一、环境准备
1、主机操作系统:处理器:i5,主频:2.4G,内存:12G,Windows64
2、虚拟机软件:VMware Workstation 10
3、虚拟机操作系统:CentOs-7.0 64位
4、JDK:1.8 64位
5、hadoop:2.8.2
6、虚拟三台服务器 master(192.168.35.170)、slave1(192.168.35.171)、slave2(192.168.35.172)
二、设置固定IP地址
1、使用命令: vi /etc/sysconfig/network-scripts/ifcfg-ens33
2、新加入以下配置信息(注意以下标红色要修改为自己的IP地址)以下为我的master 的IP地址
IPADDR0=192.168.35.170
PREFIXO0=24
GATEWAY0=192.168.35.255
DNS1=8.8.8.8
3、用#注释掉 BOOTPROTO=dhcp
4、修改 ONBOOT=yes
5、按esc 再输入命令 :wq 退出写入保存
6、使用命令:ifconfig 进行配置查看

7、使用命令:service network restart 进行网络重新启动
8、使用命令:ping 验证master(192.168.35.170) 与 slave1(192.168.35.171)、slave2 (192.168.35.172) 是否相通

9、根据以上几步进行 slave1、slave2的网络配置
10、使用命令:vi /etc/hosts 修改master、slave1、slave2的hosts 文件 文件内容如下
下图为master 的配置文件 slave1、slave2也一样
三台机器hosts 文件设置完之后 在master通过ping slave1.hadoop 是否可以通;
三、JDK 安装
1、用root账号在usr目录下创建java文件夹
2、上传jdk压缩包 jdk-8u161-linux-x64.tar.gz 到 usr/java 目录中
3、使用命令: tar zxvf jdk-8u161-linux-x64.tar.gz 解压

4、使用命令:mv jdk1.8.0_161 jdk1.8 更改文件夹名称
5、使用命令:vi /etc/profile 修改配置文件(就是配置java 环境变量)

6、按键盘 i 按键进行编辑;把以下配置放在文件最后面
export JAVA_HOME=/usr/java/jdk1.8
export JRE_HOME=/usr/java/jdk1.8/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$PATH

7、按键盘 esc 按键、 再输入 :wq 进行退出写入保存;不写入保存命令为 :q!
8、使用命令: source /etc/profile 使配置文件生效
9、使用命令: java -version 进行验证jdk是否安装成功

如上图 出现 Java version “1.8.0_161” 表示安装成功
四、关闭防火墙(要不上传文件到hadoop会报错)
CentOS 7.0默认使用的是firewall作为防火墙
关闭firewall:
systemctl stop firewalld.service #停止firewall
systemctl disable firewalld.service #禁止firewall开机启动
firewall-cmd --state #查看默认防火墙状态(关闭后显示notrunning,开启后显示running
注意:三台服务均要关闭
五、设置ssh 免密登录(以上四步均用root 账号操作)
1、使用命令:su hadoop 切换到hadoop用户下
2、使用命令:cd ~ 切换到 ~ 目录中

3、使用命令:ssh-keygen 生成秘钥文件(出现 enter file ........ 按回车就可以了)

4、此时已生成 .ssh 目录(此目录 用ls 是无法查看到的 直接cd .ssh 进入该目录)
5、使用命令:cat ~/id_rsa.pub >> ~/.ssh/authorized_keys 将公钥拷贝到 authorized_keys 文件中
6、用同样的方式操作 slave1、slave2 服务器
7、将三台服务器的 authorized_keys 的内容合并成一个 authorized_keys 文件; 然后替换掉三台服务器的authorized_keys

以上为合并完的文件内容
8、更改权限
chmod 755 ~
chmod 700 ~/.ssh
chmod 600 ~/.ssh/authorized_keys
9、使用命令: systemctl restart sshd.service 重启三台服务器的 ssh
10、在三台服务器的hadoop用户下 测试 ssh是否可免密登录(不能用root 测试 )
如:在master服务器 测试 ssh slave1.hadoop 、 ssh slave2.hadoop
在 slave1 服务器 测试 ssh master.hadoop 、ssh salve2.hadoop

出现last login: Fri Apr 6 19:01:25 2018 表示免密登录成功
exit 退出 到本机
六、开始hadoop 安装
1、使用命令:su root 切换到用root
2、使用命令:mkdir /usr/hadoop、 mkdir /usr/hadoop/dfs、 mkdir /usr/hadoop/tmp、mkdir /usr/hadoop/dfs/data、mkdir /usr/hadoop/dfs/name
3、使用命令: cd /usr/hadoop 目录下
4、上传hadoop的hadoop-2.8.2.tar.gz压缩文件
5、使用命令:tar xf hadoop-2.8.2.tar.gz 解压
6、使用命令:mv hadoop-2.8.2 hadoop-2.8 修改文件名
7、使用命令:vi /etc/profile 修改配置文件 在最后加入以下内容
export HADOOP_HOME=/usr/hadoop/hadoop-2.8
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
8、esc :wq 退出保存 source /etc/profile 使文件生效
9、使用命令:hadoop version 验证配置是否成功

10、配置 hadoop-2.8/etc/hadoop/hadoop-env.sh
修改文件中的 export JAVA_HOME=/usr/java/jdk1.8
11、修改配置文件 hadoop-2.8/etc/hadoop/core-site.xml
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://master.hadoop:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>file:/usr/hadoop/tmp</value> </property> <property> <name>io.file.buffer.size</name> <value>131702</value> </property> </configuration>
11、修改配置文件 hadoop-2.8/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master.hadoop:9001</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
12、使用命令 :cp mapred-site.xml.template mapred-site.xml
修改配置文件 mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master.hadoop:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master.hadoop:19888</value>
</property>
</configuration>
13、修改配置文件 yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master.hadoop:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master.hadoop:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master.hadoop:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master.hadoop:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master.hadoop:8088</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>768</value>
</property>
</configuration>
修改 master.xml 文件 (无此文件 可将slaves.xml 拷贝更改)
将 localhost 改为 192.168.35.170
修改 slaves.xml 文件
将localhost 改为
192.168.35.171
192.168.35.172
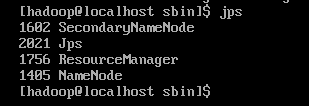
slave1
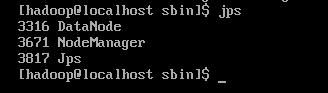
slav2 与slave1 一样
七、验证hadoop
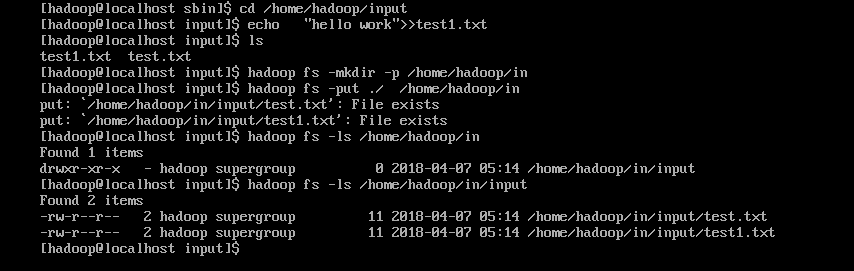
1、使用命令:mkdir /home/hadoop/input 创建input 文件夹
2、使用命令:cd /home/hadoop/input 目录下
3、使用命令: echo "hello word">>test.txt
4、使用命令:hadoop fs -mkdir -p /home/hadoop/in 在运行的hadoop中创建文件
5、使用命令:hadoop fs -put /home/hadoop/input/ /home/hadoop/in
6、使用命令:hadoop fs -ls /home/hadoop/in 进行查看