安全攻防基础
一、安全攻防基础(初级)
1. Web 应用的基本构建
- 客戶端 / 服务器架构
- 使用 HTML 描述文件
- 使用 URL 指定文件的所在
- 通过 HTTP 协议与服务器交流
2. HTTP 协议
1. URL 介绍
URL (Uniform / Universal Resource Locato,统一资源定位符 ) 也被称为网页地址,是因特网上标准的资源地址。
URL 的一般形式:
格式:<URL 的访问方式>://<主机>:<端点>/<路径>
如:http://locahost:8080/def.htmlURL 的访问方式:最常用的有三种:ftp,http,news
主机:网站的域名,或 IP,如:locahost
端口:http 固定端口是 80
路径:资源的位置,如 def.html
主机是必须的,端口和路径有时候可以省略
2. HTTP 介绍
HTTP(Hypertext Transfer Protocol,超文本传输协议) 协议是一套计算机通过网络进行通信的规则。
用于从 WWW 服务器传输超文本到本地浏览器的传送协议。
是一个客户端与服务器端请求和应答的标准,客户端是终端用户,服务器端是网站。
HTTP 是一种无状态的协议,无状态是指 Web 浏览器和 Web 服务器之间不需要建立持久的连接,这意味着当一个客户端向服务器端发出请求,然后 Web 服务器返回响应(response),连接就被关闭了,在服务器端不保留连接的有关信息。
HTTP 遵循请求(Request)/应答(Response) 模型,所有 HTTP 连接都被构造成一套请求和应答。
3. HTTP 特点
- 客户/服务器模式:一个服务器可以为分布在世界各地的许多客户服务
- 简单:HTTP本身处理简单,有效地处理大量请求, HTTP 服务器程序规模小,所以经由HTTP的通信速度快,与其它协议相比,时间开销小得多
- 灵活: HTTP允许传输任意类型的数据对象,可以通过Content-type来指定数据类型
- 无状态:HTTP是无状态的协议,缺少状态记忆,运行速度高,服务器应答速度较快
4. HTTP 的工作过程
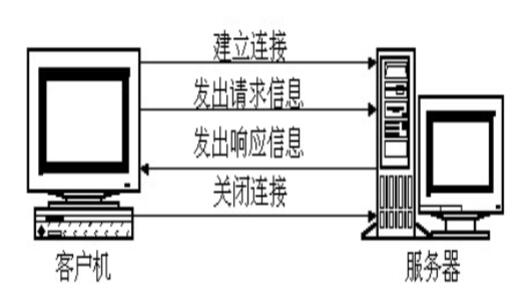
浏览器实现一次 HTTP 连接需要如下步骤:
- 浏览器分析指向页面的 URL
- 浏览器向 DNS 请求解析出域名的 IP 地址
- 浏览器与服务器建立 TCP 连接
- 浏览器发出取文件命令
- 服务器给出响应,将文件发给浏览器
- TCP 连接释放
- 浏览器解析文本
5. HTTP 的事务处理
- 客户端与服务器端建立连接
- 客户端向服务器端发送请求
- 服务器端向客户端回复响应
- 断开连接
6. HTTP 代理服务器
代理服务器是一种网络实体,它能代表浏览器发出 HTTP 请求。
代理服务器将最近的一些请求和响应暂存在本地磁盘中,当与暂时存放的请求相同的新请求到达时,代理服务器就将暂存的响应发送出去,而不需要按 URL 的地址再去因特网访问该资源。
代理服务器可在客户和服务器端工作,也可在中间系统上工作。
7. 代理服务器的工作过程
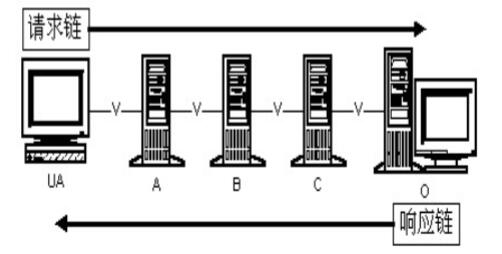
浏览器访问因特网上的服务器的过程是:
- 浏览器访问因特网服务器时,要先与代理服务器建立 TCP 连接,并向代理服务器发出 HTTP 请求报文
- 若代理服务器已经存放了所请求的对象,则将此对象放入 HTTP 响应报文中返回给浏览器。
- 否则,代理服务器就代表发出请求的用户浏览器,与因特网上的服务器建立 TCP 连接,并发送 HTTP 请求报文。
- 因特网服务器将所请求的对象放在 HTTP 响应报文中,通过已建立的 TCP 连接,返回给代理服务器。
代理服务器收到此对象后,先复制在本地存储器中,然后再将该对象放在 HTTP 响应报文中,通过已建立的 TCP 连接返回给请求该对象的浏览器。
其中,代理服务器既作为服务器,也作为客户端。
8. HTTP 的报文结构
HTTP 有两类报文:
- 请求报文
- 响应报文
1. 请求报文
从客户端向服务器发送请求报文
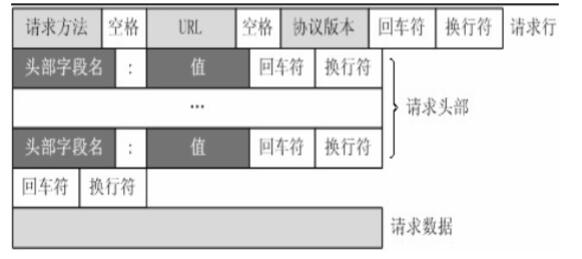
请求行
请求行由请求方法字段、URL 字段和 HTTP 协议版本字段3个字段组成,它们用空格分隔
如:GET /index.html HTTP/1.1HTTP 请求方法
- GET:读取由 URL 所标识的信息
- PUT:在指明的 URL 下存储一个文档
- POST:给服务器添加信息
- HEAD:请求读取 URL 所标识信息的首部
- OPTION: 请求一些选项的信息
- DELETE:删除指明的 URL 所标志的资源
- TRACE: 用来进行环回测试的请求报文
- CONNECT:用于代理服务器
在请求报文中的请求方法区分大小写
URL 字段
路径,如果 URL 中没有给出路径,那么当它作为请求 URI 时,必须以 “ / ” 的形式给出,通常这个工作浏览器自动帮我们完成
- 版本
HTTP 协议目前用的最多的是 1.1 版本
请求头部
请求头部由关键字/值对组成,每行一对,关键字和值用英文冒号 “:” 分隔。请求头部通知服务器有关于客户端请求的信息,典型的请求头有:
- User-Agent:产生请求的浏览器类型
- Accept:请求报头域用于指定客户端接受哪些类型的信息,例如:
- Accept:image/gif,表明客户端希望接受 GIF 图象格式的资源
- Accept:text/html,表明客户端希望接受 html 文本
- Accept-Encoding:编码格式,用于指定可接受的内容编码
- Accept-Language:自然语言,用于指定一种自然语言
- Referer:上一个资源的 URL
- onnection:当值为 Close 时,告诉服务器发送响应的文件后关闭连接;为 Keep-Alive 时,告诉服务器在完成本次请求的响应后,保持连接。
- Host:主要用于指定被请求资源的 Internet 主机和端口号
空行
最后一个请求头之后是一个空行,发送回车符和换行符,通知服务器以下不再有请求头
请求数据
在请求数据的 POST 方法中使用,用于需要客户填写表单的场合
2. 响应报文
从服务器到客户端的回答
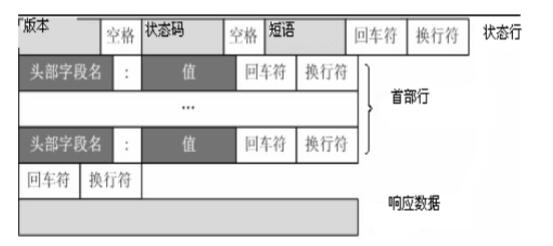
状态行
状态行由当前 HTTP 版本号、3 位数字组成的状态代码以及描述状态的短语
组成,中间用空格隔开
如:HTTP/1.1 200 OK- 版本:常用 HTTP/1.1 版本
- 状态码:表示响应类型有
- 1×× 保留
- 2×× 表示请求成功地接收
- 3×× 为完成请求客户需进一步细化请求
- 4×× 客户错误
- 5×× 服务器错误
- 常见状态描述的短语说明:
- 200 OK //客户端请求成功
- 400 Bad Request //客户端请求有语法错误,不能被服务器所理解
- 401 Unauthorized //请求未经授权
- 403 Forbidden //服务器收到请求,但是拒绝提供服务
- 404 Not Found //请求资源不存在
- 500 Internal Server Error //服务器发生不可预期的错误
- 503 Server Unavailable //服务器当前不能处理客户端的请求
首部行
由关键字/值对组成,每行一对,关键字和值用英文冒号 “:” 分隔。包含了服务器和报文主题的信息,如:
- Location:响应报头域用于重定向接受者到一个新的位置。Location 响应报头域常用在更换域名的时候
- Server:告诉浏览器服务器的名称和版本号
- Content-Encoding:web 服务器告诉浏览器使用了那种压缩方法
- Content-Length:用于指明实体正文的长度,以字节方式存储的十进制数字来表示
- Content-Type:实体报头域用于指明发送给接收者的实体正文的媒体类型
- Last-Modified:实体报头域用于指示资源的最后修改日期和时间
- Connection:告诉浏览器连接状态
空行
最后一个请求头之后是一个空行,发送回车符和换行符, 通知客服端以下是报文实体
响应数据
包含了用户要得到的数据或是错误信息
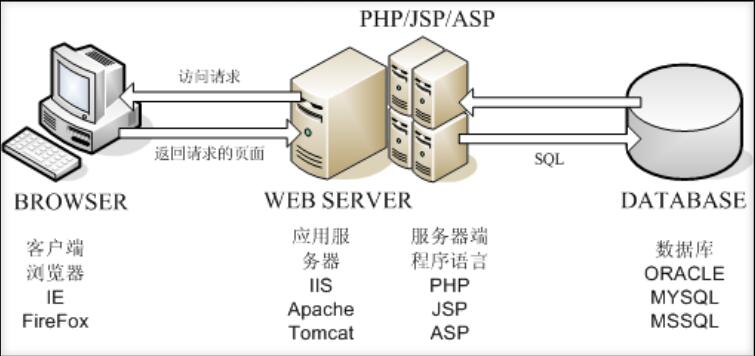
3. 应用系统概述
- 浏览器
- 应用程序
- 数据库
- 服务器软件
4. 网络攻击基本概念术语
1. 网络攻击的方式
- 主动攻击:扫描、渗透、拒绝服务…..
- 被动攻击:嗅探、钓鱼….
2. 网络攻击的过程
- 踩点 —— 信息收集
- 定位 —— 分析目标
- 入侵 —— 实施攻击
- 留后门 —— 方便再次进入
- 抹去痕迹 —— 打扫战场
- 内网渗透 —— 扩大战果
1. 踩点
- 为什么要收集信息
- 获取攻击目标大概信息
- 网络信息
- 主机信息
- 是否存在漏洞
- 密码脆弱性等等
- 指导下一步攻击行为
- 信息收集的方式
- 社会工程学
- 媒体(如搜索引擎、广告介绍等)
- 网络工具的探测
2. 定位
- 为什么需要分析目标
- 确定收集信息的准确性
- 更准确的判断
- 攻击方式及工具路径的选择
- 分析目标的方法
- 扫描
- 漏洞库
- 论坛等交互应用
3. 入侵
- 多种多样的入侵方式
- 针对配置错误的攻击-IPC$ 的攻击
- 针对应用漏洞的攻击-unicode
- 缓存溢出攻击-idq 缓存溢出
- 电子欺骗攻击-ARP 欺骗
- 拒绝服务攻击-syn flood
- 针对弱口令的攻击-口令破解
- 利用服务的漏洞 - 本地输入法漏洞
- 利用应用脚本开发的漏洞 - SQL 注入
- 利用人的心理 -社会工程学攻击
- ……
4. 后门
- 后门可以作什么
- 方便下次直接进入
- 监视用户所有行为、隐私
- 完全控制用户主机
- 后门放置方式
- 如果尚未入侵
- 手动放置
- 利用系统漏洞,远程植入
- 利用系统漏洞,诱骗执行
5. 抹去痕迹
- 改写访问日志
- 例如:IIS 访问日志位置
- 改写日志的技巧:修改系统日期
- 删除中间文件
- 删除创建的用户