哈希简介
我们首先来简单介绍一下什么是哈希(以下简称hash),hash本质来说就是映射,或者说是键值对key-value,不同的hash之间不过就是实现key-value映射的算法不同,例如java中计算对象的hashcode值会有不同的算法,常用于各种分布式存储分片的id取模算法等,都属于hash算法。
面临的问题
一个算法的出现一定是为了解决某个问题或者是某类问题,理解算法解决了什么样的问题非常有助于我们理解算法本身,那么一致性哈希是为了解决什么样的问题呢?我们首先来看一下普通的hash算法会遇到什么样的问题,我们以id取模算法为例,这种算法经常被用到分布式存储的分片算法中:
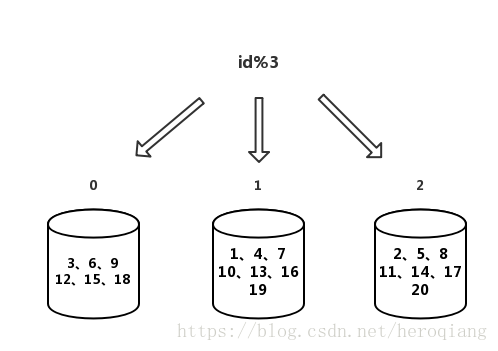
如图所示,假如我们以id % 3作为分片条件,有1-20这些元素,这样这20个元素会按照与3取模的结果分布在0、1、2这三个片中,一切看起来都简单又和谐,但随着业务的发展,我们可能需要扩容,需要再加一个片,我们需要把算法换成id%4,这个时候会发生什么样的变化呢?

对比两个图,我们发现,扩容了一个分片之后,百分之七八十的的数据都发生了迁移,大规模的数据迁移就是这个算法的缺点所在。如果是我们示例中的这种小规模数据,可能影响还不是很大,但是在企业级应用中,可能需要操作的是十亿百亿规模的数据,这时候要迁移它们当中百分之七八十的数据,复杂度和危险性都是非常高的。
有一种方法能够减小数据迁移的规模,就是成倍扩容,例如示例中的3个片我们直接扩容成6个片,这样可以将数据迁移的规模减小到50%,如果读者阅读过HashMap的源码,会发现,HashMap在扩容时调用的resize方法就是将容量扩容为原来的2倍,笔者当时在阅读HashMap源码时就没搞懂为什么一定要扩容两倍,原因就是在这了,就是为了减少数据迁移的规模。
但是这种方式又会引入另外两个问题,一个是资源浪费,可能我们的业务发展和体量暂时不需要扩容一倍,所以直接扩容一倍之后会造成一定的资源浪费。另一个是成本问题,扩容意味着增加服务器,成倍扩容无疑意味着需要更多的服务器,成本还是很高的。这两个问题在大规模集群中尤为明显。
一致性哈希
下面我们来看一致性哈希是如何解决这些问题的,首先我们来看网上经常能看到的有关一致性哈希的一张图:
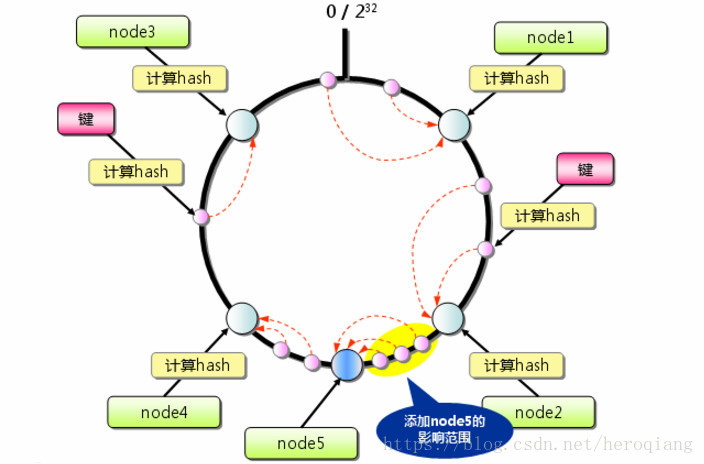
刚开始看到这张图的时候,一脸懵逼,这TM是个什么东西,大圈套小圈的,长的跟生物中的病毒一样,很不理解,我们先来看一段伪代码然后再回来理解这张图,就很容易理解了:
idmod = id % 100;
if (idmod >= 0 && idmod < 25) {
return db1;
} else if (idmod >= 25 && idmod < 50) {
return db2;
} else if (idmod >= 50 && idmod < 75) {
return db3;
} else {
return db4;
}我们用id % 100的结果作为分片的依据,并将集群分为四个片,每个片对应一段区间,这时,假如我们发现db3对应的区间也就是idmod在50-75之间的数据发生了热点情况,我们需要对这个片进行扩容,那我们可以将算法改造成这样:
idmod = id % 100;
if (idmod >= 0 && idmod < 25) {
return db1;
} else if (idmod >= 25 && idmod < 50) {
return db2;
} else if (idmod >= 50 && idmod < 65) {
return db3;
} else if (idmod >= 65 && idmod < 75) {
return db5;
} else {
return db4;
}我们扩容了一个分片db5,并将原来的热点分片db3中的一部分区间中的数据迁移到db5中,这样就可以在不影响其他分片的情况下完成数据迁移,扩容的节点数量也可以进行控制,这就是一致性哈希。
我们再回头看一下上面这样图,大概的意思就是这样,原本有四个节点node1-node4,图中粉色的点就是我们id取模之后的值落到这个环上的位置,这就是所谓的哈希环,然后扩容了一个蓝色的节点node5,扩容只会影响原来node2-node4之间的数据。
一致性哈希也同样有它的问题所在,我们上面提到,一致性哈希可以解决热点问题,那如果我们的数据分布的很均匀,没有热点问题,还是需要扩容,怎么办,按照上文的理解就需要为每个节点都扩容一个节点,这不又是成倍的扩容了么,又遇到了这个n -> 2n的问题,该怎么解决呢?
虚拟节点
我们来做这样一个映射,首先将id % 65536,这样可以得到0-65535这样一个区间,然后做一个这样的映射:
| hash id | node id |
|---|---|
| 0 | 0 |
| 1 | 1 |
| 2 | 2 |
| 3 | 3 |
| 4 | 0 |
| 5 | 1 |
| … | … |
| 65535 | 3 |
这个时候如果我们需要扩容节点,增加一个节点node id为4,我们只需要调整这张虚拟节点的映射表,随意的按照我们的需求来调整,比如我们可以将hash id为5、6、7的数据映射到node id为4的节点上,所以虚拟节点的关键就是我们要维护好这张映射表。这里id与多少取模选择了65536,实际应用中取多少合适呢?很显然,这个值越大,分布就会越均匀,我们可以调整的空间也越大,但是实现和维护的难度也会上升,所以实际应用中到底应该取什么值还是需要结合实际业务来做出权衡。
总结
无论是哪种算法,它们要解决的问题都是尽量的减少数据迁移的规模,还有就是减少扩容的成本,那是不是说我们就一定要选择虚拟节点的这种算法呢?恰恰相反,我们推荐尽量使用的简单的方法来解决问题,不要一开始就使用复杂的方式,这样很容易产生过度设计,虚拟节点的算法虽然可以解决n -> 2n和数据迁移规模的问题,但它的缺点就是比较复杂,实现复杂,维护也复杂,所以我们推荐应用一开始尽量优先选用id取模的算法也就是n -> 2n的方式进行扩容,当集群到达一定规模之后,我们可以做一张如上的虚拟节点映射表,将原来的取模算法平滑的切换为虚拟节点算法,对应用没有任何影响,然后再按照虚拟节点的方式进行扩容,这是我们最推荐的方式。