题目来源:
1. BP推导。
推导过程见:机器学习 学习笔记(19)神经网络 BP神经网络与Python实现
2. 梯度消失与梯度爆炸:
梯度消失:这本质上是由于激活函数的选择导致的, 最简单的sigmoid函数为例,在函数的两端梯度求导结果非常小(饱和区),导致后向传播过程中由于多次用到激活函数的导数值使得整体的乘积梯度结果变得越来越小,也就出现了梯度消失的现象。
梯度爆炸:同理,出现在激活函数处在激活区,而且权重W过大的情况下。但是梯度爆炸不如梯度消失出现的机会多。
梯度消失问题:见机器学习 学习笔记(22) 深度模型中的优化 参数初始化策略
梯度爆炸问题:见机器学习 学习笔记(22) 深度模型中的优化 悬崖和梯度爆炸
3. 常用的激活函数:
| 激活函数 | 公式 | 缺点 | 优点 |
|---|---|---|---|
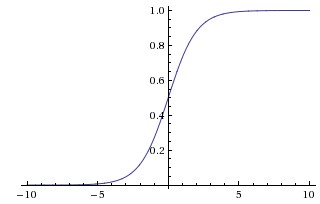
| Sigmoid |
|
1、会有梯度弥散(梯度饱和) 2、不是关于原点对称,权重更新效率低 3、计算exp比较耗时 |
- |
| Tanh(双曲正切函数) | 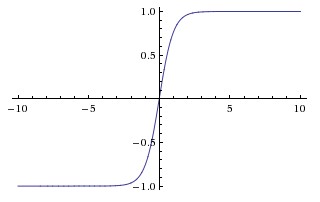 |
梯度弥散没解决 | 1、解决了原点对称问题 2、比sigmoid更快 |
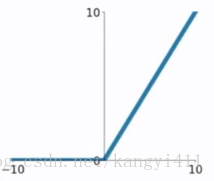
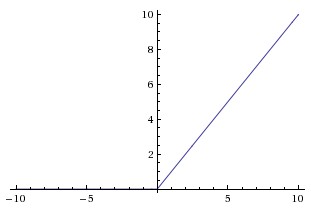
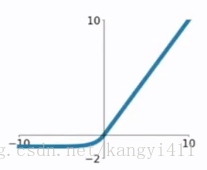
| ReLU(Rectified Linear Unit) |
|
梯度弥散没完全解决,在(-)部分相当于神经元死亡而且不会复活 | 1、解决了部分梯度弥散问题 2、收敛速度更快 |
| Leaky ReLU | - | 解决了神经死亡问题 | |
| Maxout |  |
参数比较多,本质上是在输出结果上又增加了一层 | 克服了ReLU的缺点,比较提倡使用 |
| ELU函数 | |
ELU函数是针对ReLU函数的一个改进型,相比于ReLU函数,在输入为负数的情况下,是有一定的输出的,而且这部分输出还具有一定的抗干扰能力。这样可以消除ReLU死掉的问题, | 有梯度饱和和指数运算的问题 |
| 径向基函数(radial basis function,RBF) | 这个函数在x接近模板 |
因为它对大部分x都饱和到0,因此很难优化。 | |
| softplus函数 | 这是整流线性单元的额平滑版本,引入用于函数近似,和无向概率模型的条件分布。softplus和整流线性单元相比较,后者结果更好, | 通常不鼓励使用softplus函数。softplus表明隐藏单元类型的性能可能是非常反直觉的,因为它处处可到或者因为它不完全饱和。 |
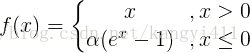
还可参考:几种常用激活函数的简介 以及机器学习 学习笔记(20)深度前馈网络 隐藏单元部分
4. 参数更新方法:
| 方法名称 | 公式 | |
|---|---|---|
| Vanilla update | x += - learning_rate * dx | |
| Momentum update动量更新 | v = mu * v - learning_rate * dx # integrate velocity x += v # integrate position |
|
| Nesterov Momentum | x_ahead = x + mu * v v = mu * v - learning_rate * dx_ahead x += v |
|
| Adagrad (自适应的方法,梯度大的方向学习率越来越小,由快到慢) |
cache += dx**2 x += - learning_rate * dx / (np.sqrt(cache) + eps) |
|
| Adam | m = beta1*m + (1-beta1)dx v = beta2*v + (1-beta2)(dx**2) x += - learning_rate * m / (np.sqrt(v) + eps) |
参考:深度学习之参数优化方法
5. 解决过拟合的方法:
参数范数惩罚:L1正则化、L2正则化、作为约束的范数惩罚
数据集增强、噪声鲁棒性、向输出目标注入噪声
半监督学习
多任务学习
提前终止
参数绑定和参数共享
稀疏表示
Bagging和其他集成方法
dropout:但是要注意dropout只在训练的时候用,让一部分神经元随机失活。
对抗训练
切面距离、正切传播和流形正切分类器
Batch normalization是为了让输出都是单位高斯激活,方法是在连接和激活函数之间加入BatchNorm层,计算每个特征的均值和方差进行规则化。 【深度学习】深入理解Batch Normalization批标准化