【试管婴儿包成功】【微信:13802269370】【试管婴儿可选男女】“体外受精和胚胎移植”(IVF-ET)叫“试管婴儿”。而事实上,体外受精是一种特殊的技术,是把卵子和精子都拿到体外来,让它们在体外人工控制的环境中完成受精过程,然后把早期胚胎移植到女性的子宫中,在子宫中孕育成为孩子。利用体外受精技术产生的婴儿称为试管婴儿,这些孩子也是在妈妈的子宫内长成的。可以说,“试管婴儿技术”等同于“体外受精”。
一、Python简介
1.特性:
- 优雅、明确、简单。
- 相当高级的语言,同样的功能下,代码量远远小于C、Java等。但是代价是运行速度慢。
- 表面上,这种高级语言学起来简单,但是只是入门简单,其实在非常高的抽象计算中,高级的python程序设计也是很难学的。但是,对于普通的任务,Python语言是很简单实用的。
- Python用处广泛:日常任务(如自动备份MP3),写网站(如YouTube、Instagram、豆瓣……),做网络游戏的后台……;总的来说,Python适合开发各种网络应用(包括网站、后台服务等等),血多日常需要的小工具(包括系统管理员需要的脚本任务等等),另外就是把其他语言开发的程序再包装起来,方便使用。只是除了写操作系统(只能用C);写手机应用(只能用Swift/Objective-C(针对iPhone)和Java(针对Android));写3D游戏,最好用C或C++。
- Python就为我们提供了非常完善的基础代码库,覆盖了网络、文件、GUI、数据库、文本等大量内容,被形象地称作“内置电池(batteries included)”。用Python开发,许多功能不必从零编写,直接使用现成的即可。除了内置的库外,Python还有大量的第三方库,也就是别人开发的,供你直接使用的东西。当然,如果你开发的代码通过很好的封装,也可以作为第三方库给别人使用。
2.缺点(其实也称不上缺点):
1)运行速度慢,与C相比。因为Python是解释性语言,你的代码在执行时会一行一行地翻译成CPU能理解的机器码,这个翻译过程非常耗时,所以很慢。但是一般大量的运用程序不需要这么快的运行速度,因为用户根本察觉不出来。
2)代码不能加密。这个缺点仅限于你要编写的软件需要卖给别人挣钱的时候。好消息是目前的互联网时代,靠卖软件授权的商业模式越来越少了,靠网站和移动应用卖服务的模式越来越多了,后一种模式不需要把源码给别人。
……
二、安装Python
1.Mac 上:官方安装;或者使用homebrew进行安装:brew install python3
2. 关于Python解释器:需要使用Python解释器去执行.py文件。由于python从规范到解释器都是开源的,所以水平够高就可以自己编写解释器。事实上,也存在多种python解释器:CPython(官方的,使用最广泛)、IPython、PyPy、JPython、IronPython。
三、第一个Python程序
1.命令行模式
在命令行模式下,可以执行python进入Python交互式环境,也可以执行python hello.py 运行一个.py文件。
执行一个.py文件只能在命令行模式执行。
2.交互模式
Python交互模式的代码是输入一行,执行一行,而命令行模式下直接运行.py文件是一次性执行该文件内的所有代码。可见,Python交互模式主要是为了调试Python代码用的,也便于初学者学习,它不是正式运行Python代码的环境!
3.使用文本编辑器
推荐Sublime Text和Notepad++,但是绝不能使用Word和Windows自带的笔记本。Word保存的不是纯文本文件,而记事本会自作聪明地在文件开始的地方加上几个特殊字符(UTF-8 BOM),结果会导致程序运行出现莫名其妙的错误。
4.直接运行py文件
能不能像.exe文件那样直接运行.py文件呢?在Windows上是不行的,但是,在Mac和Linux上是可以的,方法是在.py文件的第一行加上一个特殊的注释:
#!/usr/bin/env python3
print('hello,world')
然后,通过命令给hello.py以执行权限:
$ chmod a+x hello.py
然后就可以直接运行hello.py了: ./hello.py
用Python开发程序,完全可以一边在文本编辑器里写代码,一边开一个交互式命令窗口,在写代码的过程中,把部分代码粘到命令行去验证,事半功倍!前提是得有个27'的超大显示器!
5.Python代码运行助手
6.输入和输出
输入:input('输入提示语') 输出:print(……)
四、Python基础
Python的语法比较简单,采用缩进方式:缩进有利有弊。好处是强迫你写出格式化的代码,但没有规定缩进是几个空格还是Tab。按照约定俗成的管理,应该始终坚持使用4个空格的缩进。在文本编辑器中,需要设置把Tab自动转换为4个空格,确保不混用Tab和空格。最后,请务必注意,Python程序是大小写敏感的,如果写错了大小写,程序会报错。
此外,写法上,#代表注释,当语句以:结尾时,缩进的语句视为代码块。
1.数据类型和变量
- 整数:任意大小,正/负。
注意:Python的整数没有大小限制,而某些语言的整数根据其存储长度是有大小限制的,例如Java对32位整数的范围限制在
-2147483648-2147483647。 - 浮点数:也就是小数,之所以称为浮点数,是因为按照科学计数法表示时,一个浮点数的小数点的位置是可以变的,也能保持值相等。用科学计数法表示,把10用e替代,1.23x109就是
1.23e9,或者12.3e8,0.000012可以写成1.2e-5,等等。(整数和浮点数在计算机内部存储的方式是不同的,整数运算永远是精确的(除法难道也是精确的?是的!),而浮点数运算则可能会有四舍五入的误差。)Python的浮点数也没有大小限制,但是超出一定范围就直接表示为inf(无限大)。 - 字符串:
- 表示:""或者''
- 转义字符:\,为了简化避免使用太多转移字符,Python还允许用
r''表示''内部的字符串默认不转义,如print(r'\\\t\\')打印结果是\\\t\\ - 字符串内部很多换行:Python允许用
'''...'''的格式表示多行内容。(注意:...是命令行提示符的一部分,不是代码的一部分)
print('''123
...line2
...line3''')
如果写成程序并存为.py文件,就是:
print('''123
line2
line3''')
- 布尔值:在Python中,可以直接用
True、False表示布尔值(请注意大小写),也可以通过布尔运算计算出来。布尔值可以用and、or和not运算。 - 空值:空值是Python里一个特殊的值,用
None表示。None不能理解为0,因为0是有意义的,而None是一个特殊的空值。 - 变量:在Python中,等号
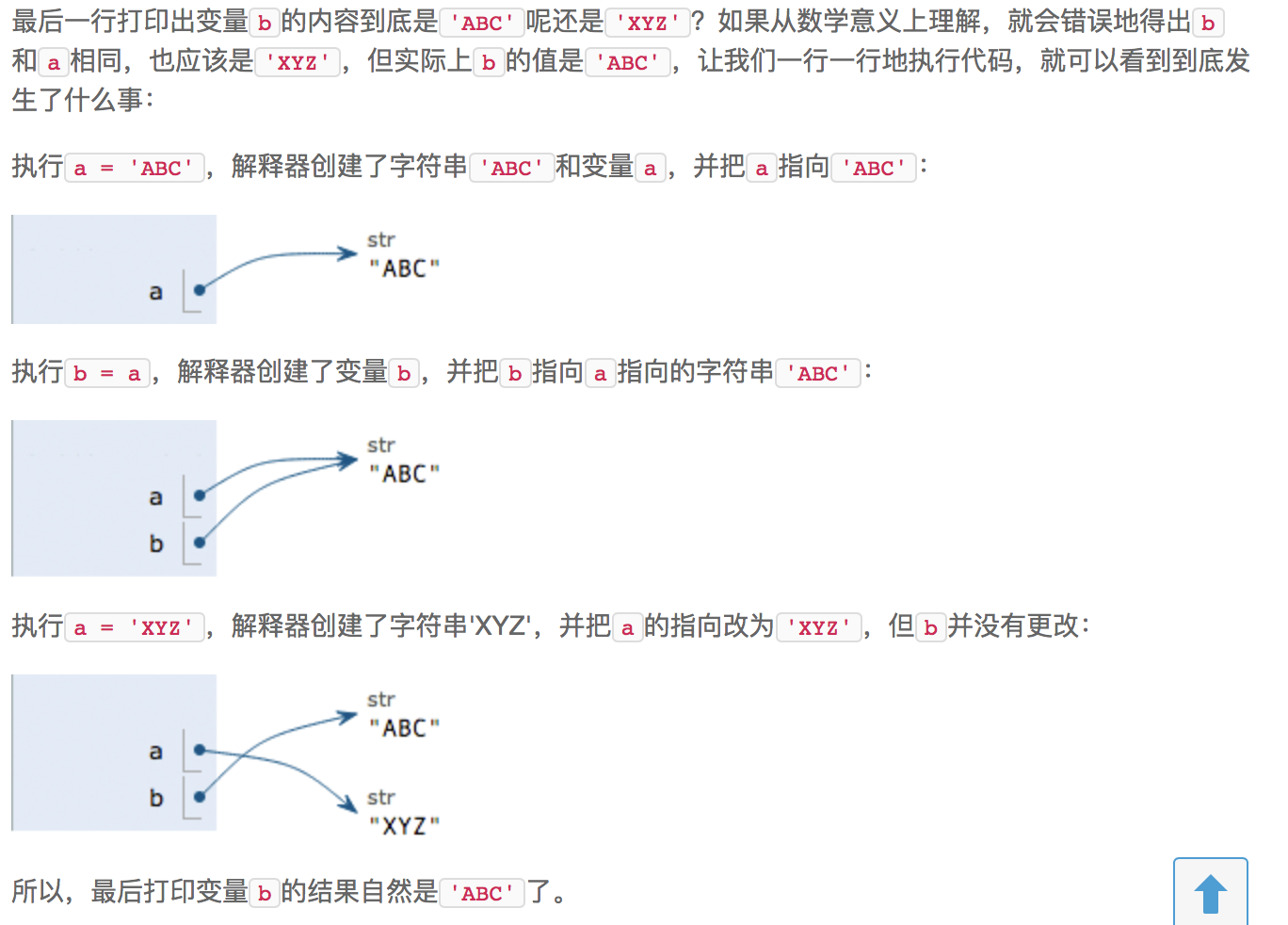
=是赋值语句,可以把任意数据类型赋值给变量,同一个变量可以反复赋值,而且可以是不同类型的变量。这种变量本身类型不固定的语言称之为动态语言,与之对应的是静态语言。静态语言在定义变量时必须指定变量类型,如果赋值的时候类型不匹配,就会报错(例如Java是静态语言),和静态语言相比,动态语言更加灵活。- 最后,理解变量在计算机内存中的表示也非常重要。当我们写a='ABC'时,Python解释器干了两件事:
-
在内存中创建了一个
'ABC'的字符串; -
在内存中创建了一个名为
a的变量,并把它指向'ABC'。如:a = 'ABC'
b = a
a = 'XYZ'
print(b)
-
- 最后,理解变量在计算机内存中的表示也非常重要。当我们写a='ABC'时,Python解释器干了两件事:
- 常量:大写字母表示,如PI
- 补充:关于整数除法。在Python中,有两种除法,一种除法是
/:10/3结果为3.33333333(表示浮点数),即使是两个整数恰好整除,结果也是浮点数;还有一种除法是//,称为地板除,两个整数的除法仍然是整数。
2.字符串和编码
Unicode应运而生。Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。
Unicode标准也在不断发展,但最常用的是用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要4个字节)。现代操作系统和大多数编程语言都直接支持Unicode。新的问题又出现了:如果统一成Unicode编码,乱码问题从此消失了。但是,如果你写的文本基本上全部是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。所以,本着节约的精神,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间:UTF-8编码有一个额外的好处,就是ASCII编码实际上可以被看成是UTF-8编码的一部分,所以,大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作。
总结一下现在计算机系统通用的字符编码工作方式:
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。

- 字符串的编码:在操作字符串时,我们经常遇到
str和bytes的互相转换。为了避免乱码问题,应当始终坚持使用UTF-8编码对str和bytes进行转换。- 在最新的Python 3版本中,字符串是以Unicode编码的,也就是说,Python的字符串支持多语言。
- 对于单个字符的编码,Python提供了
ord()函数获取字符的整数表示,chr()函数把编码转换为对应的字符:如ord('A')结果为65;chr(65)结果为'A',chr(25991)结果为'文'。 - Python对
bytes类型的数据用带b前缀的单引号或双引号表示:x=b'ABC'。以Unicode表示的str通过encode()方法可以编码为指定的bytes。反过来,如果我们从网络或磁盘上读取了字节流,那么读到的数据就是bytes。要把bytes变为str,就需要用decode()方法:b'ABC'.decode('ascii')。如果bytes中包含无法解码的字节,decode()方法会报错;如果bytes中只有一小部分无效的字节,可以传入errors='ignore'忽略错误的字节:b'\xe4\xb8\xff'.decode('utf-8',errors='ignore')。 len()函数计算的是str的字符数,如果换成bytes,len()函数就计算字节数。- 由于Python源代码也是一个文本文件,所以,当你的源代码中包含中文的时候,在保存源代码时,就需要务必指定保存为UTF-8编码。当Python解释器读取源代码时,为了让它按UTF-8编码读取,我们通常在文件开头写上这两行:(第二行注释是为了告诉Python解释器,按照UTF-8编码读取源代码,否则,你在源代码中写的中文输出可能会有乱码。)
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
申明了UTF-8编码并不意味着你的.py文件就是UTF-8编码的,必须并且要确保文本编辑器正在使用UTF-8 without BOM编码。
- 格式化:
- 在Python中,采用的格式化方式和C语言是一致的,用
%实现。%运算符就是用来格式化字符串的。在字符串内部,%s表示用字符串替换,%d表示用整数替换,有几个%?占位符,后面就跟几个变量或者值,顺序要对应好。如果只有一个%?,括号可以省略。 - 另一种方式:format(),但是写起来要复杂得多。
- 在Python中,采用的格式化方式和C语言是一致的,用
3.使用list和tuple
1)list:list是一种有序的集合,可以随时添加和删除其中的元素。如classmates=['M','F']
- 如果要取最后一个元素,除了计算索引位置外,还可以用
-1做索引,直接获取最后一个元素;以此类推,可以获取倒数第2个、倒数第3个。 - list中元素可以是不同类型,还可以包含另一个list
- 如果一个list中一个元素也没有,就是一个空的list,它的长度为0
- list常用操作:
- l.append('a') #追加元素到末尾
- l.pop() #删除末尾元素
- l.pop(i) #删除指定索引位置的元素
- l.insert(1,'a') #插入元素到指定索引的位置
2)tuple: 另一种有序列表叫元组:tuple。tuple和list非常类似,但是tuple一旦初始化就不能修改。
- 不可变的tuple有什么意义?因为tuple不可变,所以代码更安全。如果可能,能用tuple代替list就尽量用tuple。
- tuple所谓的“不变”是说,tuple的每个元素,指向永远不变。即指向
'a',就不能改成指向'b',指向一个list,就不能改成指向其他对象,但指向的这个list本身是可变的! - tuple的陷阱:当你定义一个tuple时,在定义的时候,tuple的元素就必须被确定下来。
- tuple里只有一个元素的时候,为了避免与数学意义上的()的歧义,只有1个元素的tuple定义时必须加一个逗号
,,来消除歧义:t=(1,)。
4.条件判断
- 完整形式:条件判断从上向下匹配。
if <条件判断1>:
<执行1>
elif <条件判断2>:
<执行2>
elif……
else:
<执行n>
5.循环
1)两种表达形式:
- 一种是for...in循环,依次把list或tuple中的每个元素迭代出来: for name in names: 、 for x in [1,2,3]: 等等。 ps:可以通过range(x)函数生成0-x的整数序列。
- 第二种就是while循环
2)关于 break和continue
6.使用dict和set
1) dict
- python内置了字典,类比其他语言中的map,使用键-值存储,具有极快的查找速度。
- 使用:如d={'a':97,'bob':0} 则d['bob']=0
- 判断字典中是否存在key: 'a' in d 或者使用dict提供的get()方法:d.get(……)
- 删除一个key(包括其value): d.pop(key)
-
和list比较,dict有以下几个特点:
- 查找和插入的速度极快,不会随着key的增加而变慢;
- 需要占用大量的内存,内存浪费多。
而list相反:
- 查找和插入的时间随着元素的增加而增加;
- 占用空间小,浪费内存很少。
所以,dict是用空间来换取时间的一种方法。
这个通过key计算位置的算法称为哈希算法(Hash)。要保证hash的正确性,作为key的对象就不能变。在Python中,字符串、整数等都是不可变的,因此,可以放心地作为key。而list是可变的,就不能作为key:
2) set
- set和dict的唯一区别仅在于没有存储对应的value,但是,set的原理和dict一样,所以,同样不可以放入可变对象。
- set可以看成数学意义上的无序和无重复元素的集合,因此,两个set可以做数学意义上的交集、并集等操作。
- 基本操作:s.add(x) s.remove(x)
3) 再议不可变对象
- str是不变对象,而list是可变对象
- 对str使用replace()方法:如a.replace('a','A'),然后将这个新的字符串对象赋值个b变量。
- 以,对于不变对象来说,调用对象自身的任意方法,也不会改变该对象自身的内容。相反,这些方法会创建新的对象并返回,这样,就保证了不可变对象本身永远是不可变的。。
五、函数
- Python不但能非常灵活地定义函数,而且本身内置了很多有用的函数,可以直接调用。
- 函数就是最基本的一种代码抽象的方式。
1.调用函数
- 基础常用:abs()、数据类型转换如int('123') float(……) str(……) bool(1)……
2. 定义函数
- 格式: 定义一个函数要使用
def语句,依次写出函数名、括号、括号中的参数和冒号:,然后,在缩进块中编写函数体,函数的返回值用return语句返回:(如果没有return语句,函数执行完毕后也会返回结果,只是结果为None。return None可以简写为return。)def my_abs(x):
if x >= 0:
return x
else:
return -x - 新文件中导入使用函数:如果你已经把
my_abs()的函数定义保存为abstest.py文件了,那么,可以在该文件的当前目录下启动Python解释器,用from abstest import my_abs来导入my_abs()函数,注意abstest是文件名(不含.py扩展名):
>>>from abstract import my_abs
>>>my_abs(-1)
1
- 空函数:如果想定义一个什么事也不做的空函数,可以用
pass语句:(pass语句什么都不做,那有什么用?实际上pass可以用来作为占位符,比如现在还没想好怎么写函数的代码,就可以先放一个pass,让代码能运行起来。)
def nop():
pass
- 参数检查:如果对my_abs(……)对参数类型做检查,只允许整数和浮点数类型的参数。数据类型检查可以用内置函数
isinstance()实现:
def my_abs(x):
if not isinstance(x,(int,float)):
raise TypeError('bad operand typr!')
- 返回多个值:当在函数体中 return x,y 时,其实返回值是一个tuple!但是,在语法上,返回一个tuple可以省略括号,而多个变量可以同时接收一个tuple,按位置赋给对应的值,所以,Python的函数返回多值其实就是返回一个tuple,但写起来更方便。
3. 函数的参数
Python的函数定义非常简单,但灵活度却非常大。除了正常定义的必选参数外,还可以使用默认参数、可变参数和关键字参数,使得函数定义出来的接口,不但能处理复杂的参数,还可以简化调用者的代码。
1)位置参数:常见
2)默认参数:比如对于power函数,由于我们经常计算x2,所以,完全可以把第二个参数n的默认值设定为2: def power(x, n=2): 这样,当我们调用power(5)时,相当于调用power(5, 2):
设置默认参数时,有几点要注意:
一是必选参数在前,默认参数在后,否则Python的解释器会报错(思考一下为什么默认参数不能放在必选参数前面);
二是如何设置默认参数。
当函数有多个参数时,把变化大的参数放前面,变化小的参数放后面。变化小的参数就可以作为默认参数。

3)可变参数:顾名思义,可变参数就是传入的参数个数是可变的,可以是1个、2个到任意个,还可以是0个。
定义可变参数和定义一个list或tuple参数相比,仅仅在参数前面加了一个*号(def cal(*numbers): )。在函数内部,参数numbers接收到的是一个tuple,因此,函数代码完全不变。但是,调用该函数时,可以传入任意个参数,包括0个参数。
如果已经有一个list或者tuple,要调用一个可变参数怎么办?Python允许你在list或tuple前面加一个*号,把list或tuple的元素变成可变参数传进去:

*nums表示把nums这个list的所有元素作为可变参数传进去。这种写法相当有用,而且很常见。
4) 关键字参数:可变参数允许你传入0个或任意个参数,这些可变参数在函数调用时自动组装为一个tuple。而关键字参数允许你传入0个或任意个含参数名的参数,这些关键字参数在函数内部自动组装为一个dict。
def person(name, age, **kw):
print('name:',name,'age:',age,'other:',kw)
5) 命名关键字参数:和关键字参数**kw不同,命名关键字参数需要一个特殊分隔符*,*后面的参数被视为命名关键字参数。如果函数定义中已经有了一个可变参数,后面跟着的命名关键字参数就不再需要一个特殊分隔符*了;命名关键字参数必须传入参数名,这和位置参数不同。如果没有传入参数名,调用将报错。
def person(name, age, *, city, job):
……
6) 参数组合:在Python中定义函数,可以用必选参数、默认参数、可变参数、关键字参数和命名关键字参数,这5种参数都可以组合使用。但是请注意,参数定义的顺序必须是:必选参数、默认参数、可变参数、命名关键字参数和关键字参数。 如 def f1(a, b, c=0, *args, city, job, **kw)
虽然可以组合多达5种参数,但不要同时使用太多的组合,否则函数接口的可理解性很差。
4.递归函数
使用递归函数需要注意防止栈溢出。在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出。
尾递归调用时,如果做了优化,栈不会增长,因此,无论多少次调用也不会导致栈溢出。
遗憾的是,大多数编程语言没有针对尾递归做优化,Python解释器也没有做优化,所以,即使把上面的fact(n)函数改成尾递归方式,也会导致栈溢出。
六、高级特性
1. 切片
2.迭代
3.列表生成式
4.生成器
5.迭代器
七、函数式编程
1. 高阶函数
2.返回函数
3.匿名函数
4.装饰器
5.片函数
八、模块
1. 使用模块
2.安装第三方模块
九、面向对象编程
1.类和实例
2. 访问限制
3 继承和多态
4. 获取对象信息
5. 实例属性和类属性
十、面向对象高级编程
1.使用__slots__
2. 使用@property
3. 多重继承
4. 定制类
5. 使用枚举类
6. 使用元类
十一、错误、调试和测试
1. 错误处理
2. 调试
3. 单元测试
4. 文档测试
十二、I/O编程
1.文件读写
2.StringIO和BytesIO
3.操作文件和目录
4.序列化
十三、进程和线程
1.多进程
2.多线程
3.ThreadLocal
4. 进程vs线程
5. 分布式进程