本篇文章的内容有:
C++关键字
在C++98的标准下为63个关键字
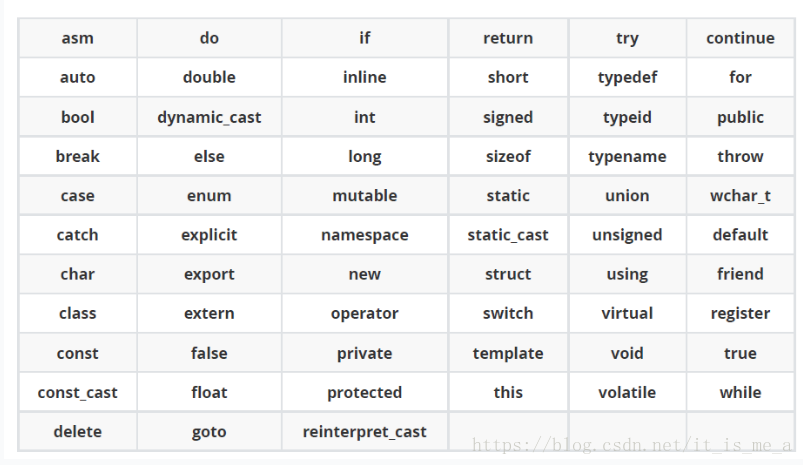
命名空间
- 定义命名空间
//1. 普通的命名空间
namespace N1 // N1为命名空间的名称
{
// 命名空间中的内容,既可以定义变量,也可以定义函数
int a;
int Add(int left, int right)
{
return left + right;
}
}
//2. 命名空间可以嵌套
namespace N2
{
int a;
int b;
int Add(int left, int right)
{
return left + right;
}
namespace N3
{
int c;
int d;
int Sub(int left, int right)
{
return left - right;
}
}
}
//3. 同一个工程中允许存在多个相同名称的命名空间
// 编译器最后会合成同一个命名空间中。- 命名空间的使用
1.加命名空间名称及作用域限定符
int main()
{
printf("%d\n", N::a);
return 0;
}2.使用using将命名空间中成员引入
using N::b;
int main()
{
printf("%d\n", b);
return 0;
}3.使用using namespace 命名空间名称引入
using namespace N1;
int main()
{
printf("%d\n", a);
printf("%d\n", b);
Add(10, 20);
return 0;
}C++的输入与输出
#include<iostream>
using namespace std;
int main()
{
cout<<"change world"<<endl; //输出
return 0;
}
int main()
{
int a;
cin>>a; //输入
a = 10;
cout<<hex<<a<<endl; //hex 16进制
}
注意
解决一闪而过的问题:cin.get();
解决一输入按enter就消失了的问题:把cin.get();换成system(“pause”);
缺省参数
缺省参数是声明或定义函数时为函数的参数指定一个默认值。在调用该函数时,如果没有指定实参则采用该默认值,否则使用指定的实参。
void TestFunc(int a = 0)
{
cout<<a<<endl;
}
int main()
{
TestFunc(); // 没有传参时,使用参数的默认值
TestFunc(10); // 传参时,使用指定的实参
}缺省参数分为:全缺省和半缺省
1.全缺省
void TestFunc(int a = 10, int b = 20, int c = 30)
{
cout<<"a = "<<a<<endl;
cout<<"b = "<<b<<endl;
cout<<"c = "<<c<<endl;
}2.半缺省
void TestFunc(int a, int b = 10, int c = 20)
{
cout<<"a = "<<a<<endl;
cout<<"b = "<<b<<endl;
cout<<"c = "<<c<<endl;
}注意:
1. 半缺省参数必须从右往左依次来提供,不能间隔着给出
void TEST1( int a, int b, int c = 1) // 正确
void TEST2( int a = 1 , int b, int c ) // 错误
void TEST3( int a = 1 , int b, int c = 1) // 错误
- 缺省参数不能同时在函数声明和定义中出现,只能二者择其一,最好在“声明”的位置
- 缺省值必须是常量或者全局变量
- C语言不支持
- 没有给缺省值的,下次调用时一定得给出值
函数重载
函数重载是函数的一种特殊情况,C++允许在同一作用域中声明几个功能类似的同名函数,这些同名函数的形参列表(参数个数、类型、顺序)必须不同,常用来处理实现功能类似数据类型不同的问题
若仅仅改变了函数的返回值类型,但未改变参数类型,不可以。
int Add(int left, int right)
{
return left+right;
}
double Add(double left, double right)
{
return left+right;
}
long Add(long left, long right)
{
return left+right;
}
int main()
{
Add(10, 20);
Add(10.0, 20.0);
Add(10L, 20L);
return 0;
}注意c函数不支持函数重载?
原因在于:名字修饰
名字修饰
名字修饰(Name Mangling)是一种在编译过程中,将函数、变量的名称重新改编的机制,简单来说就是编译器为了区分各个函数,将函数通过一定算法,重新修饰为一个全局唯一的名称。
为什么C语言不支持函数重载?
- C语言的名字修饰规则非常简单,只是在函数名字前面添加了下划线。
- 由于C++要支持函数重载,命名空间等,使得其修饰规则比较复杂,被重新修饰后的名字中包含了:函数的名字以及参数类型。这就是为什么函数重载中几个同名函数要求其参数列表不同的原因。只要参数列表不同,编译器在编译时通过对函数名字进行重新修饰,将参数类型包含在最终的名字中,就可保证名字在底层的全局唯一性。
例子链接:https://blog.csdn.net/it_is_me_a/article/details/81979537
引用(取别名)
引用不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内存空间,它和它引用的变量共用同一块内存空间。
类型& 引用变量名(对象名) = 引用实体;
void TestRef()
{
int a = 10;
int& ra = a; //<====定义引用类型
printf("%p\n", &a);
printf("%p\n", &ra);
}
注意:引用类型必须和引用实体是同种类型的注意
1. 引用在定义时必须初始化
2. 一个变量可以有多个引用
3. 引用一旦引用一个实体,再不能引用其他实体
常引用
void TestConstRef()
{
const int a = 10;
int& ra = a; // 该语句编译时会出错,a为常量
const int& ra = a; //正确
int& b = 10; // 该语句编译时会出错,b为常量
const int& b = 10; //正确
double d = 12.34;
int& rd = d; // 该语句编译时会出错,类型不同
const int& rd = d; //正确
//但得注意如果是上述直接加const,则d的值便不可更改,因为rd与d已经指向另一块区域
}数组的引用
void PrintArray(int (&array)[10]) //int (&arrzy) [10]
{
for(size_t i = 0; i < 10; ++i)
cout<<array[i]<<" ";
cout<<endl;
}
int main()
{
int array[] = {1,2,3,4,5,6,7,8,9,0};
PrintArray(array);
return 0;
}引用的使用场景
1. 作形参(既可以达到传值的效果,又可以达到传地址的效果)
//单纯引入引用
void Swap1(int& left, int& right)
{
int temp = left;
left = right;
right = temp;
}
//单纯引入值
void Swap2(int left, int right)
{
int tmp = left;
left = right;
right = tmp;
}
//单纯引入指针
void Swap3(int *left, int *right)
{
int tmp = *left;
*left = *right;
*right = tmp;
}
int main()
{
Swap1(a,b);
Swap2(a,b);
Swap3(&a, &b);
return 0;
}上述三种传值方式对比:
传值:每次都要生成临时变量,若结构较大,则费时间费地址
传地址:不用生成临时变量,只有传个指针就可以
传引用:在底层的处理模式和地址一样
注意
引用 <=> 指针
int& ra = a; <=> int * const ra = &a;//const代表ra只能指向a
2. 作返回值(生命周期比函数长)
int& Add(int a, int b)
{
int c = a + b;
return c;
}
int main()
{
int& ret = Add(10, 20);
Add(100, 200);
cout << "Add(10,20) is :"<< ret; //300
return 0;
}引用和指针的区别
- 引用在定义时必须初始化,指针没有要求
- 引用在初始化时引用一个实体后,就不能再引用其他实体,而指针可以在任何时候指向任何一个同类型实体
- 没有NULL引用,但有NULL指针
- 在sizeof中含义不同:引用结果为引用类型的大小,但指针始终是地址空间所占字节个数(32位平台下占4个字节)
- ++的含义不同:引用自加即引用的实体增加1,指针自加即指针向后偏移一个类型的大小
- 有多级指针,但是没有多级引用
- 访问实体方式不同,指针需要显式解引用,引用编译器自己处理
- 引用比指针使用起来相对更安全
内联函数
以inline修饰的函数叫做内联函数,编译时C++编译器会在调用内联函数的地方展开,没有函数压栈的开销,内联函数提升程序运行的效率。
在介绍内联函数时,先引入一下宏
宏
宏的优缺点?
#define Max(a, b) ((a) > (b) ? a : (b)) //这就是一个宏
int main()
{
int a = 20;
int b = 10;
int max = Max(++a, b); // a自增了两次
max = Max(++a, b+20); // a自增了一次
return 0;
}上面的代码a的自增次数是由与其比较的数字的大小来决定的,这样的代码结果不是想要的,怎么处理?—>内联函数
inline int Max(int a, int b)
{
return ((a) > (b) ? a : (b));
}
int main()
{
int a = 20;
int b = 10;
int max = Max(++a, b); // a自增了一次
max = Max(++a, b + 20); // a自增了一次
return 0;
}原因:
宏定义不是函数,但是使用起来像函数。预处理器用复制宏代码的方式代替函数的调用,省去了函数压栈退栈过程,提高了效率。这种方法简单的说就是字符串替换
而内联函数本质上是一个函数,因为调用函数实际上将程序执行顺序转移到函数所存放在内存中某个地址,将函数的程序内容执行完后,再返回到转去执行该函数前的地方。(先把++a处理了以后赋给新的a后,再进行比较)
这种转移操作要求在转去前要保护现场并记忆执行的地址,转回后先要恢复现场,并按原来保存地址继续执行。因此,函数调用要有一定的时间和空间方面的开销,于是将影响其效率。
特性
1. inline是一种以空间换时间的做法,省去调用函数额开销。所以代码很长或者有循环/递归的函数不适宜使用作为内联函数。
2. inline对于编译器而言只是一个建议,编译器会自动优化,如果定义为inline的函数体内有循环/递归等等,编译器优化时会忽略掉内联。
补充常见面试题:
宏的优缺点与那些技术可以可以替代宏?
宏的优点:
1.增强代码的复用性。
2.提高性能
缺点:
1.不方便调试宏。(因为预编译阶段进行了替换)
2.导致代码可读性差,可维护性差,容易误用。
3.没有类型安全的检查
C++有哪些技术替代宏?
1. 常量定义 换用 const
2. 函数定义 换用 内联函数
3. 类型重定义 换用 typedef