Windows
CPU,内存,磁盘,网络,GPU等可以在任务管理器中的性能选项查看。

打开左下角的资源监视器可以具体到每个进程。

Perfmon工具

然后点击性能监视器,然后点击添加按钮,可以添加我们需要跟踪的性能指标。 能添加的参数可以参考下面的参数:
CPU
- Windows -Processor
| 指标名称 | 指标描述 | 指标范围 | 指标单位 |
CPU利用率 (% Processor Time) |
% Processor Time指处理器执行非闲置线程时间的百分比。这个计数器设计成用来作为处理器活动的主要指示器。它通过在每个时间间隔中衡量处理器用于执行闲置处理线程的时间,并且用100%减去该值得出。可将其视为范例间隔用于做有用工作的百分比。 |
根据应用系统情况,在80%±5%范围内波动为宜。过低,则服务器CPU利用率不高;过高,则CPU可能成为系统的处理瓶颈。 |
% |
中断率 (Interrupts/sec.) |
每秒钟设备中断处理器的次数。在完成一个任务或需要注意时,装置会发出中断讯号给处理器。可以产生中断的装置包括系统定时器、鼠标、数据通讯联机、网络卡以及其它的外部装置。在中断过程中,一般的执行绪执行将被暂停,而且一个中断可以使处理器切换到另一个具有较高优先等级的执行绪。频率中断是频繁和周期性的,并且中断动作在背景执行。 |
取决于处理器,越低越好;不宜超过1,000; 如果该值显著增加而系统活动没有相应的增加,则表明存在硬件问题,需要检查引起中断的网络适配器、磁盘或其他硬件。 |
次/sec |
系统调用率 System Call/sec. |
指运行在计算机上的所有处理器调用操作系统服务例行程序的综合速率。这些例行程序执行所有在计算机上的如安排和同步活动等基本的程序,并提供对非图形设备、内存管理和名称空间管理的访问。 |
如果Interrupts/sec大于System Calls/sec.,则系统中某一硬件设备产生过多的中断。 |
次/sec |
Processor Queue Length |
处理器队列的线程数量。此计数器只显示就绪线程,而不是正在运行的线程。 |
如果处理器队列中总是有两个以上的线程通常表示处理器堵塞。 |
|
进程切换率 Context Switches/sec |
指计算机上的所有处理器全都从一个线程转换到另一个线程的综合速率。当正在运行的线程自动放弃处理器时出现上下文转换,由一个有更高优先就绪的线程占先或在用户模式和特权 (内核) 模式之间转换以使用执行或分系统服务 |
如果此计数器的数值较大,则表明锁定竞争很激烈,或者线程在用户和内核模式之间频繁切换。 |
PS:
-
Processor/% Processor Time
阀值:处理器的阀值一般设为85%。
含义:这个计数器是处理器活动的主要指标。高数值并不一定是坏事,但是如果其他处理器相关的计数器(比如% Privileged Time 或者Processor Queue Length)线性增加的话,高CPU使用率就值得调查了。 -
Processor/% Privileged Time
阀值:如果数值持续大于75%就表示存在瓶颈。
含义:这个计数器表示一个线程在特权模式下所使用的时间比例。当你的程序调用操作系统的方法(比如文件操作,网络I/O或者分配内存),这些操作系统的方法是在特权模式下运行的。 -
Processor/% Interrupt Time
阀值:取决于处理器
含义:这个计数器表示处理器接收处理硬件中断所使用的时间比例。这个值间接指出产生中断的硬件设备活动,比如网络变化。这个计数器显著增加的话表示硬件可能存在问题。 -
System/Processor Queue Length
阀值:平均值持续大于2那么表示CPU存在瓶颈
含义:如果就绪的任务超过处理能力线程就会被放进队列。处理器队列是就绪但是未能被处理器执行的线程的集合,这是因为另外一个线程正在执行状态。持续或者反复发生2个以上的队列则明确的表示存在处理器瓶颈。你也能通过减少并发取得更大的吞吐量。
你可以结合Processor/% Processor Time来决定增加CPU的话你的程序是否能够受益。即使在多处理器的电脑上,对于CPU时间也是单队列。因此,在多处理器电脑上,Processor Queue Length (PQL)的值除以用来处理负载的CPU个数。
如果CPU非常忙(90%以上的使用率),PQL的平均值也持续大于2/CPU,这是应该存在CPU瓶颈而且能够从更多的CPU中受益。或者,你可以减少线程的数量以及增加应用程序层的队列。这会引起少量的Context Switching,但是少许的Context Switching对于减少CPU负载是有好处的。PQL大于2但是CPU使用率却不高的的常见原因是对CPU时间的请求随机到达而且线程却从处理器申请到不对称的CPU时间。这意味着处理器并不是瓶颈,而你的线程逻辑是需要改进的。 - System/Context Switches/sec
阀值:按照通常的规律,context switching速率小于5000/秒/CPU是不需要担心的。如果Context Switching速率达到15000/秒/CPU的话就是一个制约因素了。
含义:当一个高优先级的线程取代一个正在运行的低优先级线程,或者高优先级线程阻塞的时候就会发生Context Switching。大量的Context Switching可以发生在许多线程拥有相同的优先级的情况下,这通常表示有太多的线程竞争CPU,如果你没有看到太高的处理器使用率而且发现Context Switch非常低,那么表示线程被阻塞。
内存
- Windows -Memory
指标名称 |
指标描述 |
指标范围 |
指标单位 |
Pages/sec Pages Input/sec Pages Output/sec Page Fault/sec |
Page Faults/sec 是处理器每秒钟处理的错误页(包括软错误和硬错误)。Pages Input/sec 是为了解决硬错误页,从硬盘上读取的页数, 而Page Reads/sec是为了解决硬错误,从硬盘读取的次数。Pages/sec是Pages Input/sec 和Pages Output/sec 的总和。 该系列指标是可以显示导致系统范围延缓类型错误的主要指示器。 当处理器向内存指定的位置请求一页(可能是数据或代码)出现错误时,这就构成一个Page Fault。如果该页在内存的其他位置,该错误被称为软错误( 用Transition Fault/sec衡量); 如果该页必须从硬盘上重新读取时, 被称为硬错误。许多处理器可以在有大软错误的情况下继续操作。但是, 硬错误可以导致明显的拖延。 |
如果Page Reads/Sec持续保持为5,表示可能内存不足。Page/sec推荐0-20。如果服务器没有足够的内存处理其工作负荷,此数值将一直很高。如果大于80,表示有问题(太多的读写数据操作要访问磁盘,可考虑增加内存或优化读写数据的算法)。 该系列计数器的值比较低, 说明响应请求比较快, 否则可能是服务器系统内存短缺引起(也可能是缓存太大, 导致系统内存太少)。 |
次/sec |
Available Bytes |
显示出当前空闲的物理内存总量,它等于分配给待机(缓存的)、空闲和零分页列表内存的总和。 空闲内存可以马上使用; 清零内存是由零值填满的内存页,用来防止后续进程获得旧进程使用的数据; 待机内存是从进程工作集(其物理内存)中删除然后进入磁盘的内存,但是该内存仍然可以收回。该指标仅显示最后一次观察到的值,不是平均值。 |
当这个数值变小时,Windows开始频繁地调用磁盘页面文件。如果这个数值很小,例如小于5 MB,系统会将大部分时间消耗在操作页面文件上。 一般要保留10%的可用内存。最低不能<4M,此值过小可能是内存不足或内存泄漏。 |
|
Committed Bytes |
是指以字节表示的确认虚拟内存,是磁盘页面文件上保留空间的物理内存。 |
不超过物理内存的 75% |
硬盘参数
-
Windows -Disk
指标名称 |
指标描述 |
指标范围 |
指标单位 |
% Disk Time |
指所选磁盘驱动器忙于为读或写入请求提供服务所用的时间的百分比。 |
正常值<10,此值过大表示耗费太多时间来访问磁盘,可考虑增加内存、更换更快的硬盘、优化读写数据的算法。若数值持续超过80 (此时处理器及网络连接并没有饱和),则可能是内存泄漏。 |
|
Current Disk Queue Length |
是在收集性能数据时磁盘上当前的请求数量。它还包括在收集时处于服务的请求。这是瞬间的快照,不是时间间隔的平均值。多轴磁盘设备能有一次处于运行状态的多重请求,但是其他同期请求正在等待服务。此计数器会反映暂时的高或低的队列长度,但是如果磁盘驱动器被迫持续运行,它有可能一直处于高的状态。 |
请求的延迟与此队列的长度减去磁盘的轴数成正比。为了提高性能,此差应该平均小于二。 |
|
Avg.Disk Queue Length Avg. Disk Read Queue Length Avg. Disk Write Queue Length |
指读取和写入请求(为所选磁盘在实例间隔中列队的)的平均数。 |
Avg.Disk Queue Length正常值<0.5,此值过大表示磁盘IO太慢,要更换更快的硬盘。 |
Typeperf
您可以使用 Typeperf.exe 工具来完成以下操作:
将性能数据写入命令窗口或写入受支持的日志文件格式。
显示特定的本地或远程计算机上所有当前可用的计数器。
示例
要每隔 5 秒钟从名为“XPPRO”的远程计算机中输出内存计数器“可用字节”,您可以使用 typeperf "Memory\Available Bytes"
-s XPPRO -si 00:05 命令。
Linux
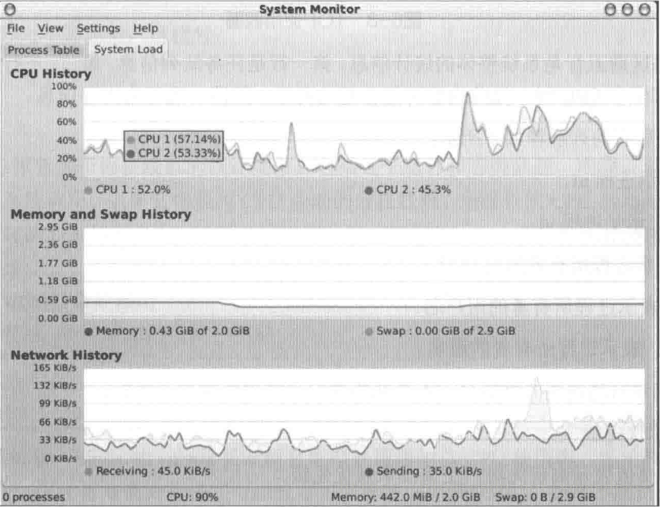
GNOME System Monitor
这是一个图形化的工具,但是大多生产环境的服务器都是没有界面的,所以我没细究这个工具。
| 针对 | 命令 | 意义 |
|---|---|---|
| CPU、内存 | top | 看系统每个进程CPU、内存实时使用率 |
| CPU、内存 | htop | 和top一样,但是需要在x终端等上面使用 |
| CPU、IO、IPC、进程等等 | vmstat | vmstat命令报告关于内核线程的统计信息,包括处于运行和等待队列、内存、页面调度、磁盘、系统中断、系统调用、上下文切换和CPU活动的内核线程。 |
| CPU、IO、IPC、进程等等 | sar | sar(System Activity Reponer系统活动情况报告)是目前Linux上最为全面的系统性能分析工具之一,可以从多方面对系统的活动进行报告,包括:文件的读写情况、系统调用的使用情况、磁盘I/O、CPU效率、内存使用状况、进程活动及IPC有关的活动等。 |
| CPU | mpstat | Linux还提供命令行工具mpstat,以列表方式展示每个虚拟处理器的CPU使用率。 |
| CPU线程 | pidstat | pidstat工具可以用来检测CPU使用,该工具可以具体找出占用CPU的线程 |
| CPU线程 | jstack | 如果需要查看具体哪个类造成的CPU资源消耗较大,可以通过jstack -l pid命令找到它们。 |
| 内存 | free | free命令是一个快速查看内存使用情况的方法,它是对/proc/meminfo收集到的信息的一个概述。 |
| 内存 | jmap | JMap是一个可以输出所有内存中对象的工具,甚至可以将VM中的heap,以二进制数输出成文本。 |
| CPU、内存、磁盘和网络 | atop | 这是一款用于监控Linux系统资源与进程的工具,它以一定的频率记录系统的运行状态,所采集的数据包含系统资源(CPU、内存、磁盘和网络)使用情况和进程运行情况,并能以日志文件的方式保存在磁盘中,服务器出现问题后,我们可获取相应的atop日志文件进行分析。 |
| 磁盘I/O | iostat | iostat用于输出CPU和磁盘I/O相关的统计信息。 |
| 磁盘 | df | Linux系统中需要监控磁盘各分区的使用情况,避免由于各种突发情况,造成磁盘空间被消耗殆尽的情况 |
| 网络 | netstat | Netstat命令用于显示各种网络相关信息,如网络连接,路由表,接口状态(InterfaceStatistics),masquerade连接,多播成员(MulticastMemberships)等。 |
| 网络 | ifstat | ifstat工具是个网络接凵监测工具,比较简单看网络流量。 |
| 网络 | iftop工具 | iftop是一款实时流量监控工具,监控TCP/IP连接等,缺点是无报表功能。必须以root身份才能运行。 |
| 网络 | nload | 如果你仅仅是想查询当前服务器的带宽,nload绝对是个很好用的一个工具 |
top
Top命令不仅包括CPU使用率也包括进程统计数据和内存使用率。Top是一个动态显示过程,即可以通过用户按键来不断刷新当前状态。如果在前台执行该命令,它将独占前台,直到用户终止该程序为止。比较准确地说,Top命令提供了实时的对系统处理器的状态监视,它将显示系统中CPU最“敏感”的任务列表。该命令可以按CPU使用。内存使用和执行时间对任务进行排序;而且该命令的很多特性都可以通过交互式命令或者在个人定制文件中进行设定。
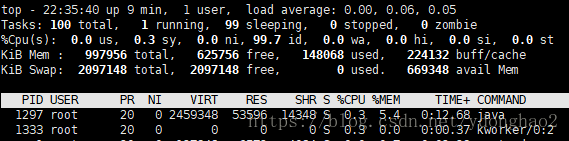
Top命令所有的列解释如下所示。
| 列名 | 意义 |
|---|---|
| PID | 表示进程id。 |
| PPID | 表示父进程id。 |
| UID | 表示进程所有者的用户id。 |
| USER | 表示进程所有者的用户名。 |
| GROUP | 表示进程所有者的组名。 |
| TTY | 表示启动进程的终端名。不是从终端启动的进程则显示为?。 |
| PR | 表示优先级。 |
| NInice | 负值表示高优先级,正值表示低优先级。 |
| %CPU | 表示上次更新到现在的CPU时间占用百分比。 |
| TIME | 表示进程使用的CPU时间总计,单位秒。 |
| TIME+ | 表示进程使用的CPU时间总计,单位1/100秒。 |
| %MEM | 表示进程使用的物理内存百分比。 |
| VIRT | 表示进程使用的虚拟内存总量,单位KBOVIRT=SWAP+RES。 |
| SWAP | 表示进程使用的虚拟内存中,被换出的大小,单位KB。 |
| RES | 表示进程使用的、未被换出的物理内存大小,单位KBORES=CODE+DATA。 |
| CODE | 表示可执行代码占用的物理内存大小,单位KB。 |
| DATA | 表示可执行代码以外的部分(数据段+栈)占用的物理内存大小,单位KB。 |
| SHR | 表示共享内存大小,单位KB。 |
| nFLT | 表示页面错误次数。 |
| nDRT | 表示最后一次写入到现在,被修改过的页面数。 |
HTop
HTop是Linux系统中的一个互动的进程查看器,一个文本模式的应用程序(在控制台或者X终端中),需要ncurseso与Linux传统的top相比,htop更加人性化。它可让用户交互式操作,支持颜色主题,可横向或纵向滚动浏览进程列表,并支持鼠标操作。htop命令还可以显示每个进程的内存实时使用率。它提供了所有进程的常驻内存大小、程序总内存大小、共享库大小等的报告。
列表可以水平及垂直滚动。与top相比,htop有以下优点:
(1) 可以横向或纵向滚动浏览进程列表,以便看到所有的进程和完整的命令行:
(2)在启动上,比top更快;
(3)杀进程时不需要输入进程号;
(4)htop支持鼠标操作。
vmstat
vmstat命令报告关于内核线程的统计信息,包括处于运行和等待队列、内存、页面调度、磁盘、系统中断、系统调用、上下文切换和CPU活动的内核线程。所报告的CPU活动是用户方式、系统方式、空闲时间和等待磁盘I/O的百分比详细分类。

如果是虚拟机器,Linux的vmstat显示所有虚拟处理器的总CPU使用率。无论物理机器、虚拟机器,两者的vmstat都有命令行选项可以设定报告的时间间隔(秒级)。如果不指定vmstat的报告间隔,则输出自从系统最近一次启动以来的总CPU使用率。如果指定间隔,统计数据的第一行则是最近一次启动以来所有数据的总和,不过通常来说都可以忽略不计。如果使用vrnstat命令时
不带任何选项,或者只带有间隔时间和任意的计数参数,例如vmstat 2 10:那么第一行数字为自系统重新引导以来的平均值。
如果需要检查CPU占有率是否很高,Linux操作系统也可以使用vmstat命令查看。我在服务器上运行了一个阶段性占用CPU的进程后,情况如下图所示。vmstat输出的第一列是运行队列长度,值是运行队列中轻量级进程的实际数量。

| 项目 | 解释 |
|---|---|
| r | 表示运行队列(就是说多少个进程真的分配到CPU),当这个值超过了CPU数目,就会出现CPU瓶颈了。这个也和top的负载有关系,一般负载超过了3就比较高,超过了5就高,超过了10就不正常了,服务器的状态很危险。top的负载类似每秒的运行队列。如果运行队列过大,表示你的CPU很繁忙,一般会造成CPU使用率很高。 |
| b | 表示阻塞的进程。 |
| swpd | 表示虚拟内存己使用的大小,如果大于0,表示你的机器物理内存不足了,如果不是程序内存泄漏的原因,那么你应该升级内存或者把耗内存的任务迁移到其他机器。 |
| free | 表示空闲的物理内存的大小。 |
| buff | 表示目录里面有什么内容,权限等的缓存。 |
| cache | 直接用来记忆我们打开的文件,给文件做缓冲,把空闲的物理内存的一部分拿来做文件和目录的缓存,是为了提高程序执行的性能。 |
| si | 每秒从磁盘读入虚拟内存的大小,如果这个值大于0,表示物理内存不够用或者内存泄露了,要查找消耗内存进程解决掉。 |
| so | 每秒虚拟内存写入磁盘的大小,如果这个值大于0,同上。 |
| bi | 块设备每秒接收的块数量,这里的块设备是指系统上所有的磁盘和其他块设备,默认块大小是1024Byte。 |
| bo | 块设各每秒发送的块数量,例如我们读取文件,bo就要大于0。bi和bo一般都要接近0,不然就是IO于频繁,需要调整。 |
| in | 每秒CPU的中断次数,包括时间中断。 |
| cs | 每秒上下文切换次数,例如我们调用系统函数,就要进行上下文切换,线程的切换,也要进程上下文切换,这个值要越小越好,太大了,要考虑调低线程或者进程的数目,例如在Apache和Nginx这种Web服务器中,我们一般做性能测试时会进行几千并发甚至几万并发的测试,选择Web服务器的进程可以由进程或者线程的峰值一直下调,压测,直到cs到一个比较小的值,这个进程和线程数就是比较合适的值了。系统调用也是,每次调用系统函数,我们的代码就会进入内核空间,导致上下文切换,这个是很耗资源,也要尽量避免频繁调用系统函数。上下文切换次数过多表示你的CPU大部分浪费在上下文切换,导致CPU干正经事的时间少了,CPU没有充分利用,是不可取的。 |
| us | 用户CPU时间。 |
| sy | 系统CPU时间,如果太高,表示系统调用时间长,例如是I/O操作频繁。 |
| id | 空闲CPU时间,一般来说,id+us+sy=100,一般我认为id是空闲CPU使用率,us是用户CPU使用率,sy是系统CPU使用率。 |
| wt | 等待I/O CPU时间。 |
Sar工具
sar(System Activity Reponer系统活动情况报告)是目前Linux上最为全面的系统性能分析工具之一,可以从多方面对系统的活动进行报告,包括:文件的读写情况、系统调用的使用情况、磁盘I/O、CPU效率、内存使用状况、进程活动及IPC有关的活动等。
命令格式是这样的,sar [options] [-A][-o file] t [n],其中各选项代表的意义如下所示。
| 选项 | 意义 |
|---|---|
| t | 表示采样间隔,n为采样次数,默认值是1。 |
| -o file | 表示将命令结果以二进制数形式存放在文件中,file是文件名。 |
options为命令行选项。
| options选项 | 意义 |
|---|---|
| -A | 所有报告的总和。 |
| -u | 输出CPU使用情况的统计信息。 |
| -v | 输出inode、文件和其他内核表的统计信息。 |
| -d | 输出每一个块设备的活动信息。 |
| -r | 输出内存和交换空间的统计信息。 |
| -b | 显示I/O和传送速率的统计信息。 |
| -a | 文件读写情况。 |
| -c | 输出进程统计信息,每秒创建的进程数。 |
| -R | 输出内存页面的统计信息。 |
| -y | 终端设备活动情况。 |
| -w | 输出系统交换活动信息。 |
例如,每10秒采样一次,连续采样3次,观察CPU的使用情况,并将采样结果以二进制数形式存入当前目录下的文件test中,需键入如下命令:
sar -u -o test 10 3

输出项说明如下。
| 选项 | 意义 |
|---|---|
| CPU | all表示统计信息为所有CPU的平均值。 |
| %user | 显示在用户级别(application)运行使用CPU总时间的百分比。 |
| %nice | 显示在用户级别,用于nice操作,所占用CPU总时间的百分比。 |
| %system | 在核心级别(kernel)运行所使用CPU总时间的百分比。 |
| %iowait | 显示用于等待I/O操作占用CPU总时间的百分比。 |
| %steal | 管理程序(hypervisor)为另一个虚拟进程提供服务而等待虚拟CPU的百分比。 |
| %idle | 显示CPU空闲时间占用CPU总时间的百分比。 |
以上输出结果如果出现以下情况,有对应的症状表示。
(1) 若%iowait的值过高,表示硬盘存在I/O瓶颈;
(2)若%idle的值高但系统响应慢时,有可能是CPU等待分配内存,此时应加大内存容量;
(3)若%idle的值持续低于1,则系统的CPU处理能力相对较低,表明系统中最需要解决的资源是CPU。
如果要查看二进制文件test中的内容,可以通过如下sar命令来完成。
sar -u -f test
vmstat命令总结了系统中所有进程使用的总活动虚拟内存,以及空闲列表上实内存页帧的数量。活动的虚拟内存定义为虚拟内存中实际可以得到的工作段页面的数量。这个数字可能大于机器中的实际页帧数,因为一些活动的虚拟内存页可能己写出到调页空间中。
当确定系统内存是否短缺或者是否需要进行某种内存调整时,在设定的时间间隔内运行vmstat命令,并检查结果报告中的pi和PO列。这两列表明了每秒调页空间页面调入的数量和每秒调页空间页面调出的数量。如果这些值经常为非零值,说明可能存在内存瓶颈。偶尔出现的非零值不用在意,因为页面调度是虚拟内存的主要原理。
确定系统的适当RAM数量的一种方法是查看vmstat命令报告的avm的最大值。将该数字乘以4K得到字节数,然后将其与系统的RAM字节数比较。理想情况下,avm应该小于总RAM如果不是,可能会出现一些虚拟内存页面调度量。有多少页面调度发生取决于两个值之间的差值。记住,虚拟内存的概念是提供给我们寻址大于实内存容量的能力(一些在RAM内存中,而另一些在调页空间中)。但是如果虚拟内存远大于实内存,可能造成过度的页面调度,从而导致延时。
如果avm小于RAM,那么当RAM中填满文件页时就会引起调页空间的页面调度。这种情况下,调整minperm、maxperm和maxclient的值可以减少调页空间的页面调度量。
mpstat
Linux还提供命令行工具mpstat,以列表方式展示每个虚拟处理器的CPU使用率。

mpstat各个命令的字段的显示
| 字段 | 解释 |
|---|---|
| %user | 表示处理用户进程所使用CPU的百分比。用户进程是用于应用程序(如Oracle数据库)的非内核进程。在本示例输出中,用户CPU百分比非常低。 |
| %nice | 表示使用nice命令对进程进行降级时CPU的百分比。在之前的部分中己经对nice命令进行了介绍。简单来说,nice命令更改进程的优先级。 |
| %system | 表示内核进程使用的CPU百分比。 |
| %iowait | 表示等待进行I/O所使用的CPU时间百分比。 |
| %irq | 表示用于处理系统中断的CPU百分比。 |
| %soft | 表示用于软件中断的CPU百分比。 |
| %idle | 表示CPU的空闲时间。 |
| %intr/s | 表示每秒CPU接收的中断总数。 |
mpstat命令和vmstat之间存在一定的区别,mpstat可以显示每个处理器的统计,而vmstat显示所有处理器的统计。因此,编写糟糕的应用程序(不使用多线程体系结构)可能会运行在一个多处理器机器上,而不使用所有处理器。从而导致一个CPU过载,而其他CPU却很空闲。通过mpstat可以轻松诊断这些类型的问题。
总的来说,mpstat命令还产生与CPU有关的统计信息,因此所有与CPU问题有关的讨论也都适用于mpstat。当看到较低的%idle数字时,就知道出现了CPU不足的问题。当看到较高的%iowait数字时,就可以知道在当前负载下I/O了系统出现了某些问题。该信息对于解决Oracle等关系型数据库的性能问题时非常有效。
pidstat
可以采用pidstat工具来检测CPU使用,该工具可以具体找出占用CPU的线程,t参数将系统性能的监控细化到线程级别。
jstack
如果需要查看具体哪个类造成的CPU资源消耗较大,可以通过jstack -l pid命令找到它们。
free
free命令是一个快速查看内存使用情况的方法,它是对/proc/meminfo收集到的信息的一个概述。

/proc/meminfo
Linux系统上的/proc目录是一种文件系统,即proc文件系统。与其他常见的文件系统不同的是,/proc是一种伪文件系统(即虚拟文件系统),存储的是当前内核运行状态的一系列特殊文件,用户可以通过这些文件查看有关系统硬件及当前正在运行进程的信息,甚至可以通过更改其中某些文件来改变内核的运行状态。基于/proc文件系统如上所述的特殊性,其内的文件也常被称作虚
拟文件,并具有一些独特的特点。例如,其中有些文件虽然使用查看命令查看时会返回大量信息,但文件本身的大小却会显示为0字节。此外,这些特殊文件中大多数文件的时间及日期属性通常为当前系统时间和日期,这跟它们随时会被刷新(存储于RAM中)有关。为了查看及使用上的方便,这些文件通常会按照相关性进行分类存储于不同的目录甚至子目录中,如/proc/scsi目录中
存储的就是当前系统上所有SCSI设备的相关信息,/proc/N中存储的则是系统当前正在运行的进程的相关信息,其中N为正在运行的进程(可以想象得到,在某进程结束后其相关目录则会消失)。
查看内存使用情况最简单的方法是通过/proc/meminfo,这个动态更新的虚拟文件实际上是许多其他内存相关工具(如:free/ps/top)等的组合显示。/proc/meminfo列出了所有你想了解的内存的使用情况。
JMap
JMap是一个可以输出所有内存中对象的工具,甚至可以将VM中的heap,以二进制数输出成文本。使用命令SHELL jmap -histo pid > a.log可以将输出重定向并保存到文本文件中去(Windows下也可以使用),相应地,可以使用文本对比工具可以打开盖文件,并查看GC回收了哪些对象。

一个heap dump是Java虚拟机(JVM)在某一时刻所有对象的快照。JVM从堆中为所有的类实例和数组分配内存。当一个对象不再被使用并且没有对它的引用时,垃圾回收器回收其堆内存。
通过查看堆,你可以找到对象创建的位置,发现对象的引用。
下面的命令可以将1352进程的内存heap输出出来到fl文件里。
生成的fl文件是一个二进制文件,需要用特定的工具才能打开。JHat只是在jdk1.6~1.8之中使用,jdk1.9之后的版本已经放弃jhat。建议使用VisualVm浏览heap dump文件的内容。


参数
option:选项参数,不可同时使用多个选项参数
pid:java进程id,命令ps -ef | grep java获取
executable:产生核心dump的java可执行文件
core:需要打印配置信息的核心文件
remote-hostname-or-ip:远程调试的主机名或ip
server-id:可选的唯一id,如果相同的远程主机上运行了多台调试服务器,用此选项参数标识服务器
options参数
heap : 显示Java堆详细信息
histo : 显示堆中对象的统计信息
permstat :Java堆内存的永久保存区域的类加载器的统计信息
finalizerinfo : 显示在F-Queue队列等待Finalizer线程执行finalizer方法的对象
dump : 生成堆转储快照
F : 当-dump没有响应时,强制生成dump快照
atop
这是一款用于监控Linux系统资源与进程的工具,它以一定的频率记录系统的运行状态,所采集的数据包含系统资源(CPU、内存、磁盘和网络)使用情况和进程运行情况,并能以日志文件的方式保存在磁盘中,服务器出现问题后,我们可获取相应的atop日志文件进行分析。atop是一款开源软件,我们可以从http://www.atoptool.nl/downloadatop.php获得其源码和rpm安装包。
iostat
iostat用于输出CPU和磁盘I/O相关的统计信息。

df
Linux系统中需要监控磁盘各分区的使用情况,避免由于各种突发情况,造成磁盘空间被消耗殆尽的情况,例如某个分区被Oracle的归档日志耗尽,导致后续的日志文件无法归档,这时ORACLE数据库就会出现错误。
一般查看磁盘各分区的使用情况可以通过df命令来查看,我们采用df -h命令可以输出基本的磁盘数据,


Netstat
Netstat命令用于显示各种网络相关信息,如网络连接,路由表,接口状态(InterfaceStatistics),masquerade连接,多播成员(MulticastMemberships)等。

- 显示所有端口:netstat -a | more
- 显示所有TCP端口:netstat -at
- 显示所有UDP端口:netstat -au
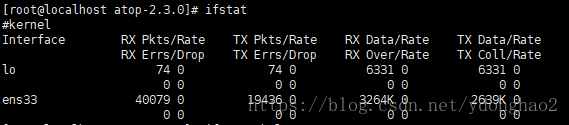
ifstat
ifstat工具是个网络接凵监测工具,比较简单看网络流量。简单的执行如下所示,默认ifstat不监控回环接口,显示的流量单位是KB。

iftop工具
iftop是一款实时流量监控工具,监控TCP/IP连接等,缺点是无报表功能。必须以root身份才能运行。
默认是监控第一块网卡的流量:iftop
监控ethl:iftop-iethl
直接显示IP,不进行DNS反解析:iftop-n
直接显示连接埠编号,不显示服务名称:iftop-N
显示某个网段进出封包流量:iftop-F192.168.1.0/24or192.168.1.0/255.255.255.0
通过iftop的界面很容易找到哪个ip在霸占网络流量,这个是ifstat做不到的。不过iftop的流量显示单位是Mb,这个b是bit,是位,不是字节,而ifstat的KB,这个B就是字节了,byte是bit的8倍。初学者容易被误导。
nload工具
如果你仅仅是想查询当前服务器的带宽,nload绝对是个很好用的一个工具,功能虽然很单一但是很强。虽然不能像ipf那样,可针对IP,协议等条件来查询,可以实时地监控网卡的流量,分输入流量Incoming和输出流量Outgoing两部分,同时统计当前、平均、最小、最大、总流量的值,并且用动态图形方式表现出来,让你一目了然。
输入nload回车即可看到动态流量信息,也可以指定网卡,如nloadethlo还可以指定是以K或M来显示流量,如nload-uM显示的流量是以MB为单位的。