的实际任务不再位于任务从(通常是队列)中的共享内存位置。事实上,由于异常到达顶部,解除所有调用堆栈,任务状态完全丢失!尽管这是本地通信,但没有联网(预计消息损失将被预期),我们已经失去了一个消息。
总结:
- 为了在当前系统上实现任何有意义的并发性和性能,线程必须在不阻塞的情况下高效地相互委托任务。对于这种类型的任务委托并发(在网络/分布式计算中更是如此),基于堆栈的调用错误处理中断,需要引入新的显式错误信号机制。失败成为域模型的一部分。
- 具有委托的并发系统需要处理服务错误,并有原则地从错误中恢复。这类服务的客户端需要知道,在重新启动过程中,任务/消息可能会丢失。即使不发生丢失,由于先前排队的任务(长队列)、垃圾收集造成的延迟等原因,响应也可能被任意延迟。面对这些问题,并发系统应该以超时的形式处理响应截止期,就像网络/分布式系统一样。
接下来,让我们看看如何使用角色模型来克服这些挑战。
有什么讨论的内容,可以加我公众号:
