这段时间遇到一系列spark系统重构的需求,每个独立程序在重构之后跑出来的数据都需要和原来程序跑出来的数据进行比对, 已确定重构的代码是否正确。
虽然不需要全量比对,只要抽样几十条数据比对就行,但是由于数据字段很多,即使将新旧两份数据下载到Excel表中,放在一起比对,也是很困难的,而且很容易看漏看错。
我们的数据都是这样的,一般都有几十上百个字段:

于是自己想了一个办法,利用Java的IO读取两个Excel文件,分别将每个文件的每条数据存入LinkedHashMap(按照存入顺序排序),然后将同一个Excel文件的所有数据的map再放入到同一个TreeMap(根据key排序,key设置为表中的字段id+name)中。
以下是代码实现:
package excel;
import java.io.*;
import java.util.*;
import jxl.Sheet;
import jxl.Workbook;
import jxl.read.biff.BiffException;
public class GetExcelInfo {
/**
* 主函数
* @param args
*/
public static void main(String[] args) {
//创建Execl路径C:\Users\BF\Desktop\对数据
File file1 = new File("d:/test1.xls");
File file2 = new File("d:/test2.xls");
//读取两个数据文件
Map set1 = readExcel(file1);
Map set2 = readExcel(file2);
//进行数据比对
isSame(set1,set2);
}
/**
* 读取Excel文件,将每条数据存入一个LinkedHashMap,同一个文件是数据存入一个TreeMap(以id+name为key)
*
* @param file 要读取的目标文件路径
* @return
*/
public static Map readExcel(File file){
Map set = new TreeMap();
try {
//创建输入流,读取Excel
InputStream is = new FileInputStream(file.getAbsolutePath());
//jxl提供的workbook类
Workbook wb = Workbook.getWorkbook(is);
//创建一个sheet对象(标签页为1)
Sheet sheet = wb.getSheet(0);
//sheet.getRows()返回文件的总行数
for(int i = 1;i<sheet.getRows();i++){
Map map = new LinkedHashMap();
//sheet.getColumns()返回该文件的总列数
for(int j=0;j<sheet.getColumns();j++){
//每次读取第一行的字段名作为key,读取每一行的数据作为value
String cellinfoKey = sheet.getCell(j,0).getContents();
String cellinfoValue = sheet.getCell(j,i).getContents();
map.put(cellinfoKey,cellinfoValue);
}
//将id+name作为每条数据的key,存放该条数据的map作为value
set.put(sheet.getCell(0,i).getContents()+"_"+sheet.getCell(1,i).getContents(),map);
}
//打印所有数据
System.out.println(set);
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} catch (BiffException e) {
e.printStackTrace();
}
return set;
}
/**
* 数据比对方法:
* 遍历Map,对两个文件中的数据进行逐个比对,若全部相同,返回true,若不同,返回false
*
* @param m1 第一个数据文件
* @param m2 第二个数据文件
*/
public static void isSame(Map m1,Map m2) {
Boolean flag = true;
Iterator it1 = m1.keySet().iterator();
Iterator it2 = m2.keySet().iterator();
//第一次遍历,将相同的key对应的不同文件中的数据取出来
while (it1.hasNext()) {
while (it2.hasNext()) {
Map mm1 = (Map) m1.get(it1.next());
Map mm2 = (Map) m2.get(it2.next());
Iterator it11 = mm1.keySet().iterator();
Iterator it22 = mm2.keySet().iterator();
//遍历两个文件中的每个字段,进行逐个比对
while (it11.hasNext()) {
while (it22.hasNext()) {
Object key1 = it11.next();
Object key2 = it22.next();
Object re1 = mm1.get(key1);
Object re2 = mm2.get(key2);
if (!re1.equals(re2)) {
System.out.println(key1.toString() + ">>>>>" + re1.toString());
System.out.println(key2.toString() + ">>>>>" + re2.toString());
System.out.println("---------------------------------------------");
flag = false;
}
break;
}
}
break;
}
}
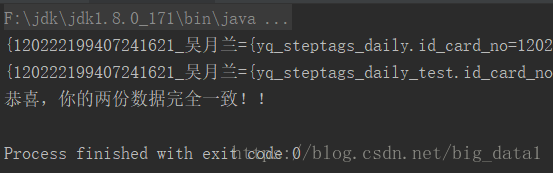
if (flag == true) {
System.out.println("恭喜,你的两份数据完全一致!!");
} else {
System.out.println("不好意思,你的两份数据有不一致的地方,具体差异如上所示。");
}
}
}
运行结果:
温馨提示:
1,我使用的是jxl的方式来读取Excel文件的,需要构建maven工程,引入jxl的jar包。
<!-- jxl -->
<dependency>
<groupId>net.sourceforge.jexcelapi</groupId>
<artifactId>jxl</artifactId>
<version>2.6.12</version>
</dependency>2,jxl的方式来读取Excel文件,这种方式仅仅支持读取.xls文件,不支持读取.xlsx等其他格式文件,否则会报错。

另外补充HashMap,LinkedHashMap和TreeMap的对比:
HashMap
HashMap 是一个最常用的Map,它根据键的HashCode 值存储数据,根据键可以直接获取它的值,具有很快的访问速度。遍历时,取得数据的顺序是完全随机的。
HashMap最多只允许一条记录的键为Null;允许多条记录的值为 Null。
HashMap不支持线程的同步(即任一时刻可以有多个线程同时写HashMap),可能会导致数据的不一致。如果需要同步,可以用 Collections的synchronizedMap方法使HashMap具有同步的能力,或者使用ConcurrentHashMap。
Hashtable与 HashMap类似,它继承自Dictionary类。不同的是:它不允许记录的键或者值为空;它支持线程的同步(即任一时刻只有一个线程能写Hashtable),因此也导致了 Hashtable在写入时会比较慢。
LinkedHashMap
LinkedHashMap保存了记录的插入顺序,在用Iterator遍历LinkedHashMap时,先得到的记录肯定是先插入的。也可以在构造时带参数,按照应用次数排序。
在遍历的时候会比HashMap慢,不过有种情况例外:当HashMap容量很大,实际数据较少时,遍历起来可能会比LinkedHashMap慢。因为LinkedHashMap的遍历速度只和实际数据有关,和容量无关,而HashMap的遍历速度和他的容量有关。
TreeMap
TreeMap实现SortMap接口,能够把它保存的记录根据键排序。
默认是按键值的升序排序,也可以指定排序的比较器,当用Iterator 遍历TreeMap时,得到的记录是排过序的。
总结:
1、一般情况下,我们用的最多的是HashMap。HashMap里面存入的键值对在取出的时候是随机的,它根据键的HashCode值存储数据,根据键可以直接获取它的值,具有很快的访问速度。在Map 中插入、删除和定位元素,HashMap 是最好的选择。
2、TreeMap取出来的是排序后的键值对。但如果您要按自然顺序或自定义顺序遍历键,那么TreeMap会更好。
3、LinkedHashMap 是HashMap的一个子类,如果需要输出的顺序和输入的相同,那么用LinkedHashMap可以实现,它还可以按读取顺序来排列,像连接池中可以应用。