一、副本机制简介
在kafka中,topic是可以拆分为多个分区进行存储数据的,每个分区存储的数据都是不一样的。在kafka的集群环境下,为了避免出现单节点宕机导致的数据丢失迭代情况,kafka提供了一种分区数据的副本机制,保证在某个分区的读写节点宕机时,数据不会丢失。
bin/kafka-topics.sh --create --zookeeper 192.168.0.15:2181 --replication-factor 3 --partitions 1 --topic test 创建topic的时候通过指定replication-factor可以指定分区总共创建多少个副本,副本数不能超过broker数目。这些副本中,分为leader副本和follower副本,leader副本负责数据的读写请求,follower副本负责从leader副本复制数据到follower副本中备份数据。这样在当leader副本所在机器出现宕机的时候就可以在follower副本里面重新选举出一个leader副本来进行数据读写操作从而保证数据不会丢失。
副本分区分配方式
基本的分配思路就是
将n Broker和待分配的i个Partition排序
将第i个Partition分配到第(i mod n)个Broker上
将第i个Partition的第j个副本分配到第((i + j) mod n)个 Broker上.
由于副本数目是不能超过broker数目,所以副本会均匀分配到broekr上面。
副本leader
get /brokers/topics/test3p/partitions/0/state 命令可以在zookeeper中查询topic指定分区的副本leader
{"controller_epoch":12,"leader":0,"version":1,"leader_epoch":0,"isr":[0,1]}
可以查看到leader:0,0表示副本所在的broker的id。
ISR(in-Sync replicas )里面维护的是所有与leader数据差异在阈值范围内的副本所在的broker id列表,当producer向broker发送一条消息时,消息会写入到leader,同时follower会不断发起数据同步请求同步leader的数据,在这过程可能leader和follower之间的数据同步会存在差异。当数据差异在(replica.lag.time.max.ms)长的时间内副本数据依然没有和leader数据达成一致,那么这个follower 的broker id就会从isr维护的列表中剔除出去,知道数据重新达成和leader一致时才会再次加入到isr列表;同时如果副本broker与zookeeper断开连接,同样会从isr列表里面剔除出去。这个isr就是leader的候选人,除去已经是leader的broker id,isr中其他的id都可能成为leader。
二、副本协同机制
概念了解
kafka消息的读写操作都只会由leader节点来接收 和处理。follower副本只负责同步数据以及当leader副本,当leader所在的 broker 挂了以后,会从isr中维护的 follower 副本中选取新的 leader。 那么follower副本维护数据与leader保持一致的过程是怎么样实现的呢?
首先介绍两个副本协同过程需要了解的概念
LEO(log end offset)
日志末端位移(log end offset),记录了该副本底层 日志(log)中下一条消息的offset。如果LEO=10,那么表示该副本保存了10条消息, 位移值范围是[0, 9]。对于leader副本而言,leo在新消息写入时leo更新;对于follower而言,在向leader副本发起一次同步数据请求时,leader有新消息写入并且没同步给follower,这时将消息返回给follower,follower的leo更新。
HW(high watermark)
高水位,用来指示,在hw之前的offset消息都是可以消费的,也就是消息是已经提交的概念。例如hw是10,那么0-9的offset’的消息都是可以进行消费的消息。
对于leader而言,hw更新需要根据producer设置的ack模式来确定。
1.ack设置为0表示不需要任何副本确认,这时候消息在leader副本写入之后直接更新leader分区hw,表示消息是已提交可以消费。
2.ack设置为1表示只需要leader副本确认消息,这时候消息在leader副本写入之后直接更新leader分区hw,并且向producer发送确认ack,表示消息是已提交可以消费。
3.ack设置为-1表示消息需要n个副本确认消息,这时候需要leader收到n个副本的同步消息成功的ack之后才更新leader的hw并且发送ack给producer确认,表示消息是已提交可以消费。
这个n值指的是min.insync.replicas,设定ISR中的最小副本数是多少,默认值为 1, 当且仅当 acks 参数设置为-1 (表示需要所有副本确认)时,此参数才生效. 表达的含义 是,isr中至少有这么多个副本,需要isr中所有副本确认才可以认为消息已经提交。
对于follower而言,hw用来在重新选举leader时,表明哪些消息是可以消费的。
协同过程
下面画图展示一下ack -1情况下的同步过程。
首先是初始状态,leader和follower都没有数据,各自的leo和hw都是0,此时follower不断向leader发送fecth请求请求同步数据,,但是因为producer没有数据,这个请求会被leader寄存,当在指定的时间之后 会 强 制 完 成 请 求 , 这 个 时 间 配 置 是 (replica.fetch.wait.max.ms),如果在指定时间内 producer 有消息发送过来,那么kafka会唤醒fetch请求,让leader 继续处理。如下图所示。
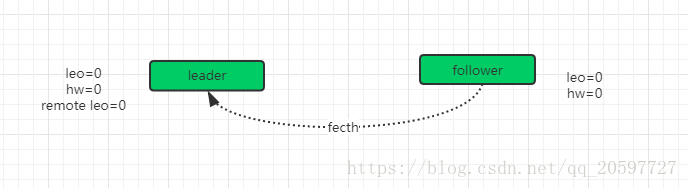
当producer发送来一条消息的时候。
1. 把消息追加到log文件,同时更新leader副本的LEO
2. 尝试更新leader HW值。leader会比较自己的LEO以及remote LEO的值 发现最小值是0,与HW的值相同,所以不会更新HW 。
如下图所示。

然后加入这时候刚好有fecth请求时或者有fecth请求处于阻塞 holding中就会唤醒这个fecth请求,leader会做以下动作。
1. 读取log数据、根据fecth请求的leo更新remote LEO=0
2. 尝试更新 HW,这时候Remote leo是0,leo是1,那么表示Remote 的follower副本还没有复制到这条消息数据,follower副本没确认这条消息数据,那么hw就不能更新,表明这条消息还不可以消费。
3. 把消息内容和当前分区的HW值发送给follower副本
follower接收到响应时,做以下动作。
1. 将消息写入到本地log,同时更新follower的LEO
2. 更新 follower HW,本地的 LEO 和 leader 返回的 HW 进行比较取小的值,所以仍然是0
如下图所示。
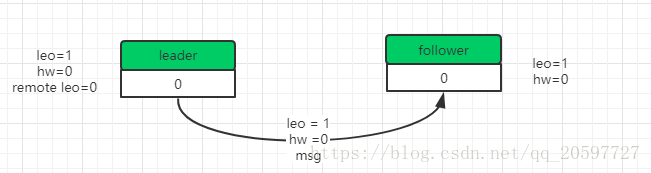
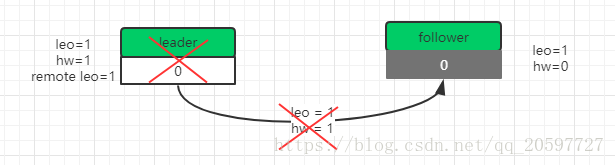
然后follower再一次发送fecth请求到leader,leader接收到这一次请求之后,把Remote leo更新为1**(如果isr是多个副本需要所有isr 维护的副本都把leo = 1请求到leader才可以更新Remote leo,如果某些follower实在同步太慢可以把它踢出isr副本列表,然后isr中剩余的副本确认了也是可以的)**,然后leader更新hw=1,表明offset 0消息是可以消费的,同时给producer发送确认ack。
如下图所示。
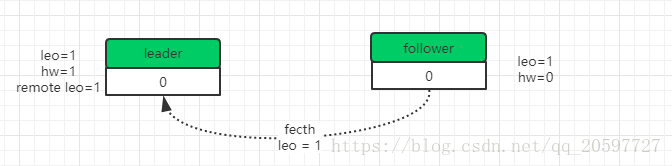
最后一步就是返回response给follower,更新follower的hw=1.
如下图所示。
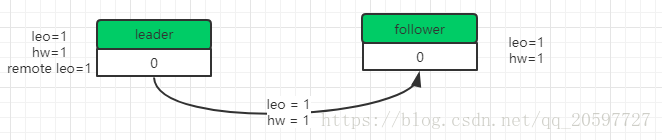
上面就是一条消息在ack = -1的情况下协同过程。
数据丢失
在协同过程的最后一步,其实就是更新follower的hw值,假如这个过程leader宕机了,那么follower的hw值没法更新,还是0,。此时副本重新选举leader,选中follower作为新的leader,这时就会按照hw = 0值去截断消息,认为offset = 0的消息是不可消费的。从而导致消息丢失。
kafka使 用leader epoch来解决这个问题。在/kafka-log/topic/leader-epochcheckpoint 文件中会存储
leader epoch信息,leader epoch是 一对之(epoch,offset), epoch 就是 leader 的次数号,从 0 开始,每次选举leader就会+1,而 offset则 对应于该 epoch 版本的 leader 写入第一条消息的位移。 比如说 (0,0) , (1,100); 表示第一个leader从offset=0开始写消息, 一共写100条,第二个leader版本号是1,从100offset开 始写消息。
leader broker中会保存这样的一个缓存,并定期地写入到 checkpoint文件中。 当 leader 写 log 时它会尝试更新整个缓存;如果这个 leader 首次写消息,则会在缓存中增加一个条目;而当follower成为新的leader时会查询这部分缓存,获取出对应leader版本的offset,确认哪些消息是否有效的。
所有的分区副本不可用?
- 等待 ISR 中的任一个 Replica重新启动,选它作为 Leader
- 选择第一个重启过来的Replica(不一定是ISR中的)作 为Leader
等待isr中的副本启动过来可能等待时间较长,但是可以保证数据完整;随便一个副本作为leader的话可能比较快让分区可用,但是数据可能会有丢失。
isr的设计原理
副本备份数据是分布式存储中常见的一种手段。单纯的同步备份需要要求所有能工作的 Follower 副 本都复制完,这条消息才会被认为提交成功,一旦有一个 follower副本出现故障,就会导致HW无法完成递增,消费者就获取不到消息。假如单纯的异步复制,那么就可能出现数据丢失的情况,无法保证follower副本数据的完整性。is维护了数据完整的副本备份列表,如果是数据差异较大就会剔除出isr,当需要重新选举leader的时候,从isr选,可以保证副本数据的完整性。通过设置min.insync.replicas可以设置isr中至少有几个副本,当有消息需要同步时,需要得到isr中所有的副本确认同步才可以被认为是提交成功的,如果某些副本实在同步太慢,leader就会把它踢出isr集合,然后得到剩余的isr副本确认就可以了。所以follower要么发送同步确认(leo跟上leader),要么被踢出isr,两种方式保证了消息提交不会慢,也保证数据不会丢失。