Spring Boot是在 2013年推出的新项目,主要用来简化Spring 开发框架的开发、配置、调试、部署工作,同时在项目内集成了大量易于使用且实用的基础框架[[i]]。使用Spring Boot开发项目,可以做到一键启动和部署,整个开发过程得到了很大的简化。SpringBoot可以创建独立的Spring应用程序,使用内嵌的J2EE容器,无需部署WAR文件,通过简单的注解就能自动配置Spring。
如图4-1所示,为微服务体系架构设计图,该体系架构由服务注册中心、服务配置中心、监控中心、服务网关、消息总线、核心系统及GitLab七大模块组成[[ii]],服务网关,注册中心、配置中心、监控中心及核心系统均使用Spring Boot进行开发。
服务网关主要起到路由的功能,通过引入spring-cloud-starter-zuul的jar包,获得zuul的相关服务,在应用主类上通过添加注解@EnableZuulProxy,开启Zuul服务功能,将从外部接入的url请求,路由到相应子系统服务中。Eureka-Server集群由多个Eureka-Server应用服务组成,多个Eureka-Server服务相互发现,形成Eureka-Server集群功能,有效提高系统容灾性能。Config-Server集群由多个Config-Server服务组成,多个Config-Server服务同时注册在Eureka-Server上,缓解配置中心压力,有效提高系统容灾性能。GIT是分布式版本控制系统,在该体系结构中用来保存核心系统加载时所需的所有配置信息。系统使用RabbitMQ作为消息总线,用来实现同步刷新核心系统与GIT仓库中的properties文件。
核心系统使用springBoot进行开发,对外提供系统的基础服务功能,每个工程内嵌tomcat容器,并通过注解自动配置spring。
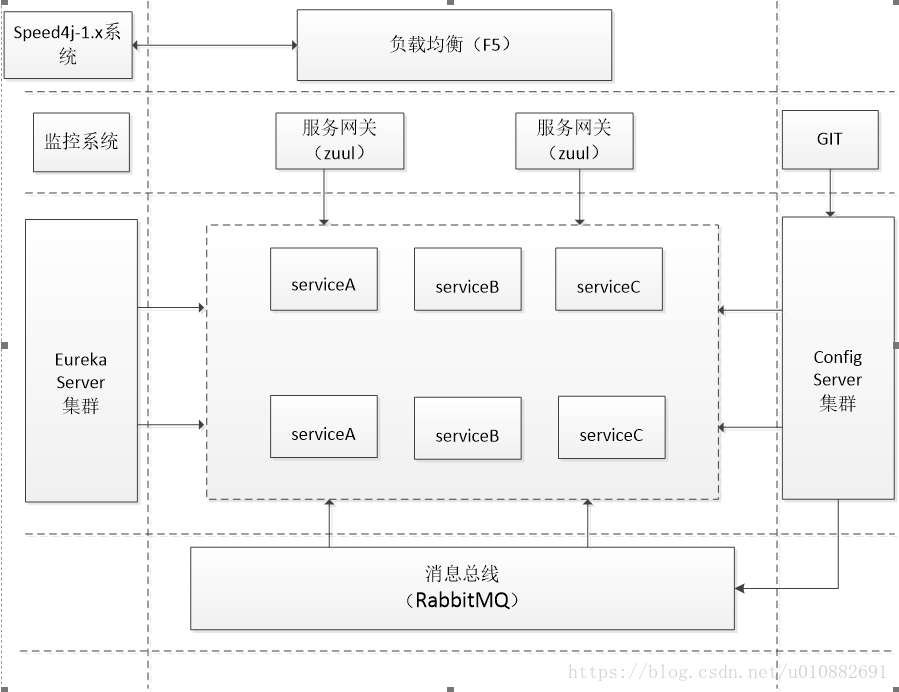
图4-1 微服务系统架构图
服务网关按照服务注册名称将请求转发至对应的应用程序,当注册中心存在多个相同的注册名称时,zuul网关会按照一定的比例关系转发服务请求,从而起到了负载均衡的作用。
在zuul服务网关的pom文件中添加spring boot和spring cloud相关依赖,在应用主类使用@EnableZuulProxy注解开启Zuul服务功能。Pom文件中相关依赖jar包如下:
| name |
version |
| spring-boot-starter-parent |
1.3.5.RELEASE |
| spring-cloud-dependencies |
Brixton.RELEASE |
| spring-cloud-starter-zuul |
1.1.0.RELEASE |
| spring-cloud-starter-eureka |
1.1.0.RELEASE |
application.properties配置信息如下:
| spring.application.name=api-gateway server.port=5555 #serviceId的映射关系 zuul.routes.api-a.path=/api-a/** zuul.routes.api-a.serviceId=service-A zuul.routes.api-b.path=/api-b/** zuul.routes.api-b.serviceId=service-B eureka.client.serviceUrl.defaultZone=http://localhost:1111/eureka/ #线程设置 server.tomcat.max-threads=1000 server.tomcat.min-spare-threads=200 # ribbon超时时间设置 ribbon.ConnectTimeout=3000 ribbon.ReadTimeout=60000 # zuul负载均衡连接数设置 zuul.host.maxTotalConnections=10000 zuul.host.maxPerRouteConnections=10000 zuul.semaphore.maxSemaphores=1000 zuul.eureka.api.semaphore.maxSemaphores=120 zuul.eureka.bcms-service-dsq.semaphore.maxSemaphores=1000 |
服务网关主要起到分压负载和路由的功能,服务网关会通过注册中心获取应用服务的基本信息:包括服务注册名称、服务IP地址,对外暴露的端口等,当外部服务路由到zuul网关时,会按照URL地址执行预先设置的路由策略,例如URL为“http://localhost:8080/api-a/**”,按照路由策略,zuul网关会将URL请求重定向到应用服务名为service-A的服务中去。
-
- 服务注册中心
1、Eureka注册中心配置
首先创建一个基础的Spring Boot工程,然后在pom.xml中引入注册中心所需要的相关依赖JAR包,使用@EnableEurekaServer注解启动一个服务注册中心,提供给其他SpringBoot应用服务进行注册,注册中心包含已经开发完成的前端ui界面,可以直接访问管理界面,对注册的服务进行管理,注册中心页面展示如图4-2所示。Pom文件中相关依赖jar包如下:
| name |
version |
| spring-boot-starter-parent |
1.3.5.RELEASE |
| spring-cloud-starter-eureka-server |
1.1.0.RELEASE |
| spring-cloud-dependencies |
Brixton.RELEASE |
启动类配置如下:
| @EnableEurekaServer @SpringBootApplication public class Application { public static void main(String[] args) { new SpringApplicationBuilder(Application.class).web(true).run(args); } } |
application.properties文件配置如下:
| server.port=1111 eureka.client.register-with-eureka=false eureka.client.fetch-registry=false eureka.client.serviceUrl.defaultZone=http://localhost:${server.port}/eureka/ |
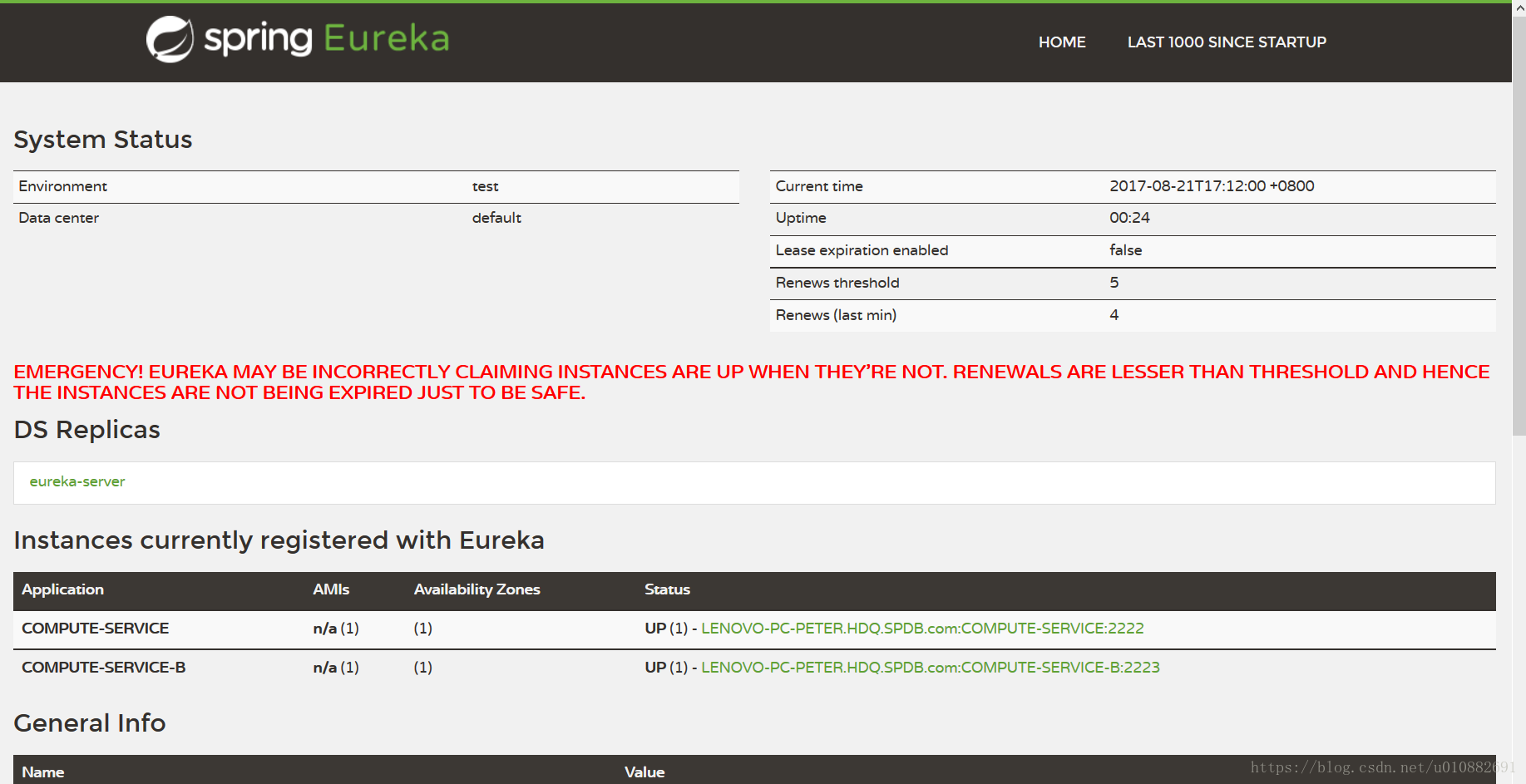
图4-2 Eureka注册中心
微服务注册中心主要用于发现spring boot应用服务,注册中心配置为服务端,各个微服务应用则配置成为客户端,当应用服务启动后,使用心跳机制通过向注册中心地址发送心跳数据包,将应用服务注册到注册中心,同时注册中心接收到应用服务的心跳数据包后,将该应用服务注册到自己的服务列表中,后续通过注册中心和应用服务之间的相互发送数据包来监听应用程序的健康状态,以此来持续维护注册列表的正确性。
2、Eureka注册中心集群配置
Eureka Server支持单个实例和多个实例的配置,如果需要进行注册中心集群化配置则需要同时运行多个实例并通过互相注册来实现高可用部署,以Eureke Server配置文件为例,在其中添加其他可用的serviceUrl来实现注册中心高可用部署。
首先构建双节点的服务注册中心:创建 application-peer1.properties ,作为peer1服务中心的配置,并将serviceUrl指向peer2 ,创建 application-peer2.properties ,作为peer2服务中心的配置,并将serviceUrl指向peer1 。然后在 /etc/hosts 文件中添加对peer1和peer2节点的转换。
| #application-peer1.properties配置信息如下: spring.application.name=eureka-server server.port=1111 eureka.instance.hostname=peer1 eureka.client.serviceUrl.defaultZone=http://peer2:1112/eureka/
#application-peer2.properties配置信息如下: spring.application.name=eureka-server server.port=1112 eureka.instance.hostname=peer2 eureka.client.serviceUrl.defaultZone=http://peer1:1111/eureka/ |
在 /etc/hosts 文件中添加对peer1和peer2的转换 ,具体配置信息如下:
| 127.0.0.1 peer1 127.0.0.1 peer2 |
启动注册中心集群节点peer1和peer2,启动命令如下:
| java -jar eureka-server-1.0.0.jar --spring.profiles.active=peer1 java -jar eureka-server-1.0.0.jar --spring.profiles.active=peer2 |
当启动完成后,我们访问peer1的注册中心, http://localhost:1111/ ,我们可以看到 peer2节点的注册中心被注册到了peer1节点。同样访问peer2的注册中心,http://localhost:1112/ ,能看到 peer1节点被注册到了peer2节点上。此时注册中心高可用集群化配置就完成了。
3、客户端服务注册与发现
首先对客户端进行服务发现功能配置,然后将其注册到设置了多个节点的Eureka Server集群服务中。客户端的application.properties 配置文件内容如下:
| spring.application.name=compute-service server.port=2222 eureka.client.serviceUrl.defaultZone=http://peer1:1111/eureka/,http://peer2:1112/eureka/ |
在application.properties 的配置中主要对 eureka.client.serviceUrl.defaultZone的属性做了改动,将注册中心指向搭建的peer1与peer2两个节点。通过访问 http://localhost:1111/ 和 http://localhost:1112/,可以观察到应用服务被同时被注册到了peer1和peer2节点上。若此时断开peer1节点,由于应用服务同时也向peer2注册,因此在peer2上其他应用程序依然能访问到该服务,这样就实现了高可用服务注册中心对应用服务的发现功能。
1、Config Server配置中心
通过Spring Cloud构建一个配置中心:首先在配置中心服务端的pom.xml中引入spring-cloud-config-server依赖,其次创建Spring Boot的程序主类,并添加@EnableConfigServer注解,开启Config Server的配置服务,最后在application.properties文件中配置应用服务端口、应用服务名称以及gitlib的用户名、密码等信息,如果使用本地文件存储配置数据信息则需要将gitlab配置替换为本地文件路径配置。Pom文件中相关依赖jar包如下:
| name |
version |
| spring-boot-starter-parent |
1.3.5.RELEASE |
| spring-boot-starter-test |
1.3.5.RELEASE |
| spring-cloud-dependencies |
Brixton.RELEASE |
| spring-cloud-starter-eureka |
1.1.0.RELEASE |
| spring-cloud-config-server |
1.1.0.RELEASE |
application.properties中服务配置信息以及gitlib配置信息如下:
| spring.application.name=config-server server.port=3333 #gitlab保存properties文件数据 spring.cloud.config.server.git.uri=https://github.com/zhangle871012/project/ spring.cloud.config.server.git.searchPaths=config-repo spring.cloud.config.server.git.username=zhangle spring.cloud.config.server.git.password=zle84349 #本地文件系统保存properties文件数据 spring.profiles.active=native, spring.cloud.config.server.native.searchLocations=file:F:/properties/ |
2、Config Server高可用配置中心集群
高可用配置中心集群配置如下,首先在pom.xml的dependencies节点中新增spring-cloud-starter-eureka依赖,用来注册服务,其次在bootstrap.properties的配置文件中添加关于集群化的配置信息,其中eureka.client.serviceUrl.defaultZone=http://localhost:1111/eureka/参数指定了服务注册中心地址,主要用于服务的注册与发现,spring.cloud.config.discovery.enabled参数设置为true,实现了通过服务来访问配置中心的功能,spring.cloud.config.discovery.serviceId参数指定了多个节点的配置中心在注册中心所注册的应用服务名称。spring.application.name和spring.cloud.config.profile参数用来定位Gitlab中所保存的配置信息资源,然后在应用主类中增加@EnableDiscoveryClient注解,用来发现配置中心服务,高可用配置中心结构如图4-3所示。Pom文件中相关依赖jar包如下:
| name |
version |
| spring-boot-starter-parent |
1.3.5.RELEASE |
| spring-cloud-starter-eureka |
1.1.0.RELEASE |
| spring-cloud-dependencies |
Brixton.RELEASE |
| spring-cloud-starter-config |
1.1.0.RELEASE |
| spring-boot-starter-web |
1.1.0.RELEASE |
bootstrap.properties文件配置如下:
| spring.application.name=didispace server.port=3333 eureka.client.serviceUrl.defaultZone=http://localhost:1111/eureka/ spring.cloud.config.discovery.enabled=true spring.cloud.config.discovery.serviceId=config-server spring.cloud.config.profile=dev |
 |

图4-3 高可用配置中心集群
3、配置中心客户端配置
在完成并验证了配置中心服务端功能后,需要在springboot创建的应用服务中通过以下方法获取配置中心数据信息:首先创建一个Spring Boot应用,在pom.xml中引入spring-cloud-starter-config依赖jar包,其次创建bootstrap.properties配置文件,用来指向config server配置中心 ;最后创建一个TestController测试类来返回配置中心的from属性值,在配置中心的properties文件中添加from=bootTest,通过@Value("${from}")绑定配置服务中配置的from属性,如果返回bootTest,则客户端配置正确。Pom文件中相关依赖jar包如下:
| name |
version |
| spring-boot-starter-parent |
1.3.5.RELEASE |
| spring-boot-starter-test |
1.3.5.RELEASE |
| spring-cloud-dependencies |
Brixton.RELEASE |
| spring-cloud-starter-config |
1.1.0.RELEASE |
| spring-boot-starter-web |
1.1.0.RELEASE |
bootstrap.properties配置如下:
| spring.application.name=didispace spring.cloud.config.profile=dev spring.cloud.config.label=master spring.cloud.config.uri=http://localhost:3333/ server.port=2222 |
TestController测试类具体实例如下:
| @RefreshScope @RestController class TestController { @Value("${from}") private String from; @RequestMapping("/from") public String from() { return this.from; } } |
配置中心为各个应用服务提供了一个外部配置环境。各个SpringBoot应用服务的相关配置参数可以统一放在应用外部进行配置,默认采用gitlab来存储配置信息。
配置中心主要起到一个中间件的作用,应用服务系统中所有的相关properties文件内容被存储到一个特定的properties文件中,该文件被保存在文件系统或GITLIB的服务器上。配置中心作为服务端从GITLIB上读取文件内容,应用服务系统作为客户端,通过请求配置中心的URL地址获取配置中心数据,当应用服务获取配置文件内容后便可正常加载服务。通过配置中心来获取各个应用服务的配置参数,保证了服务的安全性和可靠性,当配置参数需要调整时只需要对GITBLA中的配置文件进行修改,便可实现各个应用服务配置参数的同步更新。
RabbitMQ主要用于将GIT中被修改的配置参数信息同步到各个应用服务系统,各个应用服务系统通过同一个消息队列获取跟新的配置参数值。以此来保证系统配置文件的一致性。在该微服务架构体系中,RabbitMQ被安装在suse linux enterprise 11上,所需相关安装包信息如下:
| rabbitmq-server相关安装包名称 |
| openssl-1.0.2h.tar |
| otp_src_18.2.1.tar |
| rabbitmq-server-generic-unix-3.6.9.tar |
| unixODBC-2.3.2.tar |
Springboot应用服务在使用RabbitMQ进行配置数据同步刷新时,需要在b客户端应用服务的pom.xml文件中增加spring-cloud-starter-bus-amqp依赖,同时在application.properties配置文件中增加关于RabbitMQ的连接地址和用户信息配置。Pom.xml文件中依赖jar包信息如下:
| name |
version |
| spring-cloud-starter-bus-amqp |
1.1.0.RELEASE |
application.properties配置文件内容如下:
| spring.rabbitmq.host=localhost spring.rabbitmq.port=5672 spring.rabbitmq.username=springcloud spring.rabbitmq.password=123456 |
使用命令“rabbitmq-server start”启动RabbitMQ,然后在浏览器中输入http://10.129.41.82:55672 就能够进入到RabbitMQ管理界面,默认的用户名和密码是guest 和 guest。RabbitMQ支持点对点和发布订阅两种模式的消息传递,可根据业务需要进行配置。
构建一个Spring Boot项目,并在pom.xml中加入如下具体依赖内容,Pom文件中相关依赖jar包如下:
| name |
version |
| spring-boot-starter-parent |
1.3.5.RELEASE |
| spring-boot-starter-web |
1.3.5.RELEASE |
| spring-cloud-dependencies |
Brixton.RELEASE |
| spring-cloud-starter-eureka |
1.1.0.RELEASE |
| spring-cloud-starter-ribbon |
1.1.0.RELEASE |
在主函数中通过添加@EnableDiscoveryClient注解来获得发现服务的能力:首先创建RestTemplate类对象实例,添加@LoadBalanced注解开启负载均衡能力;然后创建ConsumerController类使用RestTemplate类对象来消费服务注册名为COMPUTE-SERVICE的sum服务请求。
| @SpringBootApplication @EnableDiscoveryClient public class RibbonApplication { @Bean @LoadBalanced RestTemplate restTemplate() { return new RestTemplate(); } public static void main(String[] args) { SpringApplication.run(RibbonApplication.class, args); }} |
| @RestController public class ConsumerController { @Autowired RestTemplate restTemplate; @RequestMapping(value = '/add', method = RequestMethod.GET) public String add() { return restTemplate.getForEntity('http://COMPUTE-SERVICE/sum?a=10&b=20', String.class).getBody(); }} |
服务消费功能需要依赖注册中心的服务发现能力,通过创建RestTemplate类对象,使用rest方式来调用其他应用服务所提供的接口功能,实现了SpringBoot应用服务间的相互调用。
断路器的主要作用是对线程因调用故障服务而长时间被占用不释放的情况提供一种容错机制,避免故障在系统中蔓延。
首先在SpringBoot应用服务中新建ComService类,在应用服务的pom.xml文件中引入hystrix相关依赖jar包,然后在使用消费服务的函数上增加@HystrixCommand注解并指定交易请求的回调方法。注解中的fallbackMethod = "addServiceFallback"指明当服务请求调用失败或出现异常时,则调用addServiceFallback()方法,执行异常处理逻辑。Pom文件中相关依赖jar包如下:
| name |
version |
| spring-cloud-starter-hystrix |
1.1.0.RELEASE |
断路器执行实例代码如下:
| @Service public class ComService{ @Autowired RestTemplate restTemplate; @HystrixCommand(fallbackMethod = "fallback") public String addService() { return restTemplate.getForEntity("http://COMPUTE-SERVICE/add?a=10&b=20", String.class).getBody(); } public String fallback () { return "error"; } } |
当微服务系统并发压力很大时,在SpringBoot应用服务系统相互调用的过程中,个别交易请求未能被系统及时处理或请求的应用服务系统宕机等,针对以上情况,使用断路机制能有效的对异常情况进行及时处理,向调用方返回一个错误响应,防止线程的长时间等待。当请求调用失败时通过回调函数,可对未处理的请求进行重定向或将请求信息进行备份,防止数据丢失和信息不一致情况的发生。
监控系统是微服务架构体系的重要组成部分,主要用于对各个spring boot应用服务的环境变量、jvm、日志、内存、CPU、交易线程、审计(auditing)、健康度、数据采集、sql执行计划、tps阀值等进行监控,同时实现对分布式服务调用的跟踪功能,通过监测有多少跟踪请求通过每个服务及每次请求服务的处理时间来了解整个系统的实时状况。监控系统架构设计图,如图4-5所示:
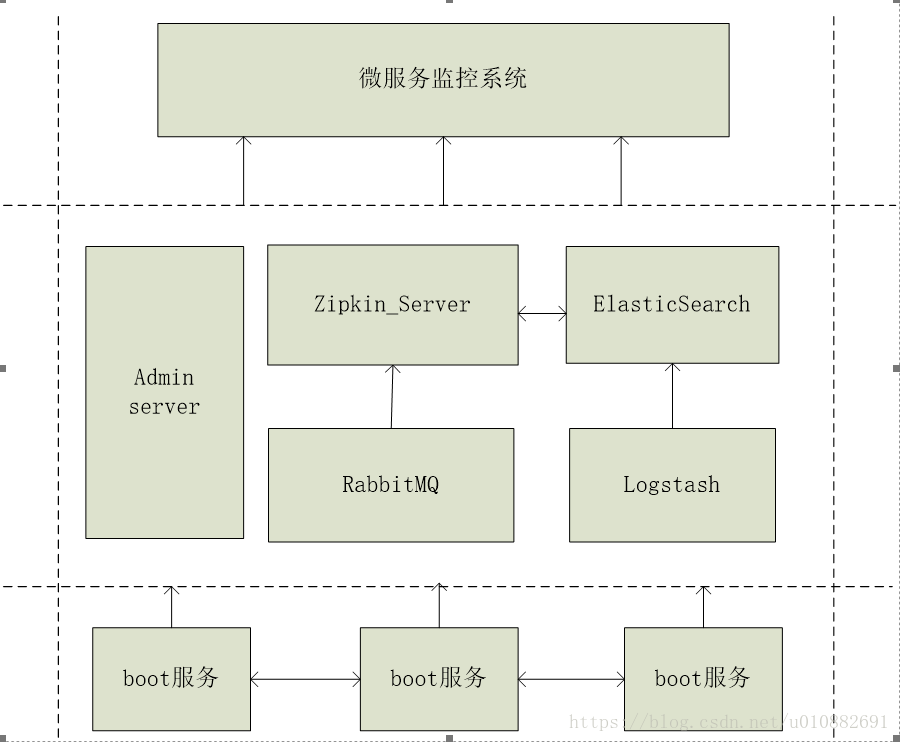
图4-5 监控中心架构设计图
| 功能模块 |
描述 |
| AdminServer |
adminServer主要用于采集Boot应用服务中的环境变量、日志、metrics、jvm、内存、CPU、交易线程、审计(auditing)、健康度信息。 |
| RabbitMQ |
RabbitMQ是一种优秀的消息队列管理中间件,在监控系统中主要用于存储各个分布式Boot服务所产生的服务调用链路关联关系信息,用于监控中心消费。 |
| ZipkinServer |
ZipkinServer主要用于分布式服务调用链路的跟踪,在该监控系统中主要用来消费RabbitMQ消息队列上的各个Boot服务调用关联关系数据。 |
| EL(elasticSearch/logstash) |
EL(elasticSearch/logstash)主要用于日志信息的采集和分析处理。在该监控系统中,EL主要用于收集分布式Boot应用服务所产生的服务请求次数、一分钟,五分钟,十五分钟的TPS平均值,提供给监控系统进行分析展示。 |
监控服务系统Pom.xml文件配置
| name |
version |
| spring-boot-starter-parent |
1.4.2.RELEASE |
| spring-boot-admin-server |
1.4.4 RELEASE |
| spring-cloud-sleuth-zipkin-stream |
1.2.0 RELEASE |
| spring-cloud-starter-stream-rabbit |
1.2.0.RELEASE |
| zipkin-autoconfigure-storage-elasticsearch-http |
1.24.0 |
| zipkin |
1.24.0 |
| spring-cloud-dependencies |
Camden.SR3 |
将spring-boot-admin-server的jar包引入到监控中心,此时各个spring boot服务与监控中心通过心跳机制相互监听,监控中心通过spring-boot-admin-server的jar包获取监控数据信息,例如:页面需要展示Metrics的数据信息,此时可以使用ajax的get通讯方式访问URL: http://localhost:5555/api/applications/3d7a4702/metrics,就可以获取被监控应用服务返回的json格式metrics数据。
点击左侧的菜单admin信息,会展示所有注册到监控中心的应用服务。具体内容如图4-6所示,点击注册列表中的应用服务即可进看到该应用服务的具体监控内容,包括Detail、Metrics、Environment、Logging、DataSource、SQL、TPS等菜单项。
监控中心Detail菜单项具体用于监控该boot服务中的健康度、内存、jvm等信息,Metrics菜单项展示内容包括Counter和Gauge的数据,Environment菜单项展示内容包括端口和系统参数数据,Logging菜单项,如图4-7所示主要功能是对各个被监控Boot应用服务日志级别进行动态调整,并且可以对不同的第三方依赖jar包,按照不同的级别进行调整,从而控制高并发时期日志大量输出的问题。
监控具体接口如下:
| Journal信息获取 |
|
| 输入 |
输出 |
| Json字符串: |
|
| metrics数据信息获取 |
|
| 输入 |
输出 |
| http://localhost:5555/api/applications/3d7a4702/metrics get请求方式 |
Json字符串: |
| Environment环境变量信息获取 |
|
| 输入 |
输出 |
| Json字符串: |
|
| Logging日志信息获取 |
|
| 输入 |
输出 |
| http://localhost:5555/api/applications/3d7a4702/jolokia/ Content-Type: text/plain post请求数据: {"attribute":"LoggerList","mbean":"ch.qos.logback.classic:Name=default,Type=ch.qos.logback.classic.jmx.JMXConfigurator","type": "read"} |
Json字符串:
|
图4-6 监控中心注册列表
图4-7 监控中心Logging数据展示图
Druid是一个jdbc组件,可以监控数据库的访问性能,能够详细统计sql的执行性能,并提供sql的执行日志,对于线上分析数据库访问性能很有帮助[[iii]]。要实现对各个Boot应用服务的数据源及sql执行情况的监控,需要在Boot应用服务中引入Druid的相关jar包,同时添加对Servlet和Filter的配置处理,具体配置内容参考下文,监控中心添加Boot应用服务的Druid数据查询接口,用于前端页面数据展示。
监控中心DataSource菜单项展示内容包括数据源的用户名、连接地址、数据库类型、驱动类名、Filter类名、最大连接数等数据信息,具体内容如图4-8所示。监控中心SQL菜单项展示内容包括SQL语句、执行数、执行时间、读取行数、最大并发、执行时间分布等数据信息。
Boot客户端应用服务Pom.xml文件配置:
| name |
version |
| Druid |
1.0.18 |
配置Servlet和Filter
| #配置Servlet @SuppressWarnings("serial") @WebServlet(urlPatterns = "/druid/*", initParams={ @WebInitParam(name="allow",value="192.168.16.110,127.0.0.1"), @WebInitParam(name="deny",value="192.168.16.111"), @WebInitParam(name="loginUsername",value="shanhy"),// 用户名 @WebInitParam(name="loginPassword",value="shanhypwd"),// 密码 @WebInitParam(name="resetEnable",value="false") }) public class DruidStatViewServlet extends StatViewServlet { } 配置Filter /** * Druid的StatFilter */ @WebFilter(filterName="druidWebStatFilter",urlPatterns="/*", initParams={ @WebInitParam(name="exclusions",value="*.js,*.gif,*.jpg,*.bmp,*.png,*.css,*.ico,/druid/*")// 忽略资源 }) public class DruidStatFilter extends WebStatFilter { } |
Druid数据监控具体接口如下:
| 数据源信息获取 |
|
| 输入: |
输出: |
| http://localhost:2222/springboot/druid/datasource.json get请求发送 |
Json字符串: |
| SQL监控 |
|
| 输入: |
输出: |
| http://localhost:2222/springboot/druid/sql.json?orderBy=SQL&orderType=desc&page=1&perPageCount=1000000&get请求发送 |
Json字符串: |
图4-8 监控中心DataSource数据展示图
1、客户端MetricConfig配置
通过Slf4jReporter类完成metrics数据信息采集,将metrics数据信息写入日志文件中,由于系统运行时日志是按照分线程方式进行打印,所以该metrics数据信息保存在目录“Weblogic\threadlogs\metrics-logger-reporter-thread-1.log”文件中。
| @Configuration public class MetricConfig { @Bean public MetricRegistry metrics() { return new MetricRegistry(); } // SLF4J Reporter @Bean public Slf4jReporter slf4jReporter(MetricRegistry metrics)throws Exception{ return Slf4jReporter.forRegistry(metrics) .outputTo(LoggerFactory.getLogger("demo.metrics")) .convertRatesTo(TimeUnit.SECONDS) .convertDurationsTo(TimeUnit.MILLISECONDS) .build(); } /** * TPS 计算器 */ @Bean public Meter requestMeter(MetricRegistry metrics) { return metrics.meter("request"); } |
2、Logstash获取TPS日志文件数据
Logstash中间件在该监控系统中的主要作用是获取分布式Boot服务的一分钟、五分钟、十五分钟的平均TPS数据信息。这些TPS信息被写入到Weblogic\threadlogs\metrics-logger-reporter-thread-1.log文件中。Logstash的作用就是在系统运行过程中实时拉取该文件的数据信息,并将TPS统计信息推送到elasticsearch服务程序中。
为logstash创建Rabbitmq.conf配置文件,实现从应用服务器特定路径(例如:/Weblogic/threadlogs/metrics-logger-reporter-thread-1.log)拉取TPS统计信息,然后推送到elasticsearch服务程序中,用于对采集到的TPS日志文件进行分析处理。
Rabbitmq.conf配置文件具体内容如下
| input{ file{ codec => plain{ charset =>"UTF-8" } type =>"cluster" path =>"/Weblogic/threadlogs/metrics-logger-reporter-thread-1.log" start_position =>"beginning" } } filter{ grok{ patterns_dir => "/home/logsatsh-2.4.0/patterns/test01.txt" match=> ["message","%{TIMESTAMP_ISO8601:logdate}\s?%{GREEDYDATA:logs}"] } urldecode{ all_fields => true } date { match => ["logdate", "yyyy-MM-dd HH:mm:ss.SSS"] target => "@timestamp" } mutate { remove_field => ["logdate"] } } output{ elasticsearch { hosts => "10.129.39.154" index => "logstash-%{type}-%{+YYYY.MM.dd}" document_type => "%{type}" workers => 10 template_overwrite => true } }
|
MainController是自定义的一个测试类,在该测试类的交易入口处调用requestMeter.mark()方法,在应用服务启动时,当有请求调用该接口时就可以将交易请求的TPS数据信息记录到日志文件中,用于监控系统进行统计。
| @Controller public class MainController { @Resource private Meter requestMeter; @RequestMapping("/hello") @ResponseBody public String helloWorld() { requestMeter.mark(); return "Hello World"; } } |
在应用服务启动类中创建Slf4jReporter类对象,并设置打印频度为1秒,具体配置信息如下:
| public static void main(String[]args){ ApplicationContext ctx = SpringApplication.run(MicroServiceApplication.class, args); //打印到日志文件 Slf4jReporter slf4jReporter = ctx.getBean(Slf4jReporter.class); slf4jReporter.start(1, TimeUnit.SECONDS); } |
tps日志文件数据内容
| 日志数据输出 |
| 2017-07-22 12:25:10.956 [metrics-logger-reporter-thread-1] INFO metrics - type=METER, name=request, count=30, mean_rate=9.993765845559222, m1=0.0, m5=0.0, m15=0.0, rate_unit=events/second 2017-07-22 12:25:13.957 [metrics-logger-reporter-thread-1] INFO metrics - type=METER, name=request, count=60, mean_rate=9.996409711147033, m1=10.0, m5=10.0, m15=10.0, rate_unit=events/second |
日志文件内容描述如下:
| metrics - type=METER |
metrics – type类型 |
| name=request |
名称 |
| count=329 |
交易个数 |
| mean_rate=9.96890026122985 |
TPS平均比率 |
| m1=9.98528746205226 |
1分钟TPS个数 |
| m5=9.996748929332076 |
5分钟TPS个数 |
| m15=9.998898108257805 |
15分钟TPS个数 |
| rate_unit=events/second |
TPS统计单位(事务/每秒) |
3、TPS动态图像展示
如图4-9所示,是监控中心TPS动态视图,该视图展示了应用服务每一分钟、五分钟、十五分钟的TPS平均数值信息,通过点击右上角的图例,可以对三种TPS统计信息进行选择性的展示,该视图时间轴跨度为10秒,后台程序从ElasticSearch中获取最新的tps交易统计信息,以向前滚动方式展示实时TPS统计信息。
图4-9 TPS统计图
1、服务端和客户端配置
使用zipkin实现分布式交易数据跟踪,需要对客户端和服务端分别进行配置,添加相应的第三方jar包,各个客户端的Boot应用服务会采集调用自身的交易跟踪信息,并把数据信息传输到rabbitMQ的消息队列中,然后由监控系统从rabbitMQ的消息队列中消费数据,并写入到elasticsearch中,实现对各个分布式服务的交易跟踪数据保存处理,便于后续的交易跟踪查找。
监控系统(服务端)的Pom.xml文件配置如下:
| name |
version |
| spring-boot-starter-parent |
1.4.2.RELEASE |
| spring-cloud-sleuth-zipkin-stream |
1.2.0 RELEASE |
| spring-cloud-starter-stream-rabbit |
1.2.0.RELEASE |
| zipkin-autoconfigure-storage-elasticsearch-http |
1.24.0 |
| Zipkin |
1.24.0 |
| spring-cloud-dependencies |
Camden.SR3 |
监控系统(服务端)的application.properties文件中需要添加对RabbitMQ和ElasticSearch的配置管理,具体配置参数如下:
| #elasticsearch配置信息 spring.sleuth.enabled=false zipkin.storage.StorageComponent=elasticsearch zipkin.storage.type=elasticsearch zipkin.storage.elasticsearch.cluster=my-application zipkin.storage.elasticsearch.hosts=192.168.127.129:9200 zipkin.storage.elasticsearch.max-requests=64 zipkin.storage.elasticsearch.index=zipkin zipkin.storage.elasticsearch.index-shards=5 zipkin.storage.elasticsearch.index-replicas=1 ##rabbitmq配置信息 spring.sleuth.sampler.percentage=1.0 spring.rabbitmq.host=10.129.41.83 spring.rabbitmq.port=5672 spring.rabbitmq.username=admin spring.rabbitmq.password=admin spring.rabbitmq.virtualHost=/ |
Boot应用服务(客户端)pom.xml文件配置如下:
| name |
version |
| spring-boot-starter-parent |
1.4.2.RELEASE |
| spring-cloud-sleuth-zipkin-stream |
1.1.0 RELEASE |
| spring-cloud-starter-stream-rabbit |
1.1.1.RELEASE |
| spring-cloud-starter-sleuth |
1.1.0.RELEASE |
| spring-cloud-dependencies |
Camden.SR3 |
Boot应用服务(客户端)的application.properties文件中需要添加对RabbitMQ的配置管理,具体配置参数如下:
| #rabbitmq配置信息 spring.sleuth.sampler.percentage=1.0 spring.rabbitmq.host=10.129.41.83 spring.rabbitmq.port=5672 spring.rabbitmq.username=admin spring.rabbitmq.password=admin spring.rabbitmq.virtualHost=/ |
客户端测试代码主要实现服务A分别调用服务B和服务C的请求处理逻辑,程序执行结束后,交易过程的执行信息包括交易请求耗时及交易调用过程会被记录在elasticsearch中,用于监控系统进行跟踪查找,测试代码如下:
| @SpringBootApplication public class StreamServiceApplication { @Bean public RestTemplate restTemplate() { return new RestTemplate(); } public static void main(String[] args) { SpringApplication.run(StreamServiceApplication.class, args); } } @RestController class HiController { @Autowired private RestTemplate restTemplate; private String urlService1="http://localhost:9983"; private String urlService2="http://localhost:9984"; @RequestMapping("/service") public String service1() throws Exception { String s1 = this.restTemplate.getForObject(urlService1 + "/service1", String.class); String s2 = this.restTemplate.getForObject(urlService2 + "/service2", String.class); return "s1:["+s1+"],s2:["+s2+"]"; } } |
2、RabbitMQ配置
为RabbitMQ配置消息交换机(Exchange),设定为发布订阅模式,然后添加消息队列,并将消息交换机绑定到队列中,以#号作为交换机到消息队列的路由规则[[iv]]。Boot应用服务作为消息生产者连接到RabbitMQ的消息通道中,当RabbitMQ接收到消息后会按照路由规则将消息分发到消息队列中,用于监控中心消费。
3、ElasticSearch安装与配置
ElasticSearch作为一个存储介质,具有对数据进行搜索和分析处理的能力,在监控系统架构体系中主要用于保存监控中心传送的分布式交易跟踪数据信息。
ElasticSearch的安装配置过程如下:
- 解压tar -zxvf elasticsearch-2.4.1.tar.gz;
- 创建组test,给test组下添加用户speed,授权用户speed处理elasticsearch-2.4.1的权限;
- 修改配置文件:vi elasticsearch-2.4.1/config/elasticsearch.yml包括集群名称、节点名称、网络主机、HTTP端口等[[v]];
- 在bin目录下安装head、bigdesk插件。
- 使用非root用户进行启动检测。
3、Zipkin数据跟踪管理
Zipkin分布式数据跟踪管理由数据跟踪和视图跟踪两个菜单项组成,其中数据跟踪用于展示特定时间段内不同Boot服务处理的交易请求情况,当输入Start time 和End time后,点击查询跟踪按钮,后台程序会远程调用elasticsearch的API接口,获取Elasticsearch中存储的交易跟踪信息。如图4-10所示,该列表详细记录了应用服务每次交易请求个数及请求的耗时情况。视图跟踪将具体交易的数据流向以流程图的方式进行展示,其中每个节点对应一个Boot应用服务,服务与服务之间的射线指明了交易请求的数据流向。
图4-10数据跟踪
微服务系统架构使用Docker创建各个应用程序的微服务镜像,并由docker对各个容器进行集中管理,因此该部署环境需要安装Centos操作系统宿主机和Docker运行环境。
| Application_name |
version |
| CentOS7系统 |
内核版本3.10 |
| Docker |
1.12.0 |
| epel-release |
7.6 |
| python-pip |
8.1.2 |
| Docker-Compose |
1.8.1 |
| JDK |
1.8 |
以上是安装微服务部署环境的相关软件版本,CentOS7系统是安装的宿主机操作系统,Docker工具则安装在宿主机上,为了实现docker的集装箱式部署,需要安装Docker-Compose软件,安装过程中需要依赖epel-release和python-pip。
相关安装指令如下:
| yum -y install epel-release |
安装epel-release包 |
| yum install python-pip |
安装python-pip包 |
| pip install --upgrade pip |
对安装好的pip进行升级 |
| pip install docker-compose |
安装docker-compose |
| docker-compose --version |
查看docker-compose版本信息 |
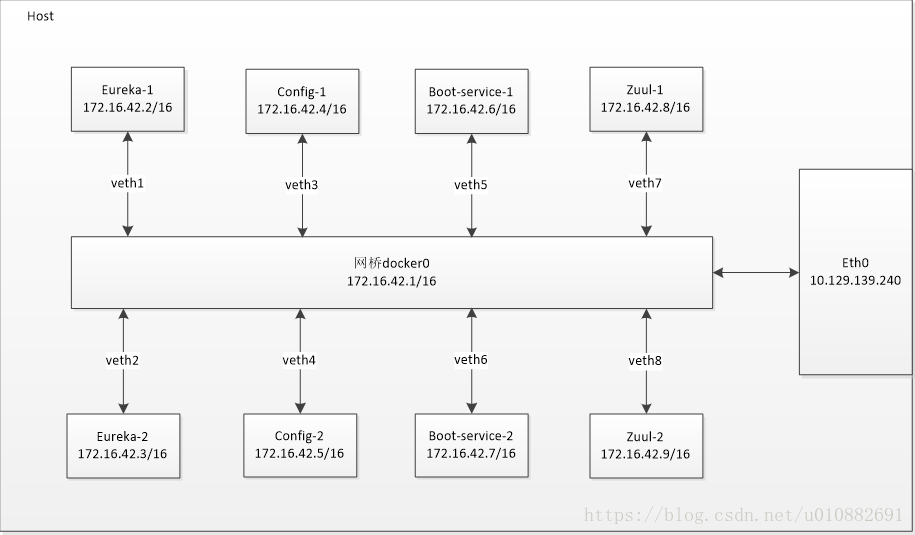
图6-1 Docker微服务环境部署图
如图6-1所示,是微服务在Docker上的部署图,具体描述如下:
- 使用Centos7系统创建宿主机,分配IP为10.129.139.240;
- 宿主机安装Docker后获得的Docker网桥IP为172.16.42.1;
- 在Docker中创建基础镜像,该镜像包含JDK及环境变量的基本配置。
- 创建dockerfile文件和Docker-Compose文件,同时将jdk及各个应用服务的jar包挂载到centos操作系统的宿主机上。1.Dockerfile文件作用是通过基础镜像centos_jdk来创建微服务各个镜像文件;2.Docker-Compose文件作用是创建容器,启动各个微服务镜像,配置网络端口映射关系,解决服务间相互依赖关系。
- 启动Docker-Compose文件实现集装箱式部署;1创建Eureka镜像、Config镜像、zuul镜像、Boot-service镜像,同时启动容器运行各个镜像文件。2创建容器,启动各个微服务镜像,配置网络端口映射关系,解决服务间相互依赖关系。
- 在容器启动后Docker网桥会为每个容器分配一个内部IP地址。
当微服务在Docker上成功部署后,登陆注册中心便可观察到Docker上成功启动的微服务实例,具体实例列表展示如图6-2所示:
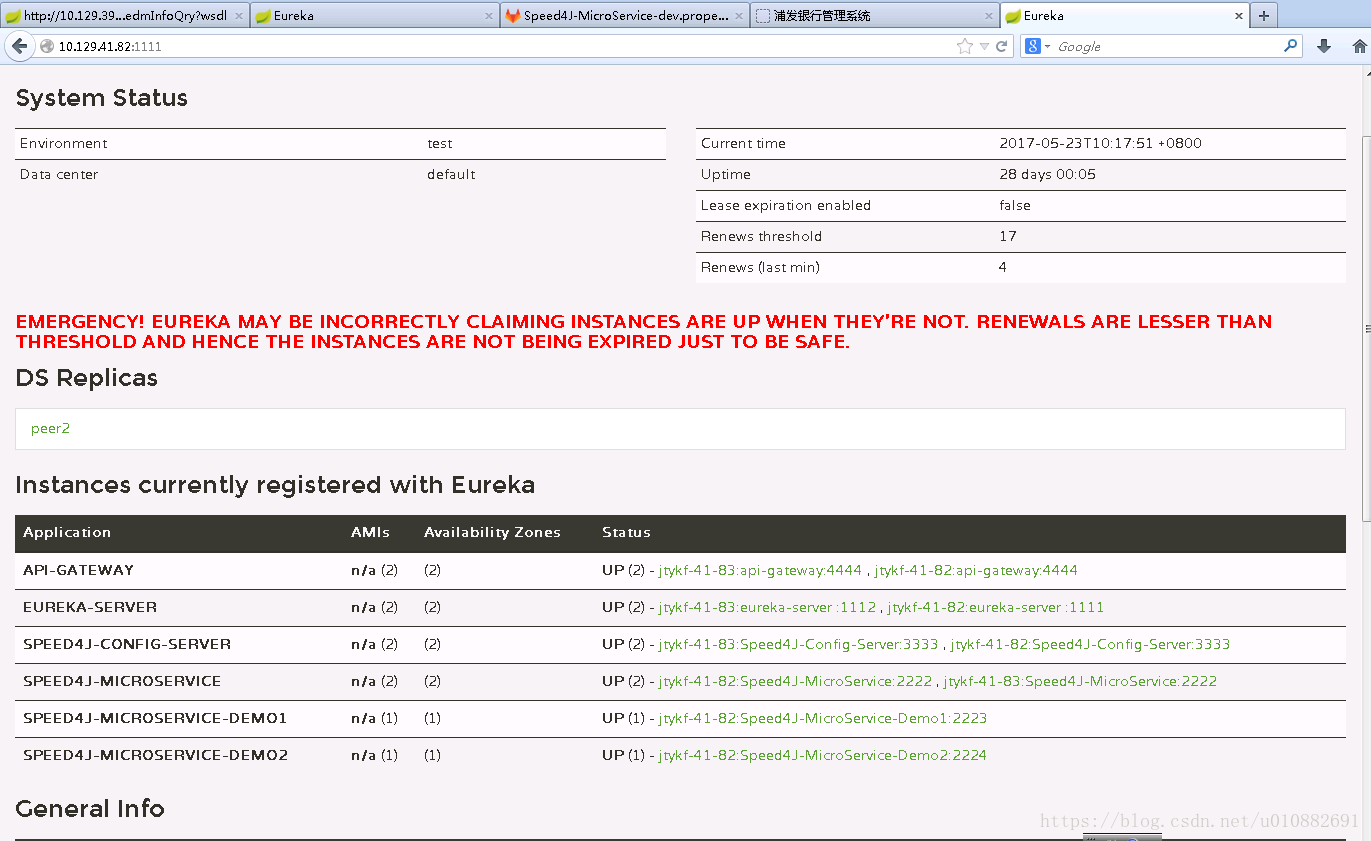
图6-2 注册中心列表展示图
[[i]] 王永和,张劲松,邓安明,周智勋. Spring Boot研究和应用[J]. 信息通信,2016,(10):91-94. [2017-09-18].
[[ii]] 王磊 . 微服务架构与实践 [M]. 西安:电子工业出版社, 2016.
[[iii]] 王明帅. 基于J2EE架构的校园课评系统的设计与实现[D].西安电子科技大学,2014.
[[iv]] RabbitMQ实战:高效部署分布式消息队列 [M].中国工信出版社 Alvaro Videla Jason J. W. Williams 2015.10.
[[v]] ELK stack 权威指南[M].机械工业出版社,饶琛琳 2015.9.