版权声明:本博客为技术原创, 未经允许,谢绝转载 !!! https://blog.csdn.net/yewandemty/article/details/81989695
Rocketmq之消息队列分配策略算法实现的源码分析
本文中包含下面的内容
- 平均分配策略(默认)(AllocateMessageQueueAveragely)
- 环形分配策略(AllocateMessageQueueAveragelyByCircle)
- 手动配置分配策略(AllocateMessageQueueByConfig)
- 机房分配策略(AllocateMessageQueueByMachineRoom)
- 一致性哈希分配策略(AllocateMessageQueueConsistentHash)
一、平均分配策略(AllocateMessageQueueAveragely)
下面是Rocketmq中 AllocateMessageQueueAveragely 的源码
public List<MessageQueue> allocate(String consumerGroup, String currentCID, List<MessageQueue> mqAll,List<String> cidAll) {
//省略参数校验、当前消费者id是否存在的校验
//走到下面的代码, 说明参数校验通过
int index = cidAll.indexOf(currentCID);
int mod = mqAll.size() % cidAll.size();
int averageSize =
mqAll.size() <= cidAll.size() ? 1 : (mod > 0 && index < mod ? mqAll.size() / cidAll.size()
+ 1 : mqAll.size() / cidAll.size());
int startIndex = (mod > 0 && index < mod) ? index * averageSize : index * averageSize + mod;
int range = Math.min(averageSize, mqAll.size() - startIndex);
for (int i = 0; i < range; i++) {
result.add(mqAll.get((startIndex + i) % mqAll.size()));
}
return result;
}对代码分析如下:
- 第4行, 计算当前消费者在消费者集合(List<String> cidAll)中下标的位置(index)
- 第5行, 计算当前消息队列(Message Queue)中的消息是否能被消费者集合(cidAll)平均消费掉
- 第6-8行, 计算当前消费者消费的平均数量
- mqAll.size() <= cidAll.size() ? 1 如果消费者的数量 >= 消息的数量, 当前消费者消耗的消息数量为1
- mod > 0 && index < mod ? mqAll.size() / cidAll.size() + 1 : mqAll.size() / cidAll.size() 如果消息不能被消费者平均消费掉, 且当前消费者在消费者集合中的下标(index) < 平均消费后的余数mod , 则当前消费者消费的数量为 mqAll.size() / cidAll.size() + 1 , 否则是 mqAll.size() / cidAll.size()
- 第9行,计算当前消费者开始消费消息的下标
- 如果消息不能被平均消费掉, 且当前消费者在消费者集合中的下标 < 平均消费后的余数mod , 则消息开始的下标为index * averageSize , 否则为index * averageSize + mod
第10行, 根据Math.min()计算消费者最终需要消费的数量
- 如果消息不能被平均消费掉, 且当前消费者在消费者集合中的下标 < 平均消费后的余数mod , 则消息开始的下标为index * averageSize , 否则为index * averageSize + mod
- 第11 - 14 行, 从startIndex开始的下标位置,加载数量为range的消息到result集合中,最后返回这个result
二、环形分配策略(AllocateMessageQueueAveragelyByCircle)
下面是Rocketmq中 AllocateMessageQueueAveragelyByCircle的源码
public List<MessageQueue> allocate(String consumerGroup, String currentCID, List<MessageQueue> mqAll, List<String> cidAll) {
//省略参数校验、当前消费者id是否存在的校验
//走到下面的代码, 说明参数校验通过
int index = cidAll.indexOf(currentCID);
for (int i = index; i < mqAll.size(); i++) {
if (i % cidAll.size() == index) {
result.add(mqAll.get(i));
}
}
return result;
}对代码分析如下:
- 第2-3行省略了参数校验、当前消费者是否存在的部分代码
- 第4行, 计算当前消费者在消费者集合(List<String>)中的下标(index)
- 第5-10行,遍历消息的下标, 对下标取模(mod), 如果与index相等, 则存储到result集合中,最后返回该集合 。
针对知识点一、二可以通过下面的图示进行进一步了解
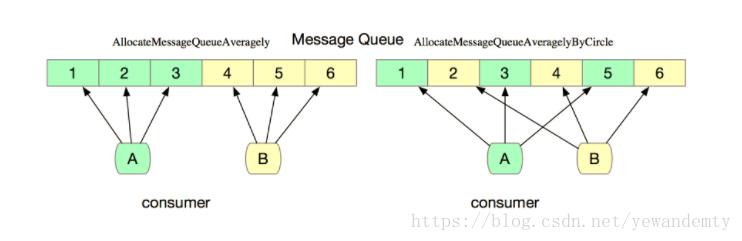
再举个例子:
假设有三个消费者、八个消息, 对普通分配方式和环形分配方式,分别如下:
- 普通消费方式
| Message Queue | ConsumerId |
|---|---|
| 消息队列[0] | Consumer[0] |
| 消息队列[1] | Consumer[0] |
| 消息队列[2] | Consumer[0] |
| 消息队列[3] | Consumer[1] |
| 消息队列[4] | Consumer[1] |
| 消息队列[5] | Consumer[1] |
| 消息队列[6] | Consumer[2] |
| 消息队列[7] | Consumer[2] |
- 环形消费方式
| Message Queue | ConsumerId |
|---|---|
| 消息队列[0] | Consumer[0] |
| 消息队列[1] | Consumer[1] |
| 消息队列[2] | Consumer[2] |
| 消息队列[3] | Consumer[0] |
| 消息队列[4] | Consumer[1] |
| 消息队列[5] | Consumer[2] |
| 消息队列[6] | Consumer[0] |
| 消息队列[7] | Consumer[1] |
三、手动配置策略(AllocateMessageQueueByConfig)
下面是手动配置的代码
public class AllocateMessageQueueByConfig implements AllocateMessageQueueStrategy {
private List<MessageQueue> messageQueueList;
@Override
public List<MessageQueue> allocate(String consumerGroup, String currentCID, List<MessageQueue> mqAll,
List<String> cidAll) {
return this.messageQueueList;
}
@Override
public String getName() {
return "CONFIG";
}
public List<MessageQueue> getMessageQueueList() {
return messageQueueList;
}
public void setMessageQueueList(List<MessageQueue> messageQueueList) {
this.messageQueueList = messageQueueList;
}
}代码分析:
进行分配的核心方法是allocate(), 从代码中可以看出分配的方式是从配置文件中获取相关的信息, 这中方式自己用的比较少,暂时忽略,后面有研究会进行相关内容更新。
四、机房分配策略(AllocateMessageQueueByMachineRoom)
下面是机房分配策略的代码
public List<MessageQueue> allocate(String consumerGroup, String currentCID, List<MessageQueue> mqAll,
List<String> cidAll) {
List<MessageQueue> result = new ArrayList<MessageQueue>();
int currentIndex = cidAll.indexOf(currentCID);
if (currentIndex < 0) {
return result;
}
List<MessageQueue> premqAll = new ArrayList<MessageQueue>();
for (MessageQueue mq : mqAll) {
String[] temp = mq.getBrokerName().split("@");
if (temp.length == 2 && consumeridcs.contains(temp[0])) {
premqAll.add(mq);
}
}
int mod = premqAll.size() / cidAll.size();
int rem = premqAll.size() % cidAll.size();
int startIndex = mod * currentIndex;
int endIndex = startIndex + mod;
for (int i = startIndex; i < endIndex; i++) {
result.add(mqAll.get(i));
}
if (rem > currentIndex) {
result.add(premqAll.get(currentIndex + mod * cidAll.size()));
}
return result;
}- 第4-7行, 计算当前消费者在消费者集合中的下标(index), 如果下标 < 0 , 则直接返回
- 第8-14行, 根据brokerName解析出所有有效机房信息(其实是有效mq), 用Set集合去重, 结果存储在premqAll中
- 第16行, 计算消息整除的平均结果mod
- 第17行, 计算消息是否能够被平均消费rem,(即消息平均消费后还剩多少消息(remaing))
- 第18行, 计算当前消费者开始消费的下标(startIndex)
- 第19行, 计算当前消费者结束消费的下标(endIndex)
- 第20-26行, 将消息的消费分为两部分, 第一部分 – (cidAllSize * mod) , 第二部分 – (premqAll - cidAllSize * mod) ; 从第一部分中查询startIndex ~ endIndex之间所有的消息, 从第二部分中查询 currentIndex + mod * cidAll.size() , 最后返回查询的结果result
可以通过下面的例子进一步了解,假设有三个消费者, 八个消息队列
| Message Queue | Consumer |
|---|---|
| 消息队列[0] | Consumer[0] |
| 消息队列[1] | Consumer[0] |
| 消息队列[2] | Consumer[1] |
| 消息队列[3] | Consumer[1] |
| 消息队列[4] | Consumer[2] |
| 消息队列[5] | Consumer[2] |
| 消息队列[6] | Consumer[0] |
| 消息队列[7] | Consumer[1] |
五、一致性哈希分配策略(AllocateMessageQueueConsistentHash)
下面是一致性哈希算法的代码
public List<MessageQueue> allocate(String consumerGroup, String currentCID, List<MessageQueue> mqAll, List<String> cidAll) {
//省略参数校验、当前消费者id是否存在的校验
//走到下面的代码, 说明参数校验通过
Collection<ClientNode> cidNodes = new ArrayList<ClientNode>();
for (String cid : cidAll) {
cidNodes.add(new ClientNode(cid));
}
final ConsistentHashRouter<ClientNode> router; //for building hash ring
if (customHashFunction != null) {
router = new ConsistentHashRouter<ClientNode>(cidNodes, virtualNodeCnt, customHashFunction);
} else {
router = new ConsistentHashRouter<ClientNode>(cidNodes, virtualNodeCnt);
}
List<MessageQueue> results = new ArrayList<MessageQueue>();
for (MessageQueue mq : mqAll) {
ClientNode clientNode = router.routeNode(mq.toString());
if (clientNode != null && currentCID.equals(clientNode.getKey())) {
results.add(mq);
}
}
return results;
}关于一致性哈希算法的讲解,可以通过下面的连接进行了解
https://blog.csdn.net/xianghonglee/article/details/25718099
https://blog.csdn.net/sparkliang/article/details/5279393
https://akshatm.svbtle.com/consistent-hash-rings-theory-and-implementation
https://github.com/gholt/ring/blob/master/BASIC_HASH_RING.md
代码分析:
目前对一致性哈希的了解还是停留在表明上,暂时不进行分析,后面有深入了解再填充这部分内容